Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Integrity vs. Data Quality: 4 Key Differences You Can’t Confuse

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Data integrity and quality may seem similar at first glance, and they are sometimes used interchangeably in everyday life, but they play unique roles in successful data management.
In this blog post, we’ll review four crucial distinctions you need to know to never get them mixed up again:
Purpose
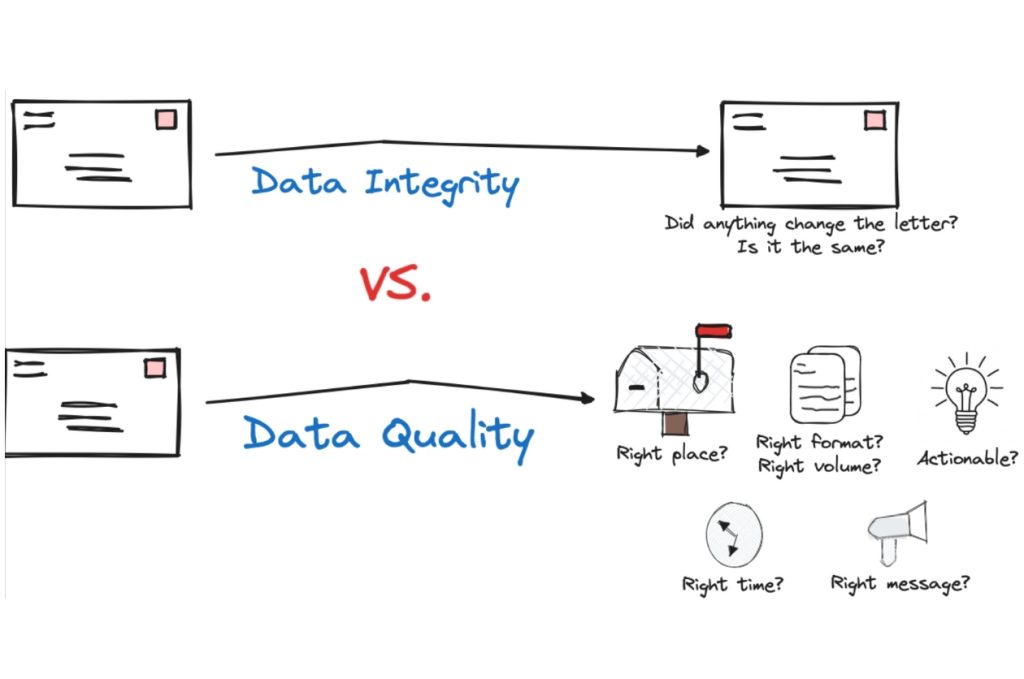
Data integrity refers to the accuracy and consistency of data over its lifecycle. When data has integrity, it means it wasn’t altered during storage, retrieval, or processing without authorization. It’s like making sure a letter gets from point A to point B without any of its content being changed.
Data quality, on the other hand, is about how well the data serves its intended purpose. This involves several elements, including accuracy, completeness, consistency, timeliness, and relevance.
If we extend the mail carrier analogy, data quality doesn’t just mean the letter gets to point B, it goes a few steps further. It checks that it’s the right letter, it’s clear and understandable, arrives exactly when it’s needed, and follows a consistent format.
You can have data quality, without data integrity. For example, data is frequently transformed, manipulated, and combined with other data to make it more suitable for its intended purpose.
In short, data integrity focuses on the preservation and protection of data’s original state, while data quality is concerned with how suitable and effective that data is for its intended purposes.
Impact
Now that you understand the purpose of data integrity and data quality, what is their impact on data management and decision-making?
The impact of data integrity is profound, particularly when it comes to governance and compliance. If an organization loses regulated data, or it is corrupted while in their care, the fines can be severe.
“Data coming from hospitals is notoriously inconsistent,” said Jacob Follis, head of data, Collaborative Imaging. “In healthcare, with the regulation, you lose one patient record and it could be a $10,000 fine—and we have millions of patient records.”
Data quality, in contrast, impacts the usability and effectiveness of data. If the data isn’t accurate, complete, timely, and relevant, you run the risk of making decisions based on “false truths.” Poor data quality can lead to misguided decisions, inefficient operations, and missed opportunities.
Applications
Let’s bring these concepts to life with some real-world examples. There’s no field where data integrity is completely irrelevant, but its emphasis might vary depending on the industry.
Data integrity is crucial in fields where the preservation of original data is paramount. Consider the healthcare industry, where patient records must remain unaltered to ensure correct diagnoses and treatments. Even if an incorrect diagnoses was made, you would still want that to remain on the record (along with the correct updated diagnoses) so a medical professional could understand the full history, and context of a patient’s journey.
In banking, transaction data must be accurate and consistent or nobody will bank with you. All of these records are highly regulated and must be preserved meticulously by financial organizations. There are even examples of data integrity in your personal life where you must maintain your financial records for seven years in case the IRS comes knocking on your door for an audit.
Data quality has broad applications across industries, but its importance and degree of quality required is also contextual to the use case. For example, in marketing, high-quality data can help businesses better understand their customers, allowing them to create more targeted and effective campaigns.
Blinkist was able to increase their revenue as customer behavior changed drastically during a pandemic as a result of high data quality.
“The scale of growth that we’ve seen this year is overwhelming,” said Gopi Krishnamurthy, Director of Engineering. “Although the data teams can’t take full credit, I definitely think the things we were able to do—in terms of data observability and bringing transparency into data operations—improved how we target our audience and channels.”
In supply chain management, accurate and timely data can improve inventory management, leading to cost savings and increased efficiency. Wherever data-driven decision-making is key, data quality is a critical factor.
Methods to maintain
Maintaining data integrity involves a mix of physical security measures, user access controls, and system checks:
- Physical security can involve storing data in secure environments to prevent unauthorized access.
- User access controls ensure only authorized personnel can modify data, while system checks can involve backup systems and error-checking processes to identify and correct any accidental alterations.
- Version control and audit trails can be used to keep track of all changes made to the data, ensuring its integrity over time.
The field of data engineering is rife with examples of common techniques and best practices designed to maintain data integrity. For example, primary keys are used within SQL databases to uniquely identify each row in a table. Data vault is a data modeling strategy that preserves 100% of the data–rather than modifying rows, a new row with the correction would be inserted into the table.
Maintaining data quality, however, requires a different approach. It often starts with categorizing and setting clear standards for each data use case within your organization. For example, customer facing data may have a higher standard of quality than an internal dashboard referenced on a weekly basis. You may even want to set data SLAs for your most important tables with specific data freshness and overall uptime targets.
Data governance frameworks can be implemented to define roles, responsibilities, and processes for managing data quality across the organization.
Data teams often use quality checks, unit tests and validation rules can be used to check the data at the point of entry and at each transformation stage in your data pipeline to prevent incorrect or inconsistent data from being added to the system. This strategy can lead to scaling challenges as updating and maintaining this code across tables can be tedious, and will only catch the errors you anticipate.
That’s why data teams leveraging a modern data stack are starting to widely adopt data observability platforms like Monte Carlo. Data observability automatically monitors both your data pipelines and the data running through them by leveraging machine learning monitors to alert you when there is anomalous behavior without the need to set any manual rules or thresholds (although you can supplement this coverage with custom monitors as well).
It helps you detect issues quickly, understand their root cause, and fix them before they impact downstream consumers. It’s about taking a proactive approach, rather than waiting for problems to arise.
Want to get a firsthand look at how data observability can help maintain your data quality? Request a demo of Monte Carlo now.
Our promise: we will show you the product.
Read more posts.