Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 12 Data Quality Metrics That ACTUALLY Matter

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Data teams work hard to collect, track, and use data. But so often, we have no idea if the data we’re leveraging is really accurate. In fact, many companies will have excellent data pipelines, but terrible data. And if the data’s bad, it really doesn’t matter how good the pipelines are.
One of our customers posed this question related to data quality metrics:
I would like to set up an OKR for ourselves [the data team] around data availability. I’d like to establish a single data quality KPI that would summarize availability, freshness, quality. What’s the best way to do this?
I can’t tell you how much joy this request brought me. By measuring data downtime, this simple data quality KPI will help you determine the reliability of your data, giving you the confidence necessary to use it or lose it.
Table of Contents
What are data quality metrics?
Data quality metrics are the measurements data teams use to monitor and communicate the health of their data and pipelines for stakeholders. When chosen carefully—and managed properly—good data quality metrics will not only help you improve the reliability of your data assets, but it can also contribute to data trust across your organization.
Why do data quality metrics matter?
If you’re in data, you’re either working on a data quality project or you just wrapped one up. It’s just the law of bad data — there’s always more of it. By measuring data health with data quality metrics, we can understand the overall health of our pipelines, how are data quality projects are performing, and where we still have room for improvement.
Traditional methods of measuring data quality metrics are often time and resource-intensive, spanning several variables, from accuracy (a no-brainer) and completeness, to validity and timeliness (in data, there’s no such thing as being fashionably late). But the good news is there’s a better way to approach data quality metrics.
Data downtime — periods of time when your data is partial, erroneous, missing, or otherwise inaccurate — is an important data quality metric for any company striving to be data-driven.
Examples of data quality metrics
Data can go bad for all kinds of reasons. The right data quality metrics will account for the plurality of potential causes and issues related to the health of both your data and your pipelines, to give your data team a holistic understanding of what’s working and where to focus next.
Some examples include data quality metrics or KPIs that cover issues in your data, system, and code—which will likely require a modern approach to data quality management as well—as well as the processes that surround incident management.
Metrics that cover the health and performance of queries, numbers and kinds of incidents detected, and team performance are all critical metrics to measure data quality.
The most important data quality metrics
Overall, data downtime is a function of the following data quality metrics:
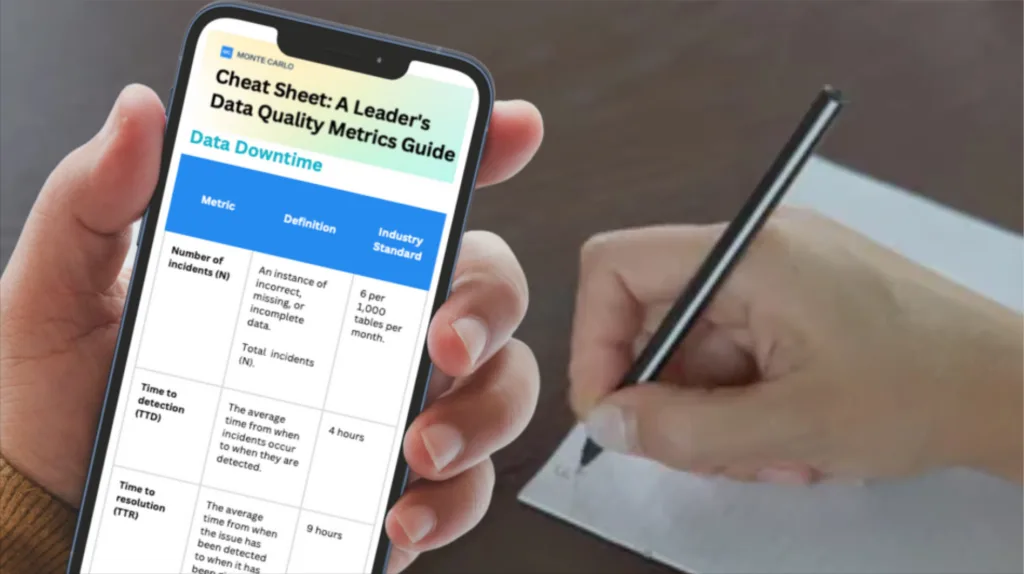
- Number of data incidents (N) — This factor is not always in your control given that you rely on data sources “external” to your team, but it’s certainly a driver of data uptime.
