Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Scary Data Quality Stories: 7 Tips for Preventing Your Own Data Downtime Nightmare


Sara Gates
Sara is a content strategist and writer at Monte Carlo.
One dark and stormy night, an innocent data team completed a crucial user-facing system conversion. But shortly thereafter, their rate of successful user logins plummeted into the abyss. The change in high-level metrics set off alarm bells, summoning their colleagues on product and engineering teams to run to the rescue and determine what was going wrong with the customer experience.
After delving into the shadows of root cause analysis, the teams finally uncovered the truth: the new system was defining the event that is a login differently than the previous system, and was reporting a step in the login process further upstream and earlier in the event funnel. That meant any successful login was only being captured once, but since the system captured more event-level data than session-level data, any unsuccessful attempts were being overrepresented in the data — because once a user failed to log in, they would try again and again.
Neither the old or the new data was wrong, but because it was inconsistent with their existing mental model, it was a phantom that distorted reality for all the teams involved.
On another gloomy night, another data team watched in disbelief as the fruits of their labor were slowly poisoned from within. At their freight tech marketplace, the team had crafted a valuable machine learning model that predicted the auction ceiling and floor of truckers’ possible bids for particular shipments. The model worked by training on all the data that was happening in the marketplace, and helped the company know whether it was profitable to put a given shipment on the market or not.
But another team within their organization had introduced a new feature that automated that bidding process for the drivers — improving their experience, but unknowingly infecting the valuable auction model by routing that “autobid” data back for training. As the data team discovered too late, the model no longer predicted the actual behavior in the marketplace, but rather, only predicted the company’s own automation. That corruption in training data led to millions of dollars in lost revenue…and the company has since shuttered.
These data downtime horror stories paint an all-too-vivid picture of the impact of poor data quality. But unlike most nightmares, they’re real.
We first heard these terrifying anecdotes when we gathered a panel of data experts: Gable CEO and co-founder Chad Sanderson, Ternary Data CEO and author of O’Reilly Data Engineering Fundamentals Joe Reis, and Capital One Senior Manager of Analytics & Data Science Emily Riederer.
Chad, Joe, and Emily joined us to share their chilling data tales — and their top tips for warding off your own horror stories with proactive approaches to managing data quality at scale.
Table of Contents
Tip #1: Join forces with upstream data producers early and often
In the battle against data downtime, our experts agree: your greatest allies are your upstream data producers. So it’s never too early to build alignment and start leveraging data contracts, an effective safeguard against unintended data consequences.
By implementing processes and tooling to enforce specific constraints around how production data is structured, contracts help keep everyone on the same page and keep data in a consistent and useful format for downstream users.
According to Chad, start implementing contracts as early as you can. “I think most people recognize that having some type of API or expectation on the data is very useful. If you’re the only data engineer on your team, it’s pretty easy to go into services that exist and say, ‘Hey, we’re just going to go ahead and add these contracts.’ The operational overhead of convincing people to use them is extraordinarily low.”
Later on, Chad warns, comes a “desolate wasteland” of middle ground. When your product has more services, you have more data — but you’re still figuring out what the data products are and how data will be used. And as both your data and software engineering teams grow, it becomes more complex to add contracts to services.
“It does require some overhead, and people might push back and say, ‘Well, this seems like a cost, and yet we haven’t even found what the data’s going to be useful for yet — so it’s probably going to slow us down’,” Chad says.
If you missed the chance to implement data contracts at the outset, don’t break out in a cold sweat. Chad also advises that once you reach the late-growth stage and beyond, it’s a “really, really great time once you actually have a bunch of data products.” At that point, when “…you have really important data products that are doing useful things, that’s the time where you probably need data contracts the most. But it is going to require some organizational work to convince and work with the upstream teams that this is important for data governance.”
Tip #2: Accept that data quality is a war, not a battle — but we may be at a turning point
Our data experts know that data downtime is an ancient enemy — relative to the age of the modern data stack, in any case.
Joe shared that Bill Inmon, widely recognized as the father of the data warehouse, “once taught me something very interesting. He actually says that data should be believable — notice that’s not the same definition as correct, which I thought was very fascinating. But it is definitely challenging, and we’ve been talking about it in the industry for decades.”
