 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Who Is Responsible For Data Quality? 5 Different Answers From Real Data Teams

Shane Murray
Shane is Field CTO of Monte Carlo. Previously, he served as the SVP of Data & Insights at The New York Times.
Sure, data quality is everyones’ problem. But who is responsible for data quality?
Given the variations in approach and mixed success, we have a lot of natural experiments from which to learn.
Some organizations will attempt to diffuse the responsibility widely across data stewards, data owners, data engineering and governance committees, each owning a fraction of the data value chain. Others concentrate the responsibility across only a few specialists who are expected to span across the entire platform. Some teams view data quality mainly as a technical challenge while others look at it as a business or process problem.
I have spoken to dozens of data leaders in the past year to understand how they approach data quality as part of their overall organizational goals. We also surveyed 200 data professionals to ask, among other things, who is responsible for data quality.
This post will focus on the most common team ownership models including: data engineering, data reliability engineering, analytics engineering, data quality analysts, and data governance teams.
Table of Contents
Why is important to answer who is responsible for data quality?

But before we dive in, it’s important to answer this frequently asked follow up question. It’s typically posed in a version of, “Why does it matter who is responsible for data quality as long as it gets done?”
There is a bit of sophistry in the phrasing since “as long as it gets done” is far from certain and frankly the whole purpose of the exercise. There are so many studies on the positive impacts of clear accountability, ownership, and goal setting that it is hard to cite just one.
The reality is that addressing data quality is unlikely to be the initiative that teams want to prioritize ahead of building shiny new products or services, but it’s often the one that they need to prioritize in order to maintain trust or scale their team and platform. And without accountability, the lower visibility tasks that advance data quality, such as unit tests or documentation, simply won’t get done to the degree they should.
Further, when responsibility is diffuse you typically wind up with fragmented solutions, uncoordinated priorities and communication gaps, ultimately leading to more downtime for your data products.
While I’ve seen all types of teams successfully implement solutions for data quality, each ownership structure has unique advantages to be leveraged and disadvantages to be mitigated.
Data leaders need to understand how each team and capability fits together. It doesn’t make sense to have a blazing fast point guard who likes to run in transition if you are also starting a lumbering center. The whole needs to be greater than the sum of its parts.
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures.
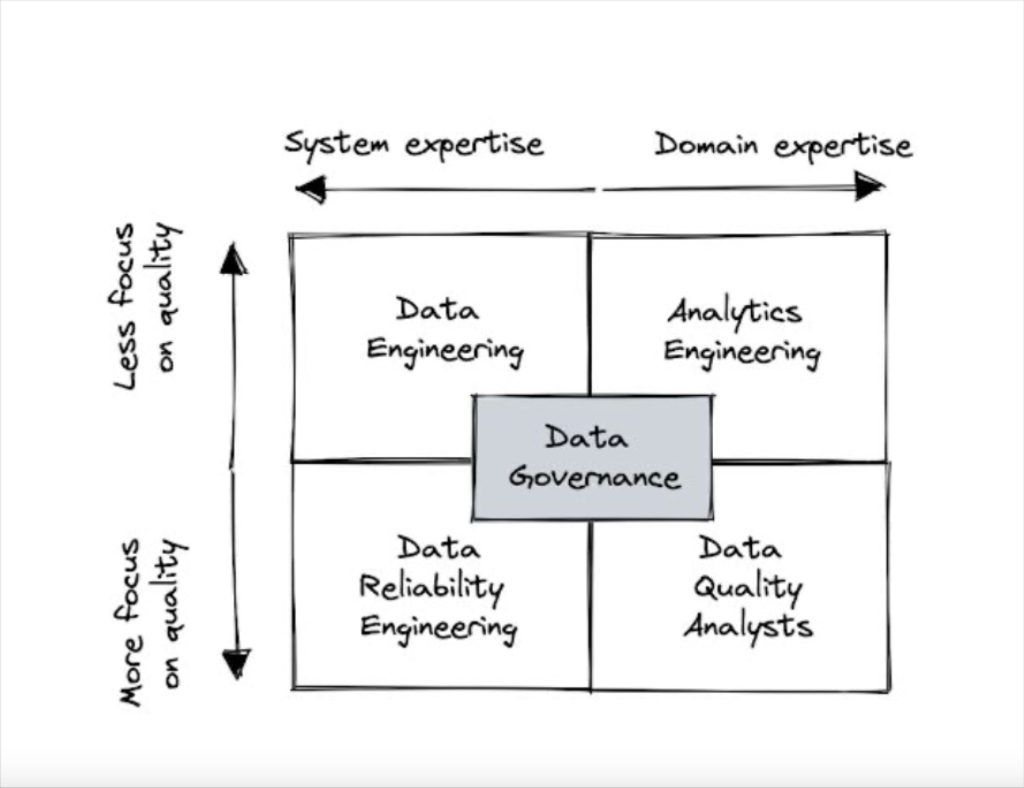
Data engineering
Having the data engineering team lead the response to data quality is by far the most common pattern. It is deployed by about half of all organizations that use a modern data stack.
