Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Mercari Operationalizes Data Reliability Engineering at Scale

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Software applications achieve an enviable degree of reliability, and for some of the highest performing organizations, downtimes consist of a handful of minutes.
This success is driven by technological innovations such as application performance management solutions, evolving best practices such as DevOps, and specialized roles such as site reliability engineers (SREs).
Many of these structures have been adopted and adapted by data engineering teams in their eternal quest to build more reliable data systems. In fact, our CEO Barr Moses predicted the specialization of data roles–and the formation of data reliability engineering teams in particular–to be one of the hottest data engineering trends of 2023.
In this regard, Mercari is ahead of the curve. The e-commerce marketplace that was built for the everyday shopper and casual seller, treats data with the highest priority given its crucial role in maintaining trusted relationships with both buyers and sellers.
“Buyers trust us with their financial information and sellers rely on our platform for their income. Data reliability is important for us to meet those commitments as well as financial regulations,” said Dan Lameyer, a member of the Mercari DRE team.
Mercari’s data reliability engineering team was established in June of last year, and has quickly scaled to three members.
“I started as a machine learning engineer, and I think having the perspective of a data consumer has helped me think about how to approach reliability. I realized without data quality or reliable pipelines it is difficult for us to unlock the full value of data,” said Hatone Ohsima, an early member of the team. “I started assuming more data engineering responsibilities and we saw the need for a role similar to a site reliability engineer. We were particularly influenced by Google’s SRE handbook as well as data certification, data product, and data SLA methodologies.”
Here are six key best practices they have learned along their journey.
#1. Clear goals are essential to specialization
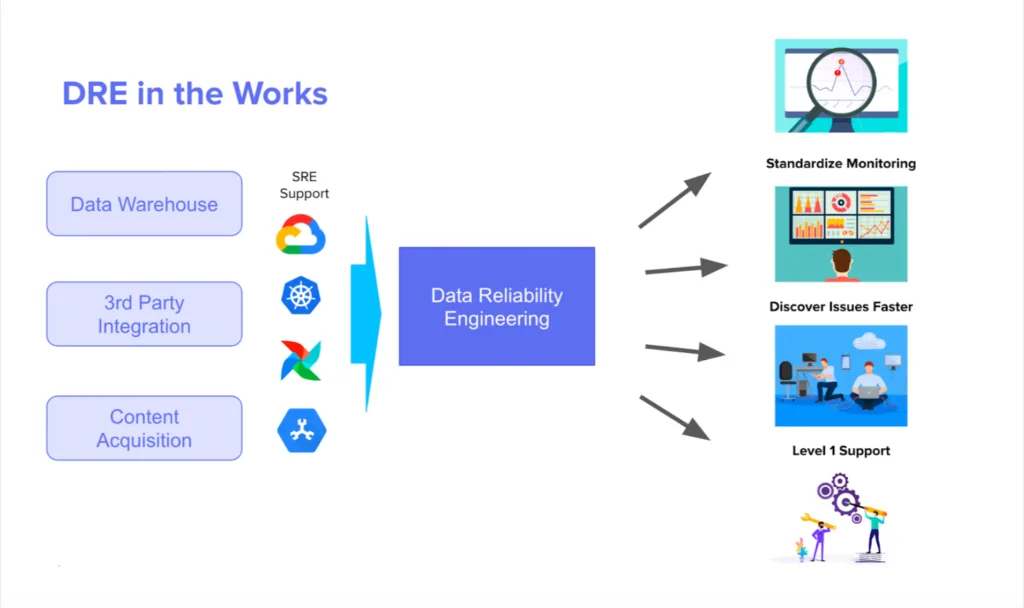
A data reliability engineering team can enable other data teams to focus on business alignment and producing new features, but only when there is a clear division of responsibility. The Mercari data reliability engineering team was established with the following goals:
- Onboard and Establish Level 1 Support for Data Pipelines
- Modernize Data Pipeline Infrastructure
- Proliferate Data Operations, and Monitoring Practices
- Secure access to Customer Data
“Data engineers need to understand the code and logic to build pipelines that the business needs, but when an organization is growing fast it can become hard to manage the infrastructure at scale,” said Daniel.