As a longtime data engineer, Joe’s opinion is that “…data quality is one of those things where we want to do it — the intention is there — but the willpower to really act on it is a much different matter.”
Still, he sees positive movement. Conversations about data quality and data downtime have become mainstream, which is a step in the right direction. “Data’s become more front and center. Back when I got started, data was very much the uncool thing to do. Now, data is pretty awesome. If we can’t get data quality right this time, when all the attention is put on it, then I don’t know when we’re going to get it right.”
Tip #3: Data quality and code quality are different beasts — so treat them accordingly
Data quality and code quality are different beasts, and teams need to understand their respective nuances. As Chad describes it, data quality is closer to quality in manufacturing processes, because there’s a supply chain: “You’re handing off materials to many different people, and at every step of that handoff process, there’s some interesting transformation that’s applied.”
By contrast, Chad says, “If you’re building software, you can build it in a vacuum. That’s the whole idea of the microservice: the engineering team can spin up the service, the database, create the API, create the front-end, and deploy it. And they do that, more or less, all on their own. It’s very different from being part of a supply chain, where you have to have incredible communication and visibility and awareness at every step of that process.”
Data follows a similar supply chain pattern. Data is created, lands in your warehouse or data lake, gets transformed into intermediary tables, and then populates data products.
“And it’s really hard to establish those lines of communication between each of the teams that are managing a handoff,” Chad says. “Oftentimes, the software engineers who are collecting the data don’t have any clue about how it’s used. They don’t know where it’s going, they don’t know why it’s being leveraged, and in some cases they don’t even know that the data product exists. It’s a bit like the tire manufacturer not understanding their tires are going to be put on a car. You could imagine all the chaos that would result from that.”
Remember the data team that watched a brilliant autobid feature destroy their company’s critical ML prediction model? That was Chad’s personal horror story. He knows the chaos of a poor data supply chain firsthand.
Tip #4: Wield the ROI of data reliability
One valuable weapon in the fight against data downtime? Measuring and proving out the ROI of data reliability. Our experts say it’s invaluable to drive investment in data quality initiatives and build awareness of its importance within your organization.
But, measuring the impact of data quality across the board is notoriously difficult. Instead, our experts recommend zeroing in on specific data products.
“We’ve got data products and they’re useful,” says Chad. “They’re contributing some value to the company. And instead of trying to apply quality everywhere, and justify governance on every single dataset that we have — many of which might not be all that useful to the business — we instead attach data quality to a product which objectively has some value, so you can start to measure the impact.”
For example, consider a machine learning model that generates $120 million over the course of a year. If it has an outage every month, and every outage has a cost, then improving data quality to prevent that outage has a clear financial benefit.
“It gets hard when you’re trying to apply data quality the same way we think about storage and pipelines,” says Chad.
Joe agrees, and points to the frequently used term “directionally correct” as a common symptom of this challenge. As long as the trend is fine, stakeholders don’t really care if it’s correct. “That’s a cop-out, for sure,” Joe says. “But that’s historically how it’s been. Now, as more companies become more data-centric and data becomes more front and center, ROI becomes much more clear.”
Emily adds that the human cost of data quality shouldn’t be overlooked. “ROI is hard to capture because we have data superheroes. They’re the one person crushing those bugs, solving issues in the last mile. But if more leaders can come to understand how it offloads teams and opens up bandwidth, thinking about data quality as being that one extra person on your team would make it seem like more of an accelerant versus just a cost center.”
Tip #5: Uncover all the skeletons by over-testing your data
Know who never survives in a horror story? The person who refused to believe anything bad could happen, and ignored the danger they were in.
Here’s how to do the opposite in the data world: test, test, and over-test, from day one. Emily advises teams to develop data tests early in their processes to achieve what she describes as “the 0.1 version of a data quality agenda” while they’re building new data or data products.
That’s the time, Emily says, “…where your thoughts are probably clearer than they’ll ever be again of ‘What do my users need?’ and ‘What am I actually trying to do?’. I just built this, so I know where the skeletons are buried and where the vulnerabilities are in the system.”
Writing some one-time validations at this stage — before deploying any SQL into production — in a structured way will pay off in the long run. “There’s a lot of great work that can be done incrementally to set yourself up for success later,” Emily says.