Typically, it is accompanied by a “you built the pipeline, you own it” mentality.
The strength of this approach is accountability rests with highly technical, system thinkers who are well equipped to solve system-wide problems, affecting infrastructure, code or data.
Data engineers work upstream in the systems that have a large impact on data quality. If an Airflow job, dbt model, or Fivetran sync fails, they will likely be the first to detect the issue and, with features like data lineage, can be empowered to understand the downstream blast radius to triage appropriately.
There are downsides to this approach however. For one, data engineers are often in short supply and so focused on systems and pipelines that they don’t always have as deep domain knowledge of the data. For example, they may know a dataset originates in Salesforce and the dynamics of the pipeline that land the data in the data warehouse, but they might not know the client_currency_exchange_rate field within that dataset can never be negative.
And while it is efficient to have the pipeline builder and maintainer be the same person, this can also create silos of tribal knowledge that can be lost when people leave and others attempt to onboard.
Effective approaches to mitigate these challenges can be to emphasize the importance of documentation to ensure knowledge transfer and to embed teams, or pair engineers with embedded analysts, to better source domain knowledge.
BlaBlaCar is an example of an organization where data engineering owns data quality. They experienced bottlenecks and challenges around capacity until they transitioned to a data mesh and leveraged data observability to reduce the amount of time required to conduct root cause analysis.
Analytics engineering
Analytics engineering teams often boast a blend of technical expertise with deep domain knowledge, making them effective leaders on data quality.
They are frequently deployed as a way to scale data transformation and access across an organization, often using dbt or similar, while the centralized data engineering team focuses on infrastructure, enterprise data management or shared services.
The strength of this approach is the strong domain expertise of a typical analytics engineer. They are well-positioned to navigate both pipeline reliability and field-level quality.
The downside may be limitations in their capacity to solve infrastructure problems or coordinate with upstream data-producing teams and systems. Only a fraction of data quality problems originate in the transformation layer, so the analytics engineers will require strong partnerships with product and platform engineering teams, to effectively triage issues in the source systems and ingestion layer respectively.
Upside’s analytical engineering team has effectively owned data quality in their organization by positioning themselves as a center of excellence across different teams.
“Our analytics engineers are supposed to be accelerants, not necessarily domain experts. So we position them in the middle of all of these different specialized teams. This allows them to become a center of excellence and then be able to embed with those teams to acquire the cross-functional expertise,” said Jack.
The analytical engineering team found their data quality initiative became much more sustainable when they built custom data pipeline monitors and trained alongside the systems health team. By incorporating the systems health team into the design and creation process, they achieved buy-in and enabled the system health team to set up monitors that have created meaningful insights.
Data governance
Data governance teams often take the lead on data quality alongside the larger mandate of data security, privacy and access.
The strength is in establishing a comprehensive strategy that considers the entire value chain of data, influencing the behavior of data producers, engineers and data consumers. Often we see governance teams owning a suite of solutions for the organization that include data observability, data catalog, and access management.
Data governance teams enact change through technical standards, policies and business processes for other teams to adopt. But adoption is always more challenging when not backed by the compliance mandate of security or privacy initiatives.
At scale, it’s critical for governance teams to create the global standards for quality data, such as the minimum requirements for documentation, monitoring and SLAs, then federate accountability across the various data owners, whether they be organized into domains or data teams.
Contentsquare’s data governance team governs the access and application of data. Quality falls under their remit as well.
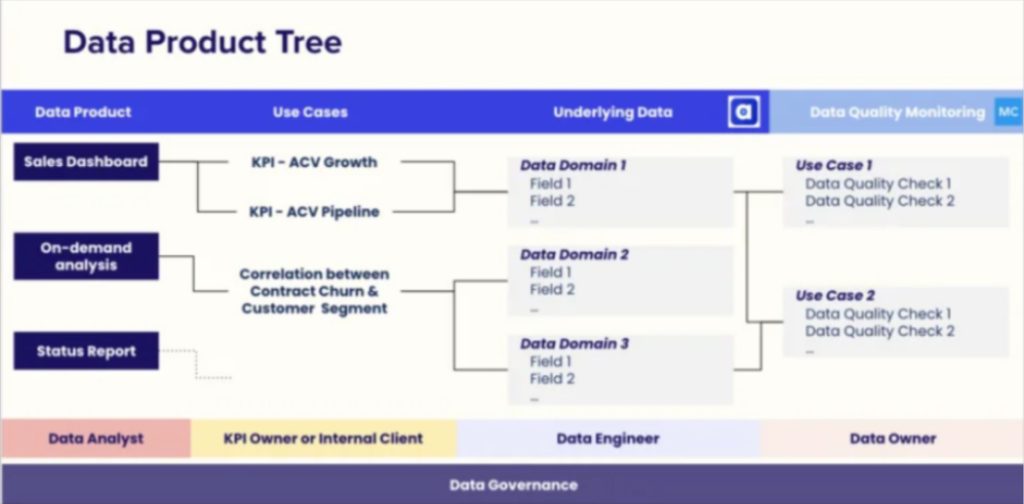
The governance team treats every team output as a data product. Each data product is linked to use cases, which are linked to underlying data. Data quality monitoring underpins all that underlying data, and the data team conducts regular checks to ensure each data product works as designed.
