 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Orchestration 101: Process, Benefits, Challenges, and Tools


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Picture this: your data is scattered. Data pipelines originate in multiple places and terminate in various silos across your organization. Your data is inconsistent, ungoverned, inaccessible, and difficult to use.
If that sounds like your experience, you’re not alone. While organizations across industries are sitting on mountains of un-mined decision-making gold, scattered and siloed data precludes them from delivering data-driven alchemy.
What these companies need—what you might need—is data orchestration.
Table of Contents
What is Data Orchestration?
Data orchestration is the process of gathering siloed data from various locations across the company, organizing it into a consistent, usable format, and activating it for use by data analysis tools. Data orchestration enables businesses to take various fragmented data pipelines and turn them into rich insights that drive more agile decision-making.
What is the orchestration layer?
The orchestration layer refers to a layer of the modern data platform that empowers data teams to more easily manage the flow of data within and across data environments. Instead of manually managing the flow of an ETL pipeline, the orchestration layer employs a specific tool to automate—or “orchestrate”—the flow of data.
Some of the value companies can generate from data orchestration tools include:
- Faster time-to-insights. Automated data orchestration removes data bottlenecks by eliminating the need for manual data preparation, enabling analysts to both extract and activate data in real-time.
- Improved data governance. By centralizing various disparate data sources, data orchestration tools help companies better understand the scope of their data and improve its governance.
- Enhancing compliance. Data orchestration helps companies comply with various international privacy laws and regulations, many of which require companies to demonstrate the source and rationale for their data collection.
- Positioning the company for scale. As data volume grows, scheduling becomes critical to successfully managing your data ingestion and transformation jobs. Data orchestration enables data teams to easily understand, prepare, and manage pipelines at scale.
How Data Orchestration Works
When you’re extracting and processing data, the order of operation matters. Data pipelines don’t require orchestration to be considered functional—at least not at a foundational level. However, once data platforms scale beyond a certain point, managing jobs will quickly become unwieldy by in-house standards.
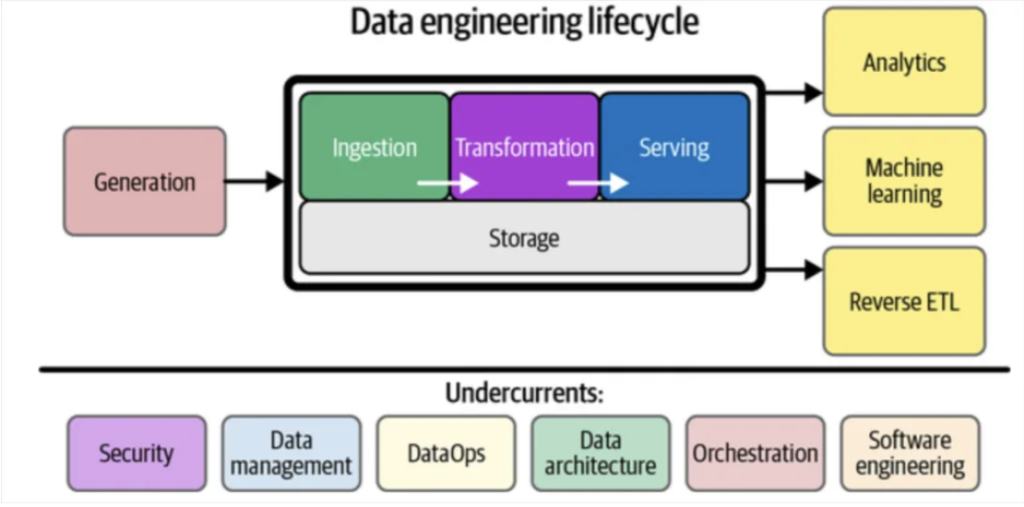
Data orchestration brings automation to the process of moving data from source to storage by configuring multiple pipeline tasks into a single end-to-end process.
3 steps of data orchestration
- The organization phase, in which data orchestration tools gather and organize data pipelines.
- The transformation phase, in which various fragmented data is converted to a consistent, accessible, and usable format.
- The activation phase, in which data orchestration tools deliver usable data for transformation and visualization.
While data orchestration tools might not be required for a pipeline to be considered “functional,” they’re nonetheless an essential component of the modern data stack, and serve as the connective tissue among various data warehouses.
A good modern orchestration tool will be cloud-based to support the modern data stack and user-friendly enough to be leveraged by domains like marketing outside the data engineering team.
So, who’s responsible for data integration? While data integration and data pipeline architecture has traditionally been a responsibility of the data engineering team, the popularity of data mesh architectures has led some teams to share this responsibility with domain leaders as well to facilitate federated data ownership. While that’s certainly not a requirement for data teams—and is even pretty hotly debated amongst data leaders—whether or not you ascribe to a mesh architecture will undoubtedly impact what orchestration tooling is right for your team.
4 Benefits of Data Orchestration Tools
Data orchestration tools can yield significant benefits for organizations—from driving efficiency across the data team to improving relationships across business domains. Let’s take a look at a few of those benefits in detail.