- Time-to-detection (TTD) — In the event of an incident, how quickly are you alerted? In extreme cases, this quantity can be measured in months if you don’t have the proper methods for detection in place. Silent errors made by bad data can result in costly decisions, with repercussions for both your company and your customers.
- Time-to-resolution (TTR) — Following a known incident, how quickly were you able to resolve it?
By this method, a data incident refers to a case where a data product (e.g., a Looker report) is “incorrect,” which could be a result of a number of root causes, including:
- All/parts of the data are not sufficiently up-to-date
- All/parts of the data are missing/duplicated
- Certain fields are missing/incorrect
Here are some examples of things that are not a data incident:
- A planned schema change that does not “break” any downstream data
- A table that stops updating as a result of an intentional change to the data system (deprecation)
Bringing this all together, I’d propose the right formula for data downtime is:

Data downtime is an effective data quality metric. It is measured by the number of data incidents multiplied by the average time to detection plus the average time to resolution.
If you want to take this data quality KPI a step further, you could also categorize incidents by severity and weight uptime by level of severity, which we have addressed in another post.
With the right combination of automation, advanced detection, and seamless resolution, you can minimize data downtime by reducing TTD and TTR. There are even ways to reduce N, which we have covered with Red Ventures data SLA story.
11 more metrics to measure data quality
Of course, if we hold that data downtime is our north star data quality KPI, then all of the data points that make up the formula are important as well. For example:
1. Total number of incidents (N)
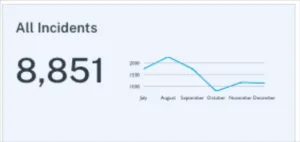
This metric measures the number of errors or anomalies across all of your data pipelines. A high number of incidents indicates areas where more resources need to be dedicated towards optimizing the data systems and processes. However, it’s important to keep in mind that depending on your level of data quality maturity, more data incidents can be a good thing. It doesn’t necessarily mean you HAVE more incidents, just that you are catching more.
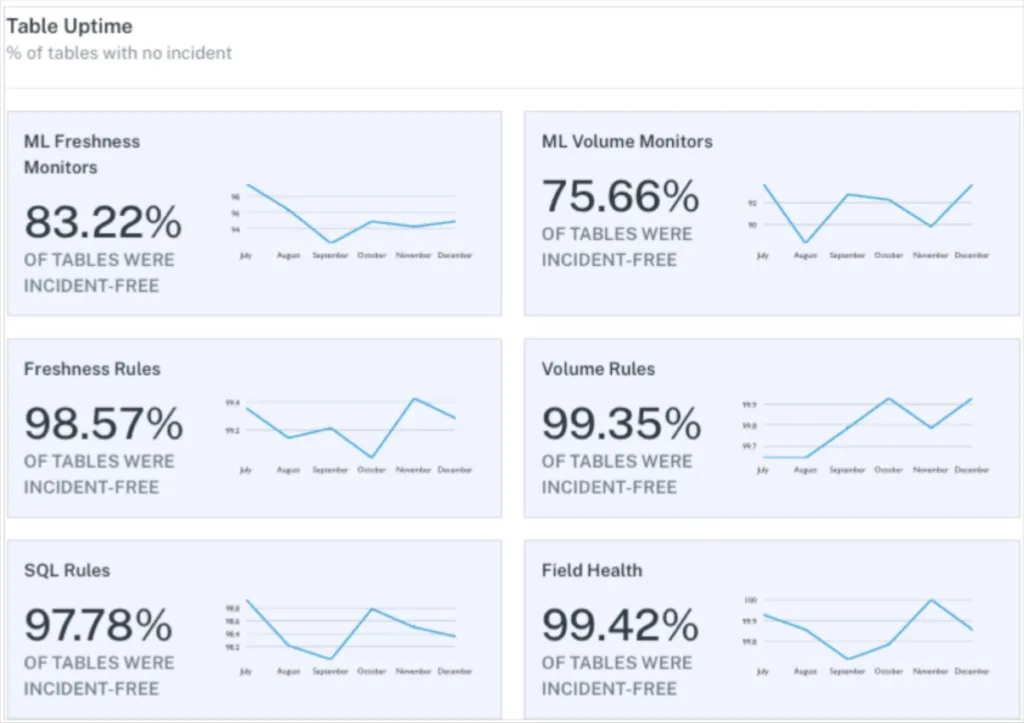
2. Table uptime
It is important to place the total number of incidents within the larger context of table uptime or the percentage of tables without an incident. This can be filtered by type of incident, by custom data freshness rules for example, to get a broad look at SLA adherence.