Tip #6: Survive every act with a crawl, walk, run approach to data quality
In most horror stories, the stereotypical survivor is the “final girl” — the would-be victim who builds up determination and resilience over time until they’re able to defeat the bad guy in the third act. They don’t start out as heroes — and neither do most data teams.
That’s why Chad believes a “crawl, walk, run” approach helps teams survive early on, and assemble a thriving approach to data quality in the long run.
In the earliest days, “You need to be very explicit about where quality matters and what quality means to you,” Chad says. He describes seeing a team with an expansive data warehouse, where some data is vitally important for accounting, other data is used for machine learning, and still other data is just a view that powers a dashboard that a product manager looks at once every six months.
“Your accounting data and the dashboard nobody’s looked at for six months obviously deserve very different levels of data quality,” Chad says. “I always recommend starting with your ‘Tier 1’ data services or products. If data assets in your business broke, and it would matter to someone in your company, identify them.”
Next, he says, understand the potential causes for any Tier 1 data service outage, and quantify what happens when those critical services fail.
For example, he shares another horror story from refrigeration company Sub-Zero: “They had item IDs coming from a database that they used in their barcodes. One day, that data changed from a seven-character string to an eight-character string — and they put a whole bunch of barcodes that were totally invalid on refrigerators that were shipped out to homes. They needed to send a person out to replace those barcodes, which cost tens of thousands of dollars.”
Avoiding incidents like these typically means conducting an exercise to understand where important data for those Tier 1 services comes from, and understanding what will happen to the business if that data changes. “Once you have your risk profile, you can now start having a conversation about data quality,” Chad says. “That might be testing, contracts, ownership, or just better documentation — but there certainly is a starting point there, and the more sophisticated and automated that you get, the better you’ll be at stopping some of these issues in code.”
Tip #7: Data observability is critical once you have meaningful data
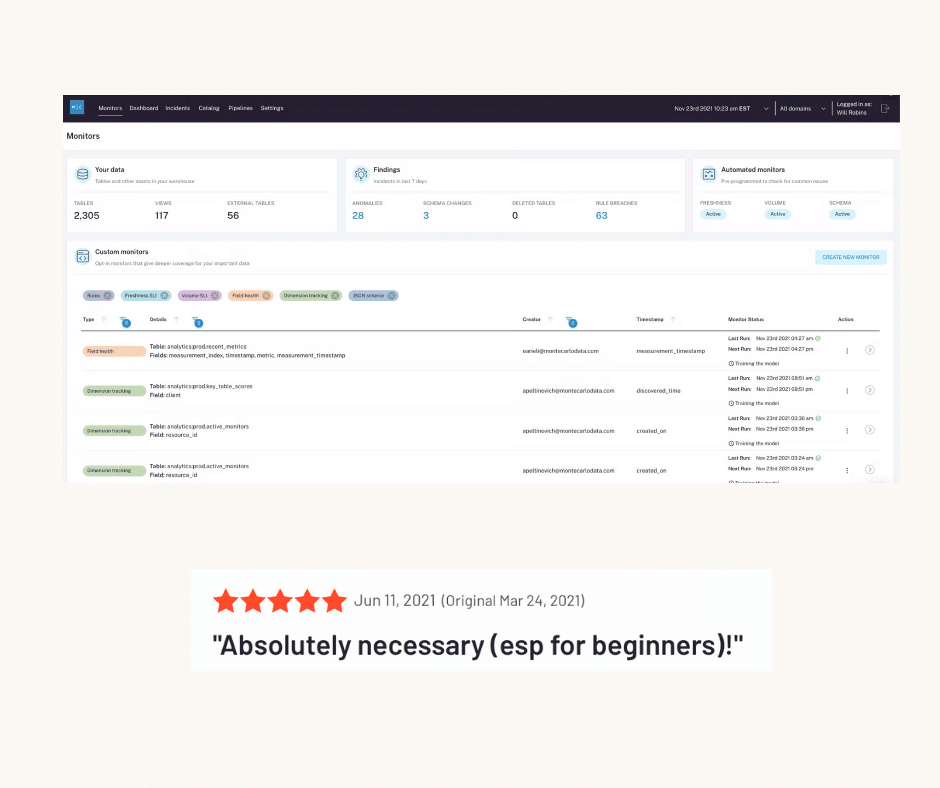
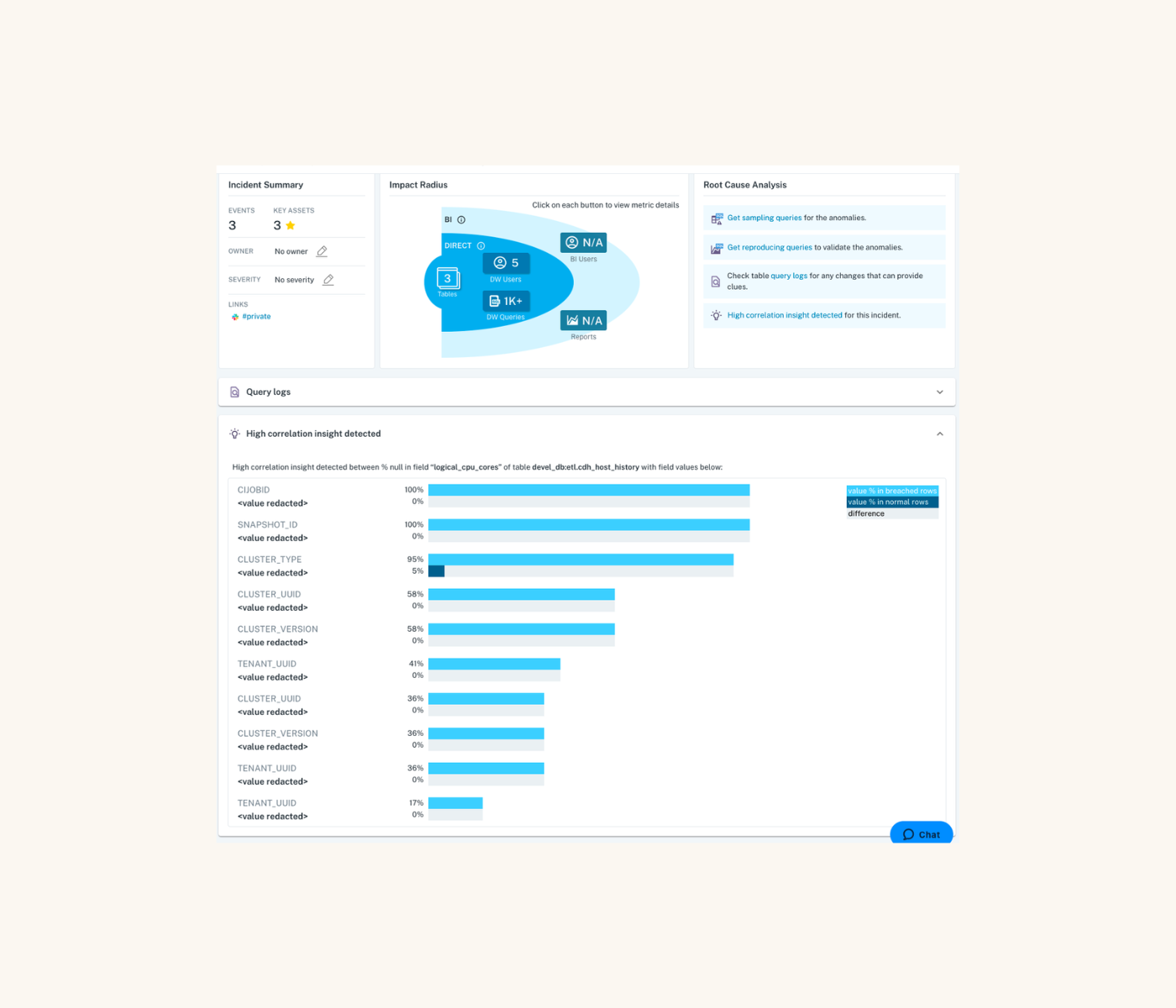
When it comes to protecting your data against downtime horror stories, you’ll want to pair thorough testing with a more scalable safeguard: data observability. By layering automated monitoring and alerting across your data stack, you can be the first to know when data incidents occur — and more quickly troubleshoot and conduct root cause analysis with end-to-end lineage.
