Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is a Data Reliability Engineer – And Do You Need One?


Glen Willis
Glen is the Founding Solutions Architect at Monte Carlo. Previously, he was a solutions architect at Mixpanel. He graduated from U.S.C. with a B.S. and an M.S. in Product Development Engineering.

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
As data teams continue to specialize, a new role has emerged: the data reliability engineer. But what is it and does your team even need one?
As software systems became increasingly complex in the late 2000s, merging development and operations (DevOps) was a no-brainer.
One half software engineer, one half operations admin, the DevOps professional is tasked with bridging the gap between building performant systems and making them secure, scalable, and accessible. It wasn’t an easy job, but someone had to do it.
And as DevOps became more popular and widespread, the once nascent field started specializing yet again. Soon, site reliability engineers, infrastructure engineers, and security engineers came onto the scene, bringing additional layers of expertise to software development that allowed companies to move fast, break (many) things, and still build more reliable and scalable applications.
Data and analytics is at a similar crossroads: once an emergent profession, data analytics, and more recently, data engineering, are now part and parcel of most technical organizations serious about using data well.
The “decade of data” gave way to another specialization: the analytics engineer. Part analyst, part data engineer, the analytics engineer is responsible for aligning processes, frameworks, and technologies with the data needs of business stakeholders.
These trends suggest a truth universally acknowledged among technical professionals: when a subset of a field starts to consume so much time, energy, and resources, it becomes more efficient and effective for organizations and individuals to specialize.
So, what’s forecast to be the next major data specialization? The data reliability engineer. Here’s why and whether or not it makes sense for your team to invest in one.
In this article, we will cover:
- What is a data reliability engineer?
- What does a data reliability engineer do?
- Example data reliability engineer job descriptions
- Top data reliability engineer interview questions
- How do you apply the data reliability life cycle?
- How do data reliability engineers measure success?
- What does the future have in store for data reliability engineering?
Let’s get started.
What is a data reliability engineer?
Over the last few years with the rise of cloud data warehouses and lakes like Snowflake, Redshift, and Databricks, data pipelines have become increasingly distributed and complex, with companies ingesting more operational and third-party data than ever before. As more stakeholders interact with data throughout its lifecycle, ensuring high data quality has risen to the forefront of a data team’s list of basic needs.
Still, data reliability is easier aspired to than achieved. After all, data can break for millions of reasons, from operational issues to unforeseen code changes. And in 2021 alone, Gartner suggests, the cost of poor data quality reached upwards of $12.9 million per year. And this doesn’t even account for lost opportunity cost.
After talking with hundreds of teams over the last few years, we found that data engineers and data scientists spend at least 30% of their time tackling data quality issues.
This heightened need for trust has led to the emergence of a subcategory of data engineering across data teams called data reliability engineering.
The data reliability engineer is responsible for helping an organization deliver high data availability and quality throughout the entire data life cycle from ingestion to end products: dashboards, machine learning models, and production datasets.
As a result, data reliability engineers often apply best practices from DevOps and site reliability engineering such as continuous monitoring, setting SLAs, incident management, and observability to data systems.
What does a data reliability engineer do?
It’s still early days for this nascent field, but companies like DoorDash, Disney Streaming Services, and Equifax are already starting to hire for data reliability engineers.
The most important job for a data reliability engineer is to ensure high-quality data is readily available across the organization and trustworthy at all times.
When broken data pipelines strike (because they will at one point or another), data reliability engineers should be the first to discover data quality issues, although that’s not always the case. All too often, bad data is first discovered downstream in dashboards and reports instead of in the pipeline – or even before. Since data is rarely ever in its ideal, perfectly reliable state, the data reliability engineer is more often tasked with putting the tooling (like data observability platforms and data testing) and processes (like CI/CD) in place to ensure that when issues happen, they’re quickly resolved and impact is conveyed to those who need to know.
Much like site reliability engineers are a natural extension of the software engineering team, data reliability engineers are an extension of the data and analytics team.
Many data reliability engineers have a strong background in data engineering, data science, or even data analysis. The role requires a strong understanding of complex data systems, computer programming languages, and frameworks such as dbt, Airflow, Java, Python, and SQL.
Data reliability engineers should also have experience working with popular cloud systems such as AWS, GCP, Snowflake, or Databricks and understand industry best practices for scaling data platforms.
Example data reliability engineer job descriptions
There are three common types of data reliability engineering job titles denoting different levels of seniority.
Typically, data reliability engineers have 3+ years of experience in data engineering and have a general understanding of the overall data ecosystem.
Senior data reliability engineers often have 5-7+ years of experience and a strong knowledge of data engineering best practices, and can own tasks from ideation to completion. Senior data reliability engineers are often responsible for developing the strategy around building systems, processes, and workflows across distributed data teams and relevant stakeholders.
Data reliability engineering managers tend to have over a decade of experience and have been data engineers for at least 3-5+ years. Managers are responsible for growing, scaling, and hiring the data reliability engineering time while keeping the standard high for designing and building more secure and scalable data systems.
(Of course, take these tenure recommendations with a grain of salt. We’ve worked with great data engineering leaders with far less time in the seat, and experience in tangential fields).
While the primary responsibility for data reliability engineers is to ensure your organization has high-quality data and minimize data downtime, there are additional responsibilities. Here are three data reliability engineer job descriptions we’ve found that effectively describe the position.
At DoorDash, the 6,000 person food delivery company, a data reliability engineer is responsible for:

