Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Is Open Source Data Observability the Answer to Your Data Quality Woes?


Leigh Robertson
Leigh is a Senior Data Engineer at Vizio who writes about the modern data stack.
If the terms “data observability” and “data quality” sound unfamiliar to you, you might want to check in on your data engineering team.
Bad data is the singular perpetrator of data quality incidents, leading to hundreds of hours of lost data engineering time—not to mention some potentially costly consequences for your downstream consumers.
As a data engineer myself with experience in everything from logistics and natural gas to ad tech at Vizio, I’ve seen all shapes and sizes of data quality issues—and their cleanup costs. With data emerging as the modern-day oil and organizations demanding even more from their data teams, a robust data observability solution—and a strategy to leverage it— is critical to protecting the value of both your data team and your data products.
There are two primary approaches to “data observability”
- Leveraging an open source data observability tool
- Purchasing a managed data observability solution
In reality, open source libraries lack some of the critical features required to be considered true data observability. But what are they? And how do you know when to choose one over the other?
In this article I’ll compare and contrast two popular data quality and observability solutions I’ve used over the years—open source data testing framework Great Expectations and data observability platform Monte Carlo—to help you understand the pros and cons of each approach and offer my perspective on how to choose the right solution set for your data team.
Table of Contents
- What is data observability and why does it matter?
- Open source data observability with Great Expectations
- Managed data observability with Monte Carlo
- Open source data observability or Monte Carlo? Which one is right for you?
What is data observability and why does it matter?
If you were running a restaurant, you wouldn’t want customers telling you the chicken is undercooked. Instead, you’d have appropriate quality monitoring in place to catch a raw chicken parm before it went out.
The same holds true for your data.
Just like bad food in a restaurant, data quality issues erode trust in your data. Worse than that, data quality issues undermine the value of your data engineering team.
As a fellow data engineer, I understand the unique frustration of a Monday morning Slack from a stakeholder telling you the data is wrong. That’s why I advocate for data observability as a critical component of the modern data stack—to help teams detect and resolve data quality issues before they reach downstream consumers.
In short, data observability is a data quality solution that allows data teams to monitor the health of their data pipelines from end-to-end. A data observability solution will integrate across your data stack to provide detection for specific health indicators like data freshness, volume anomalies, and schema changes from CI/CD to help data engineers resolve data quality incidents faster.
As I mentioned before, there are predominantly two approaches to data observability: open source data observability libraries and vendor-managed data observability.
While some larger teams may opt to build their own data quality tooling in-house, this approach isn’t advisable for most teams outside of a certain scale (Microsoft, Amazon, etc.) due to the resources required to build and maintain it long-term. Home-built data quality solutions tend to disproportionately benefit enterprise data teams with very large data needs and predominantly custom data platforms. So, because this is a very small subset of the data community, we’ll ignore that option for now.
In the following paragraphs, I’ll compare and contrast both open source data observability and vendor managed solutions by considering a hypothetical data quality issue and how it would work itself out in each scenario.
So, with the context out of the way, let’s take a look at open source data observability by examining one of the most popular open-source libraries—Great Expectations.
Open source data observability with Great Expectations
As outlined above, Great Expectations is an open source data quality framework that helps ensure data reliability by formalizing expectations and enabling data teams to create tailored data quality rules for vital data quality checks like column statistics, distribution patterns, and null values.
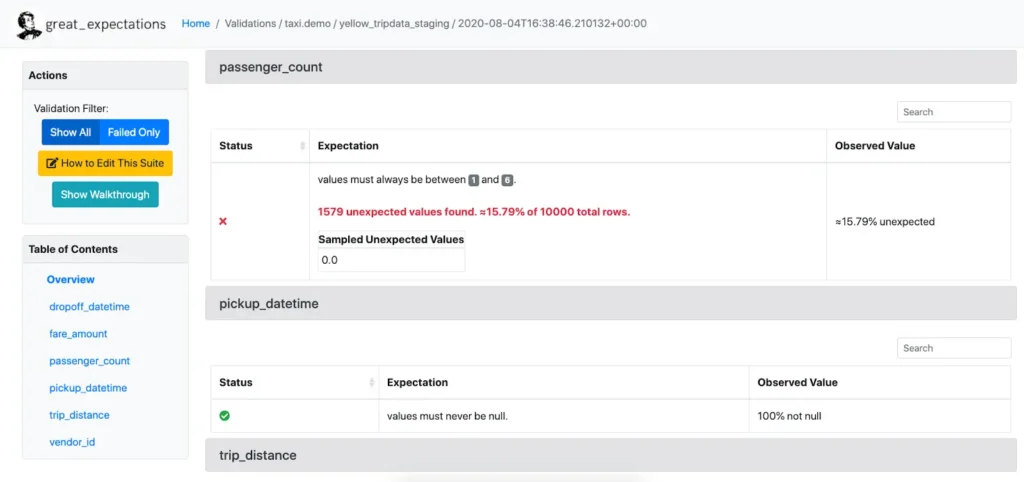
Integrating seamlessly with Python, SQL, and other tools, Great Expectations is particularly useful for beginners due to its cost-free nature and extensive community.
