Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Snowflake Summit 2022 Keynote Recap: Disrupting Data Application Development in the Cloud


Matt Sulkis
Matt is the head of partnerships at Monte Carlo.
Conferences typically follow a bell curve. A few people trickle in on day one, a bit more at the welcome event. Then you peak at the keynote. After Day One, these events slowly lose steam until only the most fanatical conference warriors are roaming exhibitor booths late Thursday morning.
Snowflake Summit 2022 has been different – and I mean this in the best way possible. It could be the pent up demand from two years devoid of major conference events, an exuberance around new data technology that is still new to many, or a combination of both.
Whatever the reason, the conference started like someone shot a starter’s pistol. The welcome happy hour in the exhibitor hall was packed with thousands of data leaders enjoying drinks, Chinese food, and vendor elevator pitches.
Tuesday morning was full of a similar excitement and enthusiasm, with the keynote line forming early with eager technologists greeted by flashing blue and silver lights and a techno beat. Without context, you wouldn’t be sure if Snowflake CEO Frank Slootman or Sting (he is in his Las Vegas residency after all) was about to take the stage.
This fanfare turned out to be justified as Slootman, co-founder Benoit Dageville, and Christian Kleinerman took the stage to reveal a series of announcements that promise to disrupt the data management landscape – and beyond.
This post will focus on today’s announcements, while future ones will discuss how Snowflake’s leadership plans to execute on their strategic vision. Here’s what we will cover:
- General Announcements made at Snowflake Summit 2022
- Announcements that will disrupt application development
- Let it Snow: Snowflake’s Momentum is Great for Partners
General Announcements made at Snowflake Summit 2022

Snowflake buried the lede a bit by having Christian Kleinerman, senior vice president of product at Snowflake, go on third to roll out all the new announcements.
Generally, the weight of announcements made at mega-tech conferences can vary. The new features revealed today felt cohesive, robust, and powerful. I think we will look back at this conference as a major milestone for Snowflake, who today made claim to not just being the place organizations can store their data, but the place organizations build and monetize data applications.
Core Platform Announcements
This portion of the keynote started with the core product improvements. While not as sexy as the new features, they are potentially even more impactful as the core engine powers everything. These announcements included:
- Average 10% faster compute on AWS
- Average 10% faster performance for write heavy workloads, with some large workloads showing up to 40% improvement
- 5XL and 6XL data warehouses for AWS in private preview and coming to Azure in private preview shortly.
- 5x faster searches on maps as part of the Search Optimization Service.
Not bad! These gradual improvements can result in millions of dollars of savings across the customer base. As Allison Lee, the senior director of Engineering reminded us, because Snowflake has a single engine approach, there is less complexity so the company’s engineers can move faster and ship more improvements that impact all customers.
Financial Governance Announcements
Christian came back on stage to unveil two new concepts to Snowflake which will help customers better allocate and monitor resource expenditure.
The first new concept called resource groups allows you to select an object that consumes resources (let’s say we call a group RG1 and another RG2) and then assign those resource groups a budget. You can set a cap so those resources don’t exceed the provided budget and be notified to how those resources are tracking against that budget to ensure you are on track. These new features are coming to private preview in the next few weeks.
Christian also mentioned the monitoring and alerts open-source app Snowflake released yesterday to help customers understand consumption (and create opportunities for partners).
Governance Announcements
Christian then went into new business continuity (a fancy word for backup) features coming to the data cloud. While Snowflake has had data replication for 3 years, now customers will now be able to backup and retain information on users, roles, network policies, and a whole host of additional settings that are part of their Snowflake account.
This also includes external resources as a result of a new feature called pipeline replication. When you have object storage in Snowflake and there is a failover, Snowflake will do the heavy lifting so there are no missing records or duplicates records during that failover. This is coming soon to preview.
Perhaps even more exciting is the new masked based policies feature. This takes advantage of policies and tabs features that Snowflake introduced a few years ago. Now customers can create a policy to mask or partially redact columns that might have sensitive information. Those policies can now be applied to tags that are assigned to multiple columns. This goes to private preview very soon, too.
Apache Iceberg
The Snowflake presenters had a lot of energy around external table support on Apace Iceberg tables. Native Apache Iceberg tables are a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Apache Spark, Trino, Flink, Presto, and Hive to safely work with the same tables, at the same time.
Data Ingestion and Transformation Announcements
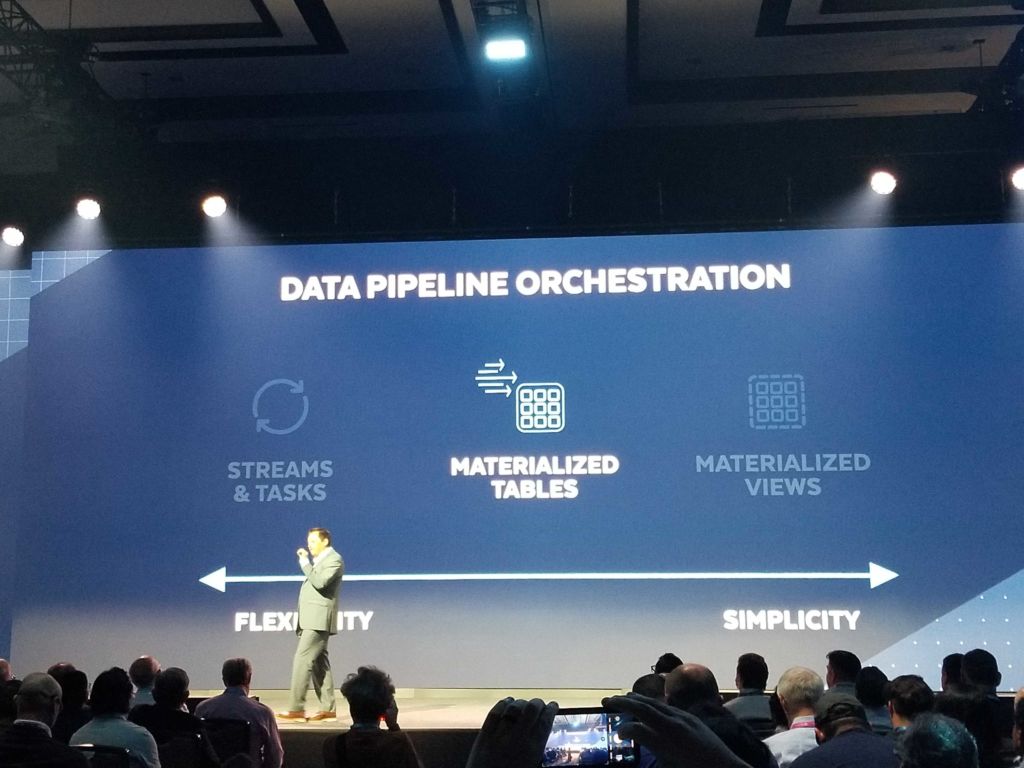
Christian then announced a new way to ingest data in Snowflake: Snowpipe streaming. The company has refactored their Kafka connector and made it so that when data lands in Snowflake it is queryable immediately resulting in a 10x lower latency. This will be in public preview later this year.
On the transformation side, Snowflake introduced materialized tables which was described as the mid-point between streams and tasks and materialized views on the flexibility/simplicity spectrum.
Announcements that will disrupt application development
One of the most exciting dynamics of this keynote was a series of feature developments and demos that built upon one another into a cohesive story. That story? Snowflake is going to be your unified platform for developing data applications from code to monetization.
We’ve written previously about how building an external data product is hard. We saw today how Snowflake is going to make it a heckuva lot easier.
A large portion of the messaging here was targeted at partners and developers that Snowflake is looking to attract to build out their ecosystem and marketplace. This is an incredibly powerful business opportunity, and the company knows it. I’ll do a quick overview of these exciting announcements.
Python in Snowpark