- Developing and implementing new technologies to ensure ongoing improvement of data reliability and data observability.
- Defining business rules that determine data quality, assisting in writing tests that validate business rules, and performing rigorous testing to ensure data quality.
- Working closely with application, data platform, and data engineering teams to reconfigure data ingestion pipelines to be more reliable and continuously monitored.
- Manage data incidents and drive blameless post mortems with cross-functional teams.
For Disney Streaming Services, the 2,600 employee entertainment powerhouse, a data reliability engineering manager is responsible for:

- Leading a team of data reliability engineers that focus exclusively on tackling end-to-end reliability improvements.
- Own the incident management process to ensure that incidents are resolved quickly, and the root cause analysis is performed and understood to prevent repeat occurrences.
- Aid the team in delivering an outstanding service to their users, making the company more data-driven.
For Equifax, a global, publicly-traded credit risk assessment company, a senior data reliability engineer is responsible for:

- Monitoring the performance and reliability of the data storage and data analytics systems, making recommendations for improving performance and reliability.
- Maintaining infrastructure reliability for data pipelines and other big data processing systems.
- Focused primarily on the upkeep of databases, data pipelines, deployments, and availability of these systems.
Top data reliability engineer interview questions

Hiring a data reliability engineer is not an easy task. Especially if this is your first time hiring and or applying for the role, you may not have a general understanding of what questions to ask or expect to answer.
Here are some common questions data reliability engineers often have to answer when interviewing for the role:
- Which programming languages are you most comfortable working with?
- What’s the most important responsibility for a data reliability engineer?
- How do you communicate with cross-functional teams in an organization?
- What are the differences between service-level agreements (SLAs) and service-level objectives (SLOs)?
- How can an organization improve its observability?
- Can you walk me through an example of when you identified a previously undetected data quality issue and how you communicated impact?
- How would you set up an incident management workflow?
- How do you communicate and measure the impact of data quality with the tools in your stack?
As part of the interview process, expect some amount of leet coding or application design problems, too. You might even be asked to work with a dummy environment that incorporates tools in your future employer’s data stack, like Airflow or dbt.
How do you apply the data reliability life cycle?
As mentioned earlier, data reliability engineers are responsible for managing the processes, technologies, and workflows that help make data platforms more scalable and operational.
In fact, many data teams are taking a page from the DevOps lifecycle to data and leveraging an adapted process called the data reliability life cycle to manage the availability of reliable data.
The data reliability lifecycle is an organization-wide approach to continuously and proactively improving data health and eliminating data quality issues by applying best practices of DevOps to data pipelines.
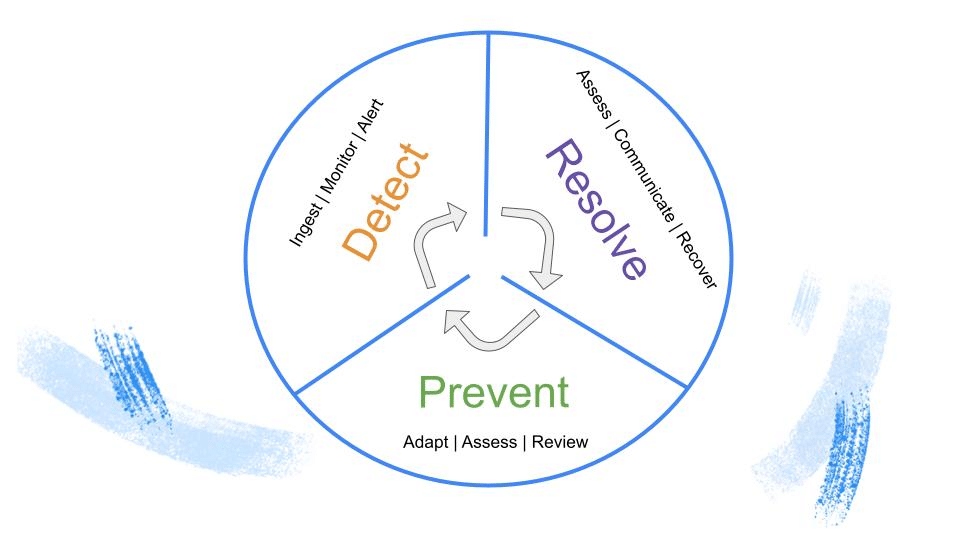
By applying this framework to data pipelines, data reliability engineers can be the first ones to uncover data quality issues, fully understand the impact, know where exactly the data broke in the pipeline, take action, and collect learnings to prevent future similar issues.