#2. Monitor both your data pipelines and your data
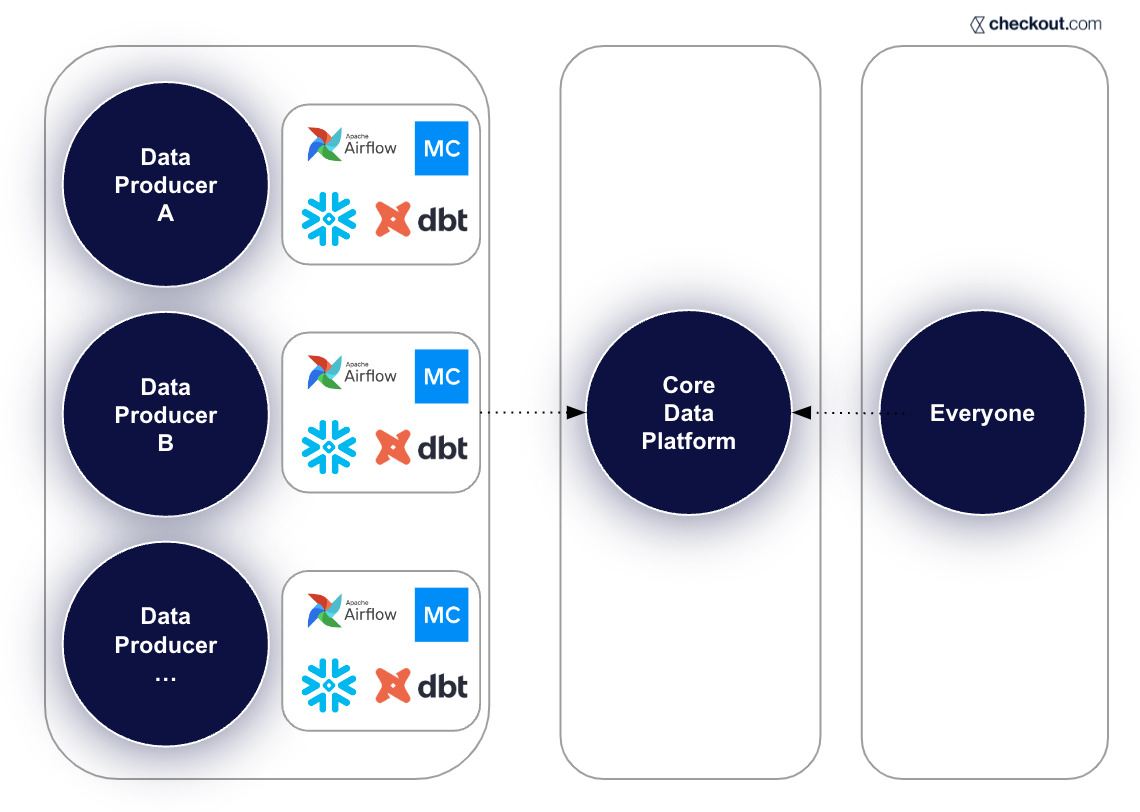
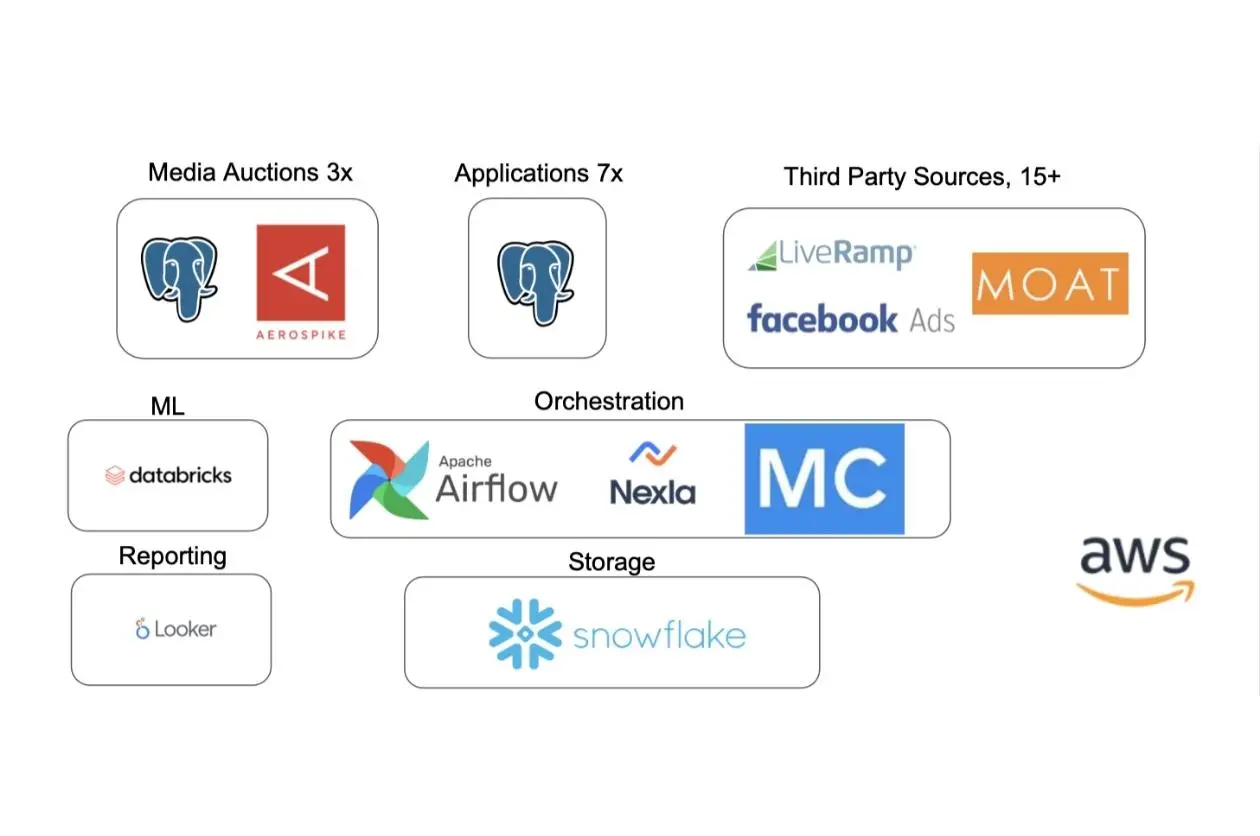
The Mercari DRE team leverages multiple tools to monitor their data infrastructure including Monte Carlo for end-to-end data observability. This layered approach has enabled Mercari to catch incidents that otherwise might have been missed.
“One of our streaming pipelines experienced a connection failure, which impacted hundreds of tables,” said Xi Zhou, Mercari data reliability engineer. “Monte Carlo caught it right away, allowing us to fix it quickly. Quick time to detection and resolution is important because it makes the process of backfilling the correct data less painful.”
The Mercari team finds Monte Carlo’s data volume, data freshness, and schema change monitors–which automatically cover every production table the moment it’s created without the need for rule or threshold setting–the most useful for maintaining a high level of data reliability. For example:
“The schema change monitor helped us in a situation where a Google query automatically transformed a data type to an integer, which would have caused problems,” said Xi. “We got the alert and took care of it before the downstream report failed.”
Since the formation of the data reliability engineering team, Mercari has created additional layers to this monitoring baseline by more than quadrupling (4X) the number of custom monitors placed on their most critical data pipelines. They create these custom monitors using both the Monte Carlo UI as well as monitors as code.

“We like placing Monte Carlo field health monitors on user tables and particularly userID fields,” said Hatone. “If we see NULL rates on those fields jump from 2% to 30%, we can help the team quickly find an application bug and backfill the data.”