Snowflake knows (because their users have shouted it repeatedly) that to encourage their customers to build applications, particularly machine learning applications, on Snowflake they need to support the programming languages they want to build in, namely Python.
This was previewed during Benoit’s portion of the keynote and unveiled that as of 6am PST this morning Python was available in Snowpark. Also larger memory instances for machine learning and the ability to use ML in SQL both in public preview.
We were then treated to a demo where a senior product manager used Python in Snowpark to build out a predictive learning application for the marketing team to experiment with different advertising channels and how that will impact their ROI.
Native Streamlit Integration

But as anyone who has lived it can tell you, there is a giant gap between data scientists and their models on one side and how operational teams are able to take advantage of their insights. For example, marketers are not always comfortable working from models and even spreadsheets.
This is where Snowflake’s Streamlit acquisition comes in. One of the co-founders of Streamlit showed us how teams will be able to easily build applications and visualizations on their data science model for teams to leverage. With just a few blocks of code, we saw the predictive model that was built in the first demo instantly become a simple app with sliders for marketing investments to show the expected return with nice visualizations.
Snowflake Marketplace and Monetization
These announcements were powerful and compelling for internal data teams, but the picture for Snowflake partners came into sharp focus with the potential for the Snowflake marketplace.
Snowflake demonstrated how easy it was to take the predictive marketing ROI app, with the backend built in Snowpark and the front-end in Streamlit, and take it to the Snowflake marketplace. The app can be easily monetized with flexible pricing features and published to the marketplace in a single click.
While this might not seem as impactful at first glance, the presenters did a great job of emphasizing all the problems this solves for application developers. With a data application powered by Snowflake, developers don’t have to worry about the massive roadblock of accessing customer data, because they can already access it securely via the Snowflake data share. Security, governance, distribution, serverless deployment, monetization–all of these challenges are addressed via the marketplace.
The Snowflake native application and acceleration program is a huge vision with massive implications. It’s essentially the early days of the Apple app store but for data applications, and that model seemed to work out OK for Apple.
Unistore and Hybrid Tables

Just when we thought we were done in this two-hour plus keynote, Benoit joined Christian out on stage for the biggest announcement of Snowflake Summit 2022: Unistore Hybrid Tables. It even got a boisterous “Hell yeah!” from a member of the audience.
Unistore is a new workload in Snowflake that enables the use of transactional and analytical data in a single unified platform without the need for multiple products and services. This is powered by hybrid tables, a new type of table with fine grained read writes and great analytical query performance. They require and enforce a primary key which protects users from duplicate inserts. These tables can have constraints created so that for example if there was an invalid order ID, the order would not go through.
This solves the challenge of instantly producing real-time analytics on transactional data where when the data is moved in batches it misses the orders that were just placed (TechTarget has a great example of one of the unistore beta customers, Adobe).
Let it Snow: Snowflake’s Momentum is Great for Partners
All of these announcements were truly exciting to see from the perspective of a Snowflake partner like Monte Carlo. As data becomes even more powerful and valuable, as data products become more prevalent, organizations will need to ensure that data is reliable with high quality,
This is an ecosystem that is expanding rapidly and we are happy to be playing a large role in helping companies truly mobilize and unlock the power of their data.
And we couldn’t be more excited to pioneer this journey with them.
Interested in learning more about how data observability supports Snowflake’s vision for the data cloud? Reach out to Matt and book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.