In order to use Great Expectations, data teams will require a dedicated engineer to code each test by hand based on common issues that are likely to occur in production.
To visualize this a little better, let’s consider a scenario with a fictional company I’ve introduced in some of my previous blog posts called “wesellstuffonline.”
In this fictional scenario, business stakeholders at wesellstuffonline have long been interested in understanding average session duration at the user and daily level. To solve this use case, a workflow like the below has been set up in which raw data is loaded into a raw table and then aggregates are calculated to determine the session duration for each website visit.
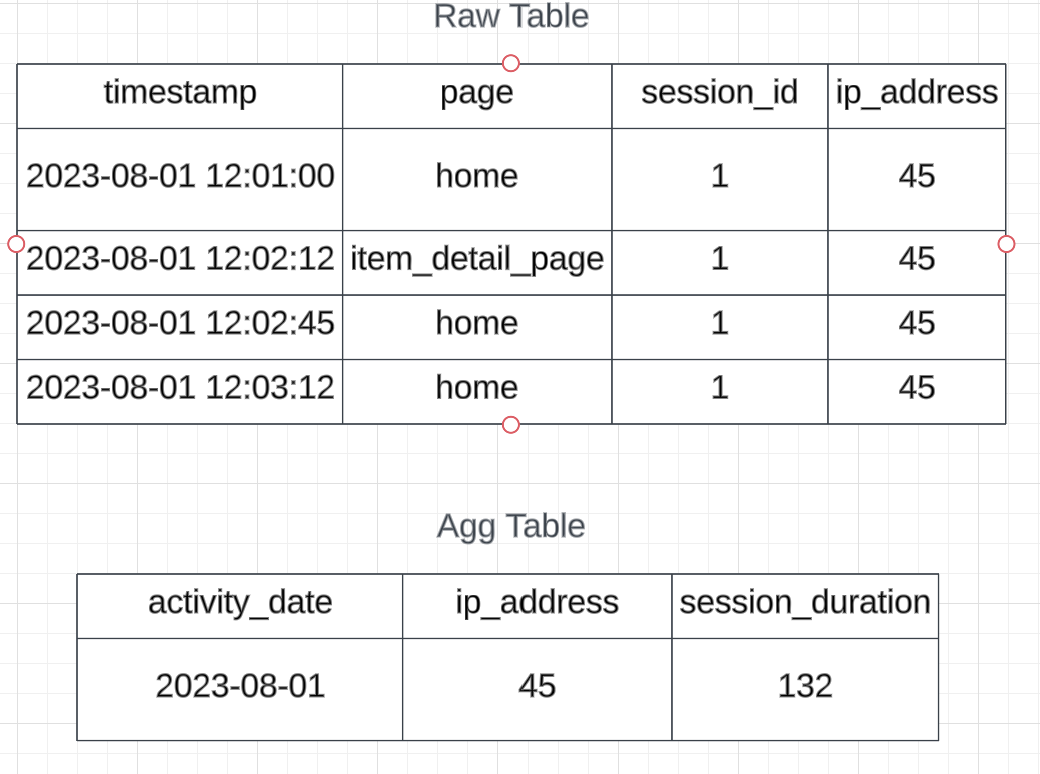
Similar to a lot of companies, there are two distinct teams involved in this use case—one team that manages the website where the data is created and a data engineering team that handles the analytics of that data.
One day, the website team makes a change to the website. As part of their standard process, the data engineering team hand-codes a typical regression test using Great Expectations to make sure that nothing gets broken during the change. As a secondary layer of quality coverage, the team also conducts some basic validation of that data in a development environment. Based on those two tests, everything looks good!