“We have giant tables of datasets logging how customers are using our app and we want to know if an update happens or if there are sudden usage changes,” said Daniel. “We use field health monitors, SQL rules, and different filters to take a very granular look at these activities.”
#3 Empower your on-call engineers with documentation
The 3-person Mercari data reliability engineering team regularly rotates through a one-week on-call schedule. It is the job of the on-call engineer to check and triage all data incidents and alerts coming from Monte Carlo.
While alerts are routed to the appropriate domain teams, such as marketing or accounting, the on-call engineer ensures nothing is overlooked.
“During one of our post-mortems we learned alerts were getting missed because not every domain team had as rigorous a process for tracking alerts, even if they found them informative,” said Daniel. “We now have a dedicated Slack channel and a daily stand up to review all alerts. Now, we are able to more efficiently; get information on the alerts that need to be acted upon, notify the appropriate people, and document what occurred.”
Prior to implementing this process, data incidents had their status updated about 10% of the time. The number is now close to 100% .
While Monte Carlo provides the ability to easily include vital context to each table such as a history of incidents, owners, and lineage, the Mercari team also includes much of this information in a document attached to each Slack channel receiving alerts so it can be widely accessed as needed.
#4 Adjust your signal to noise ratio
When the Mercari data reliability engineering team started, the scope of their mission seemed daunting.
“At first, I was overwhelmed with trying to figure out where to get started and what to get done given the sheer size of the data warehouse,” said Daniel. “Since then we’ve created a process where we are able to collaborate with each business unit to understand if different alerts are expected and how to adjust our alerting to mute incidents we don’t care about, or conversely how to set up additional monitors to get more granular.”
Continuous communication and alignment with business stakeholders has helped the team to better understand the detailed operational context of the data allowing them to mute false positive alerts with confidence. This new line of communication has also helped the DRE team understand when more specific thresholds or data SLAs might be necessary–for example if a particular executive checks a key dashboard at a specific time during the week and the data needs to be fresh.
As a result, Mercari’s pipeline monitoring alerts have gotten even more accurate over time, encouraging all stakeholders to take swift action to triage and resolve when necessary.
#5 Understand when to resolve and when to re-architect
Mercari’s data reliability engineering team takes advantage of all of Monte Carlo’s data incident resolution features including data lineage, query change detection, and high correlation insights.
“When an incident occurs, it’s helpful to see when a query has changed and who has changed it. We can reach out directly to that person rather than asking around, or get an understanding of the root cause if it’s a service account,” said Daniel.

Since the specialized team keeps such a close eye on incidents, they also have better insight into problematic pipelines or reoccurring issues. For these scenarios, it can make sense to adapt the underlying infrastructure.
“One new service we are excited about in Google Cloud is GCP Data Fusion which is a fully managed UI based data pipeline tool that natively integrates across GCP products, and enables fast ingestion of large datasets thanks to DataProc (Apache Spark) running behind the scenes,” the DRE team shared on their engineering blog.
#6 Conduct post AND pre-mortems
Post-mortems are a standard operating procedure the Mercari team executes quite well. In the next year they anticipate conducting pre-mortems, or what they call “fire drills.” This concept involves simulating a controlled/fake outage to have a playbook in place for similar events, not unlike chaos engineering.
“The idea is we’ll roleplay an alert from a particular dataset and walk through the steps for triage, root cause analysis, and communicating with the business,” said Daniel. “By seeing them in action, we can better understand the recovery plans, how we prioritize to ensure the most essential tables are recovered first, and how we communicate this with a team that spans across four time zones.”
The result? Higher levels of data trust at Mercari
Bit by bit, pipeline by pipeline, the data reliability team is changing how data is perceived at Mercari.
“Before we scaled the data reliability team and started leveraging Monte Carlo, different business teams would reach out to say, ‘this number is wrong,’” said Hatone. “Now, we catch it first. Business stakeholders can trust the data to make quick, informed decisions.”
Interested in learning more about data reliability engineering and data observability? Talk to us by picking a time from the form below.
Our promise: we will show you the product.
Read more posts.