3. Time to response (detection)
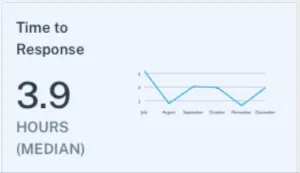
This metric measures the median time from an incident being created until a member of the data engineering team updates it with a status (which would typically be “investigating,” but could also be expected, no action needed, or false positive).
4. Time to fixed (resolution)
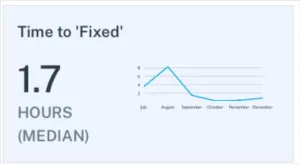
Once an incident has been given a status, we then want to understand the median time from that moment until the status is updated to fixed.
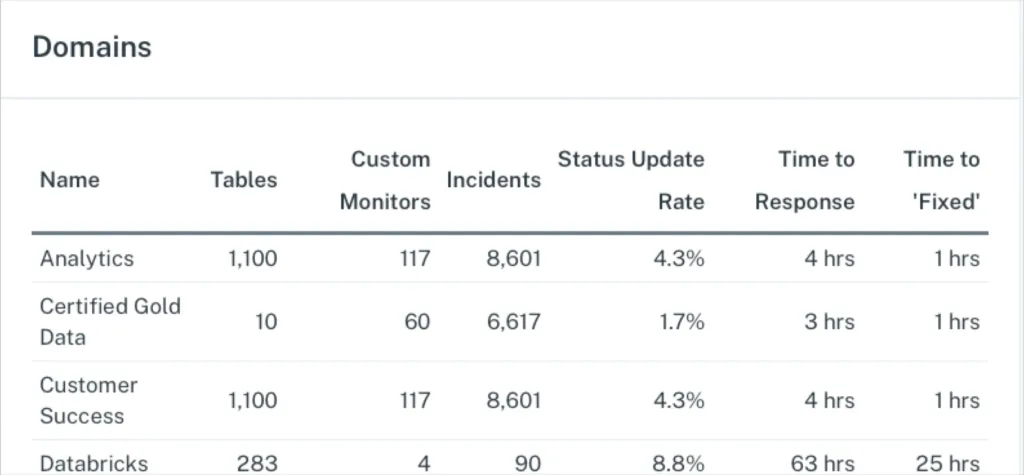
It’s important to measure the above data quality metrics by domain to understand the areas where additional optimization may be needed.
Other types of data quality metrics are important as well, including those that measure table reliability, scope of monitoring coverage, tidiness, and incident response.