Here are the three main stages of this critical approach:
Detect: Data reliability engineers rely on automated monitoring and alerting for freshness, volume, schema, lineage, and distribution data issues. With automated alerting, your team will be able to move faster and work efficiently when data incidents do arise.
Resolve: During this step, data reliability engineers should communicate with downstream stakeholders that there is a potential problem with the data, and they are working at solving the issue. Ideally, there might be a central channel in either Slack, Microsoft Teams, or even a dedicated web page that users can follow along for updates.
Prevent: In this stage, data reliability engineers process their learnings and rely on historical data from their data pipelines, translating them into actionable steps to move forward. Essentially, data reliability engineers give proper context to changes that occurred and whether they were intentional.
For example, an e-commerce company likely sees an increase in sales over the holiday season; thus, a table in your data warehouse containing daily sales that update every 12 hours will increase. But at the same time, accidental schema changes do occur, and a table that was daily_sales accidentally became daily_sale when an engineer pushed an update to production is something that should be flagged.
Over time as you grow your data reliability team and evolve your data stack, your tests and monitors should automatically adjust and update, matching business requirements and ultimately reducing broken data pipelines. Machine learning-enabled tools like data observability platforms can help.
How do data reliability engineers measure success?
There is a saying amongst our SRE counterparts that goes “If you can’t measure it you can’t manage it.” And, as data systems continue to evolve in complexity and grow in importance to organizations we can apply the same saying to data reliability engineers.
It’s no secret how important it is for businesses to have reliable data at all times. To measure the success of your data reliability engineering efforts, we recommend you measure the following KPIs: data trust, data adoption, as well as Time-to-Detection (TTD) and Time-to-Resolution (TTR) for data quality issues.
Data trust and adoption
One of the best signs for a data reliability engineer is to see an increase in data adoption across the board. It is likely that if stakeholders are using data for decision-making, they trust the quality of data that is readily available to them.
It is crucial that you align with stakeholders early on and agree on baseline metrics for measuring data quality across the company since this is often a subjective measurement and will vary depending on the team using the data.
Once you define what high-quality data looks like across different departments, you’ll have a better understanding of how to measure it and can check in with stakeholders periodically to align on your teams’ data quality initiatives. In the past, I have seen data teams send out quarterly surveys to business stakeholders, asking them to rate the quality of data available to them, or leverage an operational analytics platform that monitors which data sets are used, which teams are using the most data, and whether or not data storage is being optimized to best manage platform costs. Some data engineers even use metrics like number of data quality tests, most “active” data quality monitors, and other observability-focused statistics that inform whether or not governance and data quality processes are actually working.
Data downtime
Data trust is another critical “KPI” for data reliability engineers, but how do you actually measure it? For any company striving to be data-driven, measuring data downtime is essential.