So when’s the right time to invest in observability? According to Chad, whenever you have meaningful data. His current startup is pre-launch, but, “Once we have SLAs, customers, very clear requirements — there are things we’ll need to look for in order to make sure that our product is functioning properly. I think monitoring for software is a no-brainer, and I feel the same way about monitoring for data. Once you’ve got some set of pipelines that you know are meaningful, whether that’s data products or intermediary tables that are really important, monitoring will be helpful.”
Chad shares one last horror story. He talked with a company that was doing a sweep of the query history of all their tables in Snowflake, and found one currency conversion table that was used for almost every single report in the company — and the data team didn’t even know about it. When quality issues happened, it had a “nasty waterfalling effect that impacted hundreds or even thousands of people,” Chad says.
This is where contracts and monitoring through observability play exceptionally well together. “The way I like to frame the relationship of a contract to a monitoring system is that the contract is your known knowns — ‘these are the things we know need to be true about our data’,” Chad says. “Like the Sub-Zero refrigerator, this customer ID always needs to be a six-character string. If there’s anything but that in our data, we’re going to run into really big issues.”
But, you can’t predict everything that will go wrong with your data. And that’s where observability comes in. “You also have your unknown unknowns — the things that could and probably will go wrong about your data that can cause significant issues, and you need to have some sort of system that’s on the lookout for those,” Chad says. “That’s where monitoring comes in. The two systems work really well together, and they have a great partnership.”
Bonus quick-fire tips
Consider your possible threats and leverage defensive data modeling
“A lot of times, we conflate data quality with just data testing — that one last check before you ship things out the door, which can be too little too late,” says Emily. “It’s like taking a quality assurance mindset instead of a quality engineering mindset.”
Rather, she advises that data teams build data quality solutions throughout their system. “Really think about the threats and vulnerabilities when considering the design choices that we have to make anyway throughout our pipeline. How do we make all of those to try to drive towards quality?”
This defensive approach to data modeling includes simple upstream steps. “Think about picking the sources that will be the most stable, and are the shortest supply chain before they’re getting to you,” Emily says. “In the data modeling stage, opting for simpler and more normalized structures means you’re not dealing with a lot of complex versions or changing dimensions. You can have workflows that are less error-prone, easier to recover from, and diagnose data quality errors after they’ve happened.”
Emily also recommends not letting team members get away with writing less-than-optimal code at the transformation layer. “Applying basic hygiene practices like coalescing things that you know when you add them up can’t be known, or not having default case statements that go to a valid case. Just in every little decision that you make, bake in closing off whatever possible threats or vulnerabilities you can in the process of building.”
Measure twice, cut once
Joe’s origin horror story involves preparing a forecast for investors at his CEO’s request — and then mistakenly dragging a formula down the spreadsheet that resulted in every product showing the same forecast. He didn’t notice his error, but the investors certainly did. It was a valuable lesson: measure twice, cut once.
“Just make sure you’re doing what you think you’re doing,” Joe says. “It’s really easy to make mistakes of omission, not commission — it’s easy to get sloppy. This is how data quality problems start happening.”
Obsess over your data source systems
“Obsess over the source systems of where your data’s coming from, and at what point it’s being collected,” says Emily. “That can be a source not only of data quality issues, but even just statistical biases.”
Joe agrees, saying, “Data quality issues start upstream when the data is created. This is the chance you have to get it right, and most of the time, we get it wrong.”
Prevent your worst nightmare with data observability
Like all stories, we can learn a few things from these harrowing tales — good and bad.
The bad: data downtime isn’t the monster under your bed or the supernatural stuff of ghost stories. It’s real. It’s unavoidable, even for the best teams. And it is coming for you and your data.
The good: you have many weapons at your disposal to fight back!
Contracts, testing, stakeholder alignment, and defensive data modeling are all available to your team — along with data observability, the most scalable way to protect against data downtime. Automated monitoring and alerting is your vigilant alarm system. Lineage is your escape route. And whenever you’re ready to reach out, our Monte Carlo team is ready to help prevent your worst data nightmares from coming true.
Our promise: we will show you the product.
Read more posts.