What’s going on here is that the data engineering team is testing for known issues. Based on their experience and what’s likely to happen, the team has created data quality checks to verify the quality of the data in production for their critical session-duration table. And in this limited use case, Great Expectations works great.
The limitations of open source data observability
In my experience, Great Expectations thrives in an environment with limited data and use cases being managed within a relatively simple data platform. In this case, an open source library is more than sufficient to control data quality with relatively little risk to production pipelines.
However, as quality checks become more complex, open source data observability’s limitations become more pronounced. Coding a single test is easy to manage for a small team, but the more tests you need, the more unscalable testing with open source data observability will become.
What’s more, recall that our data engineers are only testing for known issues. What happens if that issue isn’t something a data engineer has encountered before?
Let’s imagine that as a result of this recent website change, a crucial field called session_id now has a large increase in % of nulls.
Historically this field has had a null rate of about 1%, but after this change, that number has increased to 5% due to an undiscovered bug. The website team doesn’t notice the change because it’s too abstracted from their purview; and the data engineering team—who only created the limited Great Expectations tests they knew and had time to code—doesn’t have a protocol in place to test for a data break of this type.
Because no one catches the issue with Great Expectations, the code gets pushed to production. Several days pass before the issue is finally caught by a frustrated downstream user who notices that certain power users have stopped appearing in their report.
The data team finally spends two days root-causing the issue back to a missing session_id field, then another day remediating the issue and backfilling the affected date range to restore the integrity of the session duration report.