Data downtime refers to periods of time when data is broken, missing, or otherwise erroneous, and consumers upwards of 40 percent of a data engineer’s time, and in many ways, is the most accurate measurement of a data reliability engineer’s impact.
Data downtime consists of three components:
- Number of data incidents (N) – Given that you rely on data sources that are “external” to your team, this one is always not in your control; however, it is undoubtedly a driver of data uptime. A data incident refers to a case where a data product (e.g., a Looker dashboard) is inaccurate, which could be for various reasons.
- Time-to-detection (TTD) – When an incident happens, how quickly is your team made aware? If there are no proper methods for detection in place, silent errors from bad data results can result in costly decisions for both your company and customers.
- Time-to-resolution (TTR) – When an incident occurs, how quickly can your team resolve the issue? Ideally, this number should be as low as possible, and automated tooling for lineage makes tracing upstream and downstream dependencies easier.
To measure data downtime, we recommend the below KPI:
Data downtime = Number of data incidents
X
(Time-to-Detection + Time-to-Resolution)
By measuring data downtime, your team can determine the reliability of your data to see if they can use it for analytics, ML, and other production use cases, or if data needs to be further processed and cleaned.
Data SLAs
Creating service-level agreements (SLAs) for data quality allows data reliability engineers to better define and, most importantly, measure the level of service they provide the rest of the organization.
SLAs will help data reliability engineers align with the rest of the organization on what matters the most about their data and should help prioritize incoming requests. They should also include service-level indicators (SLIs) and agreed-upon service-level objectives (SLOs).
Take Red Ventures, for example – one of their subsidiary companies, Red Digital, relies on AI-driven digital marketing, top-of-the-line analytics, and data from their content network to help their clients attract and acquire the most valuable customers. As a result, the advertising agency needs data to be on time and accurate before it impacts revenue.
Brandon Beidel, a Senior Data Scientist at Red Ventures, meets with every business team weekly to discuss how the team uses data and how the quality of data has impacted their work.
Beidel found it was best to frame the conversation in simple business terms and focus on the “who, what, where, when, why, and how” for data.
He found the template below that he created to be helpful when having SLA conversations with business stakeholders.

Having a simple structure in place for data SLAs allowed his team to evolve in meeting the requirements that different teams had for the data without becoming overwhelmed by requests.
What does the future have in store for data reliability engineering?
LinkedIn reported earlier this year that the site reliability engineer was one of the fastest-growing positions of the past five years; similarly, Business Insider reported that data scientists were the second most popular job of 2022. Clearly, the demand for insights and reliability have never been higher.
Increasingly, data engineers and analysts are being tasked with ensuring the reliability and quality of their data systems. And as stacks grow more complex and data needs increase, companies will start to embrace new (and battle-tested) technologies, processes, and cultures to keep pace.
Will the data reliability engineer follow? Only time will tell.
But we know where we’re placing our bets.
Interested in learning more about data reliability engineering? Reach out to Glen, Lior, and book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.