5. Importance score
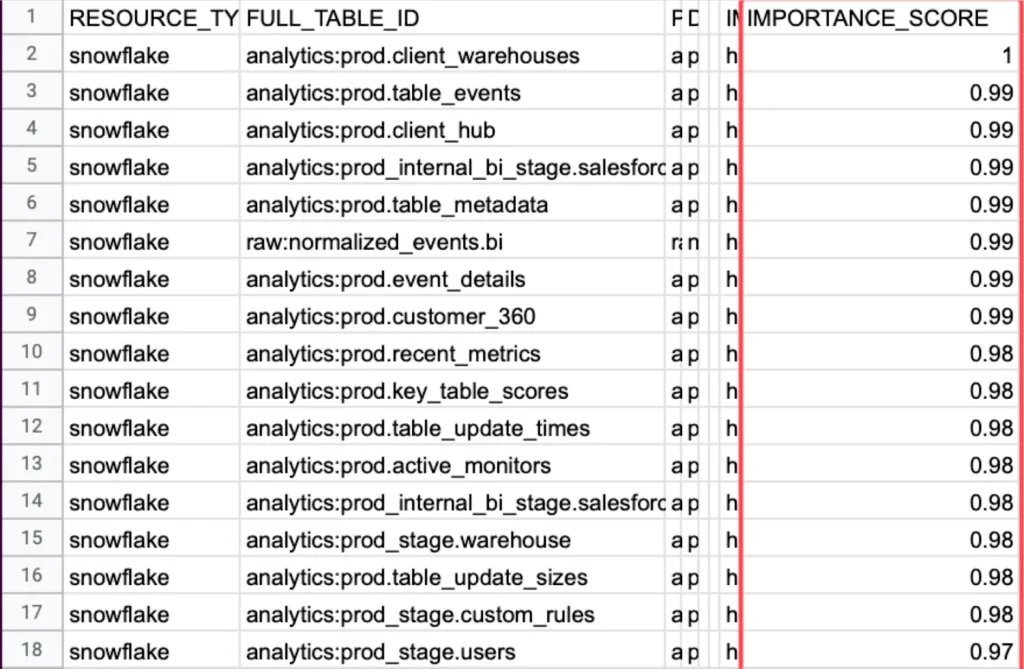
Risk is a combination of frequency and severity. You can’t understand the severity of a data incident if you don’t also understand how important the underlying table is. Importance score, measured by the number of read/writes as well as downstream consumption at the BI level, is an important part of enabling data engineers to triage their incident response. It can also indicate a natural starting place for where layering on more advanced custom monitoring, data tests, or data contracts may be appropriate.
6. Table health
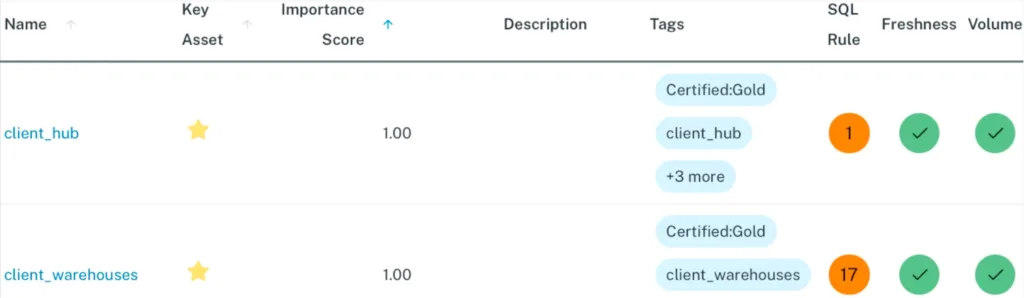
If the importance score is the severity, the table health, or number of incidents a table has experienced over a certain time period provides the frequency end of the risk equation.
7. Table coverage
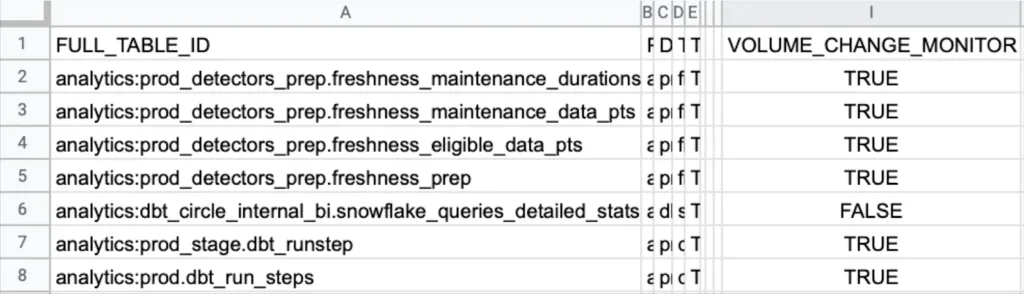
Having comprehensive coverage across as many of your production tables as possible is critical to ensuring data reliability. This is because data systems are so interdependent. Issues from one table flow into others. With a data observability platform, your coverage across data freshness, data volume, and schema change monitors should be at or near 100% (but that’s not true for all modern data quality solutions).