So, what’s the impact for this team? The team has lost three days of critical data engineering time on damage control that could have been spent adding new value for stakeholders, downstream consumers haven’t been able to use their session-duration report for ~one week, and institutional trust in the data has been damaged in the process.
Not a great outcome. And this really underscores the difference between open source libraries and true data observability. Open source data observability solutions can’t offer true data observability because they don’t provide coverage for unknown issuers or enable teams to observe the gaps they might have missed in their data’s quality— gaps that become increasingly frequent as organizations scale.
That’s not to say that Great Expectations isn’t still valuable—but its coverage isn’t comprehensive.
In this instance, wesellstuffonline’s data has scaled to a point where hand-coding data monitors is insufficient for maintaining data quality. What the team needs now is a comprehensive solution that can scalably monitor data quality while also accounting for the gaps in their visibility. At this point, considering a more robust managed solution like Monte Carlo is the right choice.
Managed data observability with Monte Carlo
Let’s consider our same scenario with a managed solution like Monte Carlo deployed across this production table.
Unlike an open source library that requires teams to configure and apply each test manually, Monte Carlo is a managed solution that leverages out-of-the-box ML-enabled monitors across all your tables at once to automatically create tests and thresholds based on the normal behavior of your data.
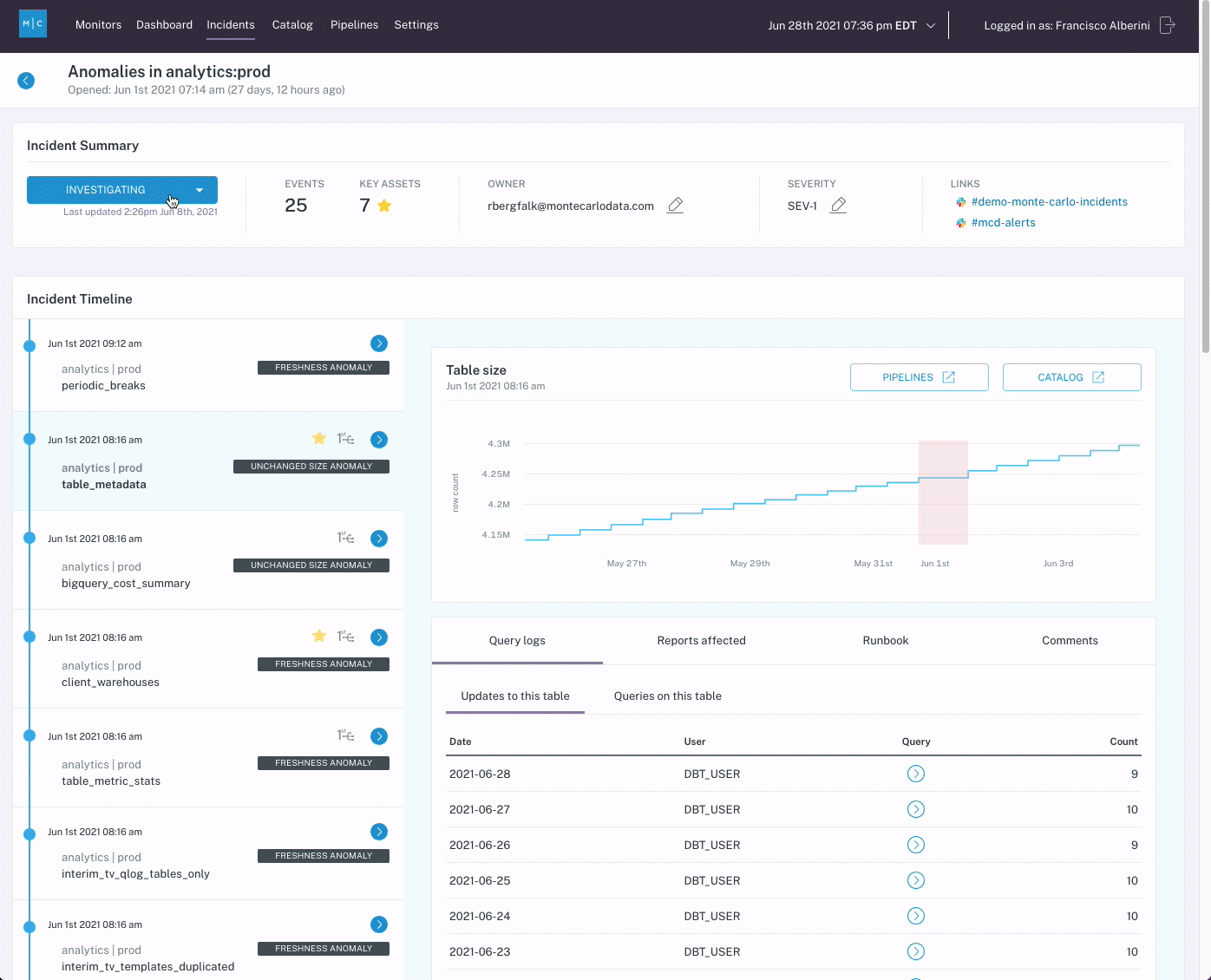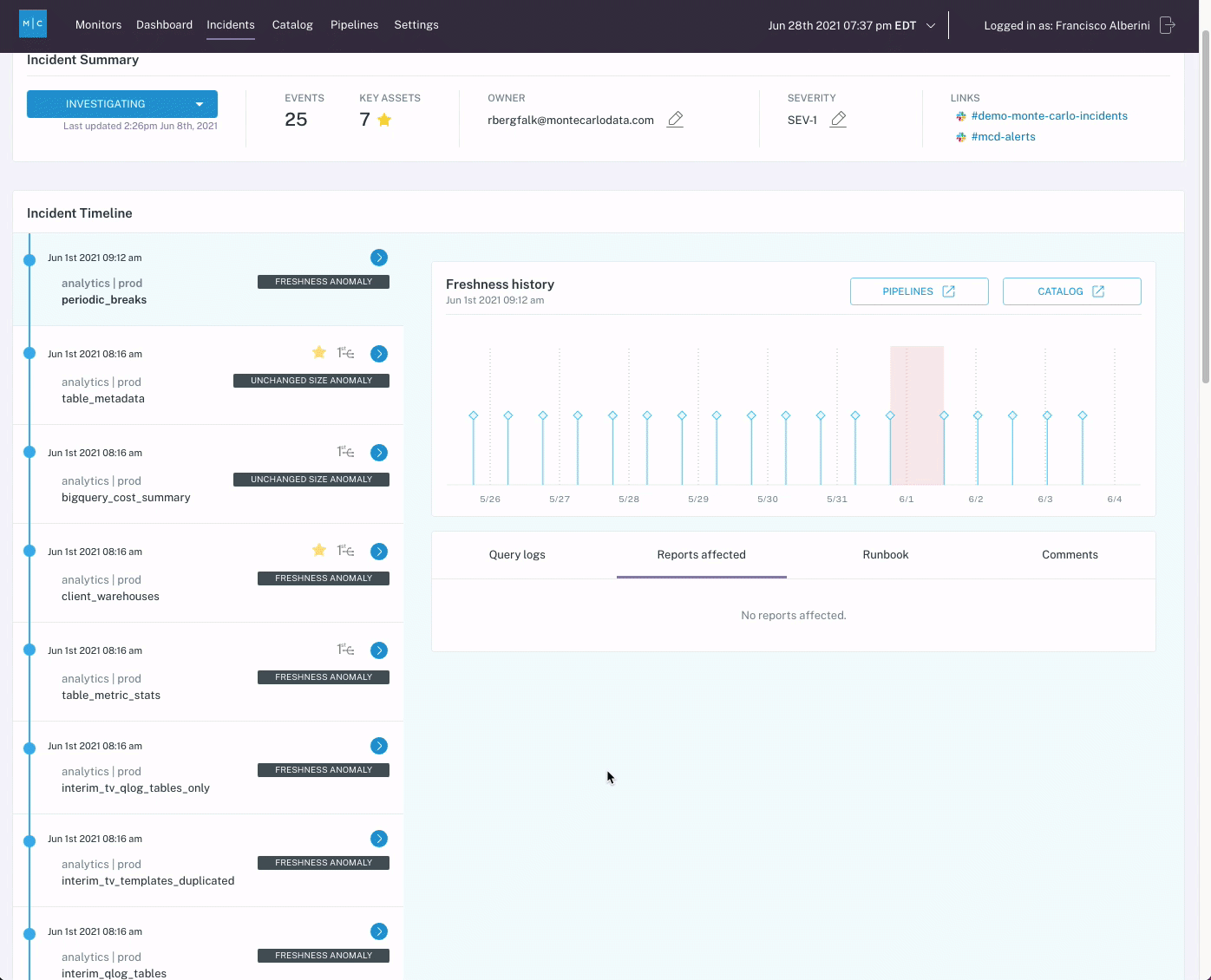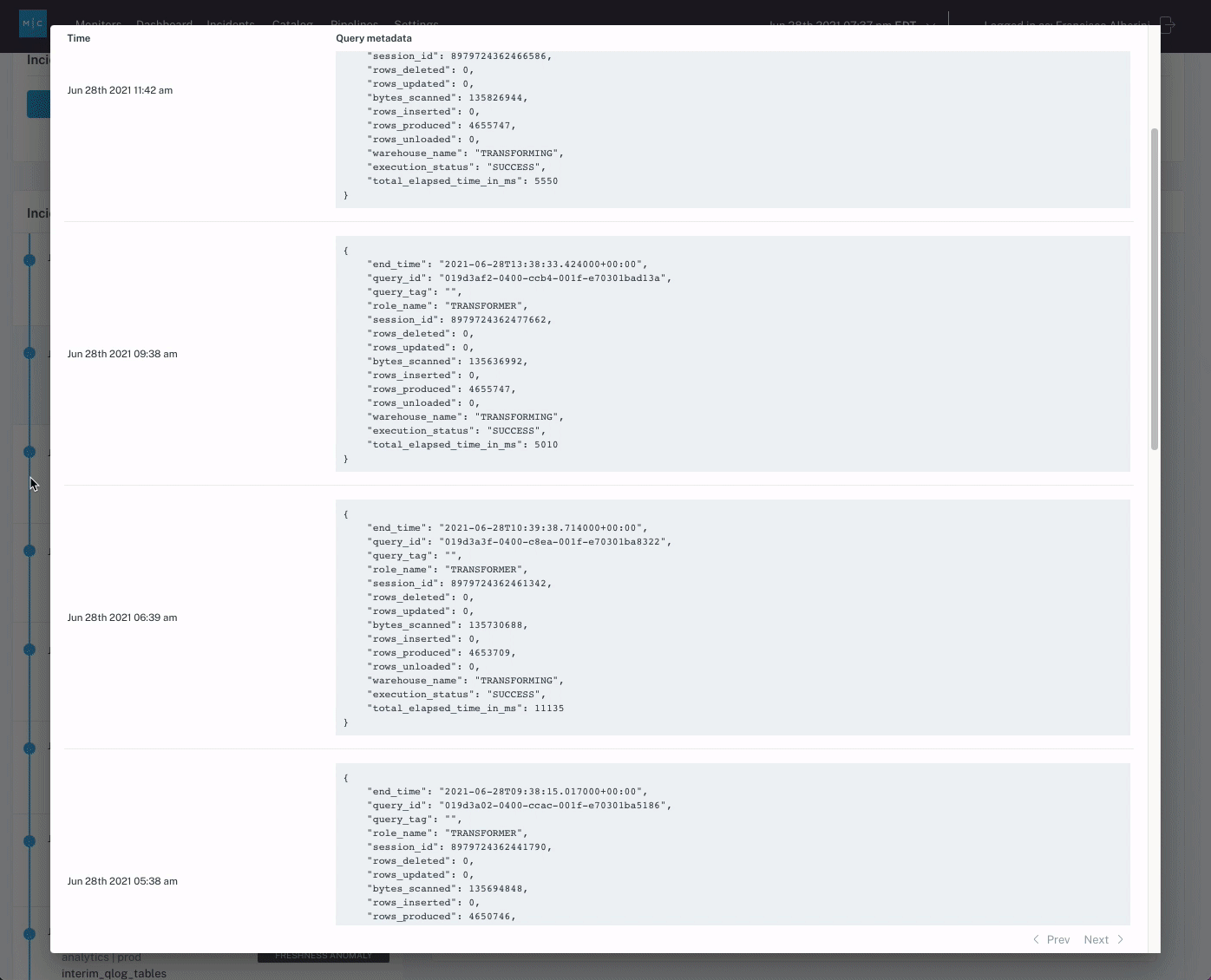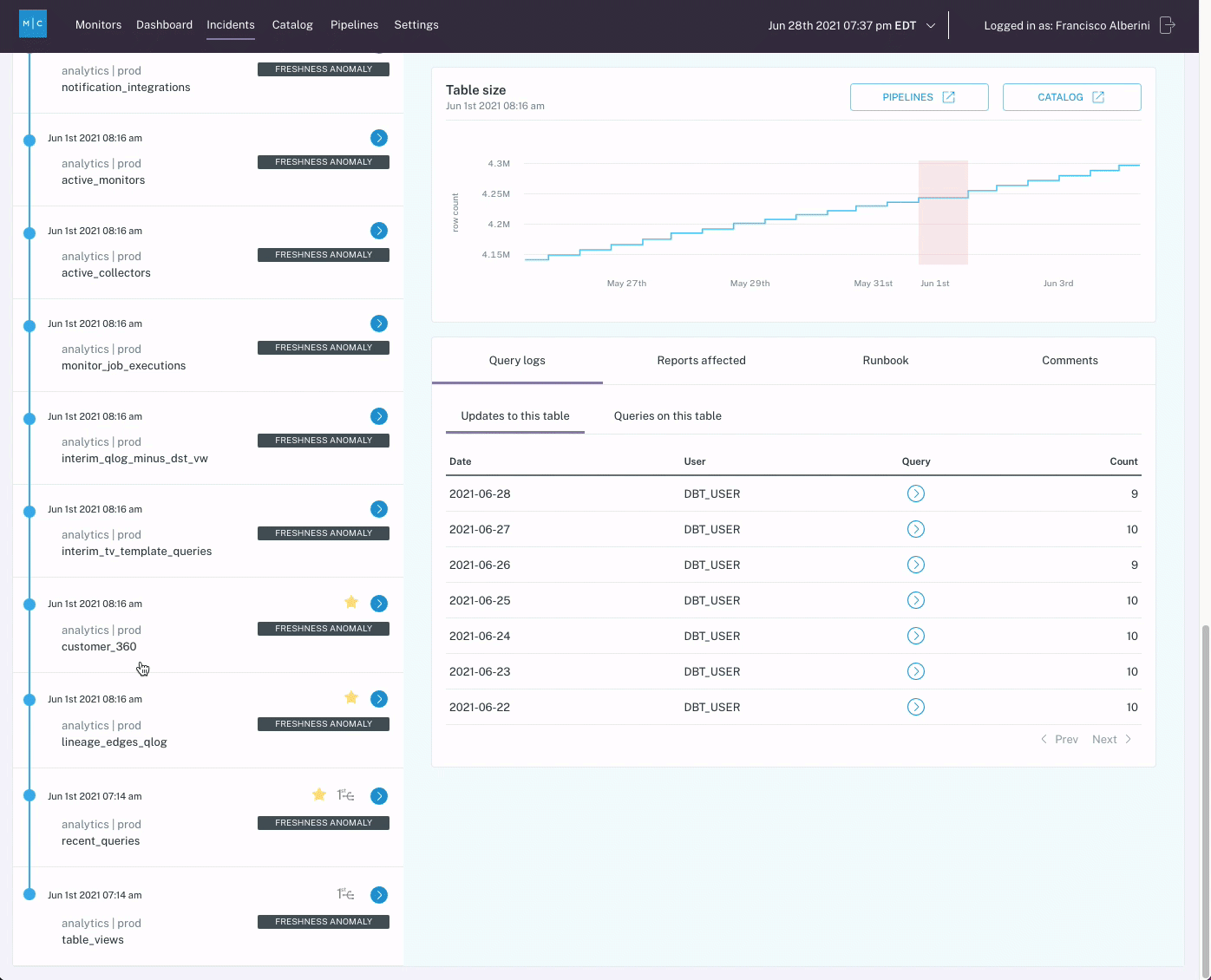
When the change is made by the website team, the data team is able to fully skip the test creation process because basic quality coverage was enabled for each table as soon as Monte Carlo was connected and quality coverage scaled naturally with the creation of the session-duration model.