“Sometimes when we are going so fast, we tend to focus only on the value creation: new dashboards, new models, new correlations with new data explorations,” said their former global data governance lead. “We forget to put in place good data engineering, good data governance, and an efficient data analytics team. This is very important to make sure in the long term we are scalable, and we can do more with the same team in the future.”
Data reliability engineers
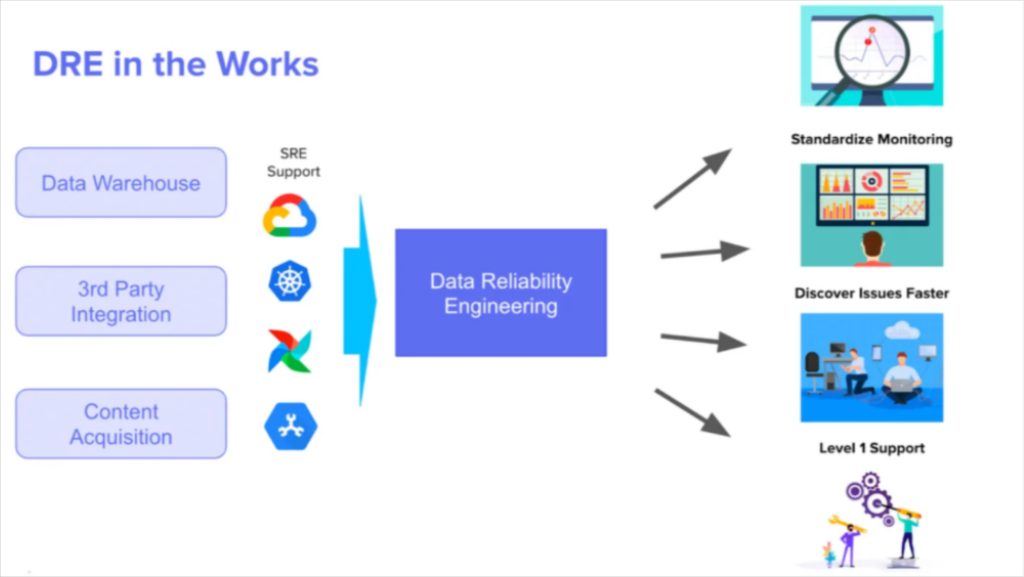
Data reliability engineering is a specialized subset of data engineering that is focused exclusively on responsive and preventive practices to increase the quality and reliability of data systems. It is not as common of a structure, but rapidly picking up steam (we mention them and the specialization of the data team as one of our top data engineering trends of 2023).
In situations where data products are externally-facing and/or strict data SLAs need to be met, a dedicated team of data reliability engineers can bring the required focus to both incident response and proactive measures to address reliability.
We’ve seen within Monte Carlo’s product telemetry that teams that leverage this approach see an improvement in operational metrics for data reliability including much higher incident status updates.
However, teams and data environments need to be sufficiently large enough to gain the appropriate efficiencies from specialization.
Mercari uses a data reliability engineering team structure. Key to their success has been setting clear goals and responsibilities such as:
- Onboarding and supporting the most important pipelines
- Modernizing data pipeline infrastructure
- Proliferating data operations and monitoring practices
- Secure access to customer data
Their focused attention has also enabled them to make smart decisions about when to resolve and make more incremental fixes versus when a larger modernization may be necessary.
Data quality analysts
Finally, some organizations, particularly larger ones, will leverage data analysts or specialized data quality analysts.
The strength of this structure is these analysts are usually very close to the business and well positioned to define the required quality standards, and develop tailored tests or monitors to enforce those standards.
However, these teams often require a strong connection to data engineering in order to effectively be able to triage and troubleshoot issues upstream.
PayJoy is an example of an organization where data analysts and head of analytics, Trish Pham, have successfully owned data quality. They have over 2,000 tables and leverage data primarily to increase their visibility into business performance and enable data-driven decisions across functions.
“PayJoy uses data all across our business groups,” said Trish. “Go-to-market team, our risk strategy team, marketing team… basically every group that you can think of!”
As long as it gets done
Whomever your organization and data team decide to lead the response to data quality, it’s important for it to be clear who is responsible for data quality.
Start by assessing the operational, analytical, and customer facing data use cases and required data reliability levels. Then, within these critical use cases, identify the team with the most leverage over the data value chain – they should be able to own both responsive and preventative solutions, and require influence with both data producers and consumers.
This isn’t a solo project. The more you can enable the team and facilitate cross department collaboration, the more likely you are to be successful.
Curious how data observability can help your team better understand who is responsible for data quality? Or how to create more accountability? Select a time to talk with us by filling out the form below.
Our promise: we will show you the product.
Read more posts.