8. Monitors created
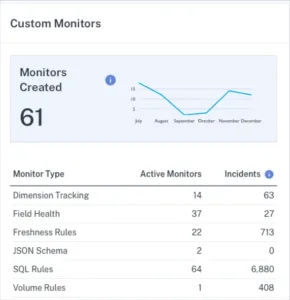
Table coverage helps you ensure you have a broad base of coverage across as many of your production tables as possible. Data engineering teams can get additional coverage by creating custom monitors on key tables or fields. It is important to understand the number of incidents being created by each custom monitor type to avoid alert fatigue.
Now let’s look at, for lack of a better word, “tidiness” data quality metrics. Tracking and understanding these metrics can help you reduce incidents related to poor organization, usability, and overall management.
9. Number of unused tables and dashboards
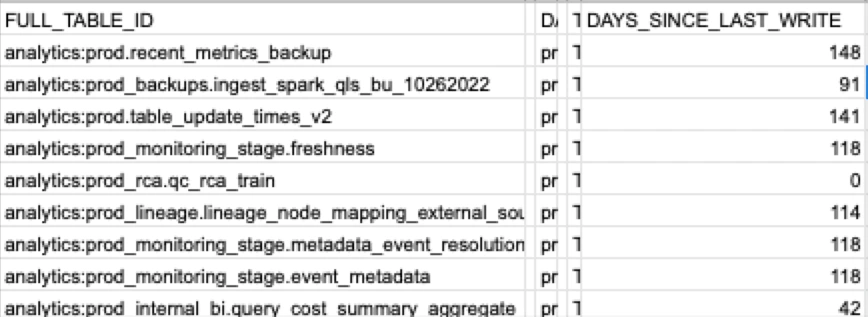
It can take some guts to deprecate tables and dashboards. Because it’s easier to just leave them lying around, unused tables and dashboards quickly accumulate. This can make it hard to find data, or worse, your stakeholders might end up leveraging the wrong table or dashboard resulting in two sources of truth (one of which was meant to be retired).
10. Deteriorating queries
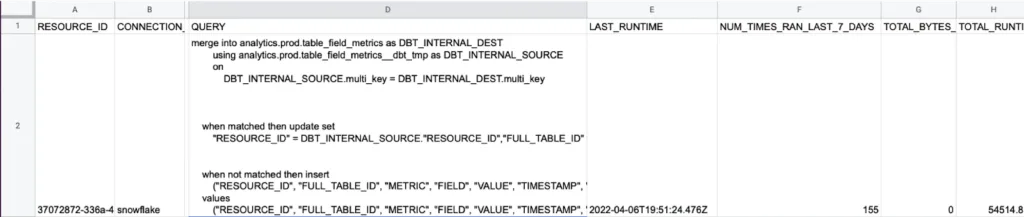
Measured as queries displaying a consistent increase in execution runtime over the past 30 days. It is important to catch these deteriorating queries before they become failed queries and a data incident.
11. Status update rate
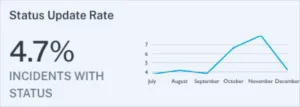
It’s not enough to simply detect data quality incidents. They also need to be managed. A low incident response rate can indicate alert fatigue or even an operational deficiency. Either way, low status update rates suggest that your data team may want to take a second look at your alerting strategy, your internal culture surrounding data quality, or both.
The better your team is at updating the status of incidents, the better your incident response will be.
Focusing on the data quality metrics that matter
Tracking key data quality metrics is the first step in understanding data quality, and from there, ensuring data reliability. With fancy algorithms and data quality KPIs flying all over the place, it’s easy to overcomplicate how to measure data quality.
Sometimes it’s best to focus on what matters. But to do that, you need the systems and processes in place to measure (ideally in a dashboard) the many data metrics that comprise your overall data health.
If you want to learn more, reach out to Barr Moses. Or book a time to speak with us below.
Our promise: we will show you the product.
Read more posts.