With Monte Carlo deployed across these tables proactively, the error is flagged immediately thanks to a default null % check, in addition to other standard tests our team would have hand-coded in the original scenario.
With a scalable managed data observability solution, the data engineering team would have already discovered the changing null rate and begun work fixing the issue days before the issue could be flagged in our first scenario.
What’s more, a solution like Monte Carlo offers out-of-the-box column-level lineage to make root-causing the issue faster after detection.
Vendor managed data observability excels in environments where data sources, platforms, and teams are scaling quickly and the opportunities for quality issues become more regular and complex. Vendor managed data observability provides the ability to instantly scale data quality coverage with your use cases—from ingestion to BI—and offers enhanced ability to remediate quality issues faster in dynamic environments.
The limitations of vendor-managed data observability
Of course, buying a managed solution comes with a price tag, which probably doesn’t make sense for teams with relatively simple data quality needs. If you only have five data sources and 10 tables, you can probably get by hand-coding your data quality tests with an open source data observability library pretty easily.
Larger organizations like Meta and Google with inordinately large and custom data tooling may also opt for a home-built solution as opposed to either open source data observability or a vendor managed solution if they require greater flexibility and interoperability within their existing data platform (though I’ve known Monte Carlo to be very developer friendly in my own personal experience).
However, for teams with substantial data quality pain and a fairly regular data infrastructure, the value will quickly eclipse the cost of a vendor managed solution, both in the data engineering time you’ll save and the institutional trust you’ll be empowered to create.
From my perspective—and with the exception of very large organizations—vendor managed solutions are less a question of “if” but “when.”
Speaking from my own personal experience, Monte Carlo is a pioneering data observability platform that’s been a game-changer for my teams when it comes to ensuring data quality and reliability at scale.
By leveraging proactive monitoring and anomaly detection, it empowers data teams to quickly identify and mitigate data pipeline issues before they impact insights. Monte Carlo excels in handling common checks like monitoring data freshness, verifying schema conformity, and detecting unexpected data fluctuations, and has helped my teams set a new standard for dependable data-driven decisions.
Open source data observability or Monte Carlo? Which one is right for you?
Data quality is paramount in today’s data-driven landscape—and data observability has quickly become the cost of admission.
Neglecting a robust data observability strategy can let data quality issues run wild and quickly erode the valuable institutional trust data teams need to scale their platforms and provide new value to stakeholders.
While Great Expectations offers an excellent entry point for new data teams, Monte Carlo takes it a step further with comprehensive monitoring and scalable automation that’s naturally lacking from an open source solution. Proactive monitoring, ease of set up, and a broad and deep range of quality checks make a vendor managed solution like Monte Carlo a no-brainer for organizations looking to improve their data quality and put an end to digging into why this number looks “off.”
However, whether you choose to go open source or vendor managed is a decision that will depend entirely on your needs and scale. The most important thing is to be proactive. Implement a data quality solution that will cover your current and mid-term needs before data quality becomes an issue.
Because building quality into your data is hard work—but rebuilding trust is even harder.
Read more posts.