1. Automating data workflows
Nowadays, every company is effectively a data company—and with more and more data pipelines to manage, data engineers are spread increasingly thin. Automating data workflows makes data usable more quickly and enables data engineers to focus on more higher-value tasks that drive ROI for the organization.
2. Eliminating data silos
Siloed data can be a real problem. While siloes often develop naturally as organizations scale, resolving data siloes is rarely as straightforward. Migrating to a single location is often unrealistic for most companies, but not addressing siloes can complicate everything from pipeline management to data governance. Data orchestration enables data leaders to remove data silos without depending on manual migration. Centralizing data and making it accessible also supports better data governance and compliance.
3. Faster time to insights for data analysts
A huge value that data orchestration tools provide is time. Data orchestration takes inaccessible and inconsistent data and makes it organized and usable in real-time. This means analysts can easily leverage the most current data without engineering bottlenecks, delivering faster insights for critical business use cases.
4. Unlocking data across business domains
Teams across business domains increasingly rely on data to make informed and mission-critical decisions. While that’s no doubt good news for your data team, data will often find itself in various domain silos as a result. Data orchestration breaks down those barriers, enabling greater visibility for your data team and greater cross-functional analysis for business leaders across the organization.
Common Data Orchestration Challenges
While data orchestration is certainly helpful in centralizing siloed data and speeding actionability, it’s also not without its challenges. From increasing complexity to introducing new data quality risks, understanding the challenges inherent to pipeline automation will enable your data team to maximize the value of your data orchestration tooling.
Increased orchestration process complexity
Obviously, one of the primary benefits of data orchestration tools is the ability to reduce complexity within an organization’s pipeline operations. But even with the most advanced tooling, pipelines can still become complex. Sometimes just the act of introducing new tooling can add to that complexity. Having a clear understanding of your goals and the needs of your stakeholders will help you respond quickly as complexities arise.
Lack of compatibility with disparate data tools
In order to function effectively, data orchestration tools need to integrate with every data repository within an organization. When that can’t happen, it creates gaps in not just your ability to manage your pipelines but your ability to fully-realize their value. Selecting managed cloud solutions that integrate with existing, scalable tooling—and proactively managing tech debt—will enable you to maximize compatibility and leverage the greatest value from your data orchestration tooling.
Data quality issues introduced by faster data workflows
Accessible data doesn’t necessarily correlate to reliable data. As data moves more quickly through pipelines and analysts depend on it for more real-time use-cases, the importance of both data integrity and data reliability increases exponentially.
The best time to deal with a data quality incident is before it happens. And those incidents will be coming fast and furious as your pipeline velocity increases. Utilizing an end-to-end data observability tool will provide immediate quality coverage as pipelines grow and provide a platform for deeper quality coverage as SLAs are established for specific pipelines.
Keeping up with regulations and compliance. Data orchestration facilitates data compliance by offering businesses more control and oversight of their data sources. However, as with data quality, when it comes to compliance all that speed can come at a cost. Automation should be established with regulations in mind on the front end to ensure customer data is only being ingested and stored when and how it’s legally permissible to do so.
6 Popular Data Orchestration Tools
If you’re looking to add a data orchestration tool to your data stack, you’re in luck. As the data landscape continues to evolve, new data orchestration tools are evolving with it. For data teams considering their first orchestration tool, there are multiple open-source, cloud-based, and user-friendly options to scratch the itch. There are even a few free solutions if you’re into that sort of thing.
What is Apache Airflow?
Apache Airflow is a free open-source platform, originally created at Airbnb, which is designed to develop, schedule, and monitor batch-oriented workflows. All Airflow workflows are defined in Python code, which makes pipelines more dynamic and keeps workflows flexible and extensible. Airflow integrates easily with multiple technologies and systems, which makes it an ideal solution for scaling platforms. And because Airflow is open-source, users benefit from a cache of components created and tested by engineers around the world.
What is Metaflow?
Metaflow is a free open-source platform, originally created at Netflix, that provides a centralized API to the entire data stack. A “human-friendly Python library,” Metaflow makes developing and deploying various data projects easier. When used as a data orchestration tool, Metaflow facilitates the construction and local testing of various workflows. This one’s ideal for data teams working on projects that need to scale or with multiple layers of complexity.
What is Stitch Data Orchestration?
Stitch is a cloud-based open-source platform that powers fast-moving data. This user-friendly solution enables companies to move data quickly without coding, and integrates easily with over 140 data sources. Pricing varies, with a standard package starting at $100 per month, while the premium package, designed for companies with high volumes of data that need top-tier security, costs $2,500 per month.
What is Prefect?
Prefect calls itself “air traffic control for your data.” This solution leverages an open-source Python library, which makes scheduling, executing, and visualizing data workflows easier. Some of Prefect’s unique features include code as workflows, dynamic and flexible workflows, a comprehensive orchestration platform, and a customizable UI. Prefect is free for personal use and starts at $450 per month for enterprise.
What is Dagster?
Dagster is a cloud-native open-source data orchestration tool that’s created for use at every stage of the data development lifecycle—including data testing and debugging. Designed for self-service, Dagster grows with users, meaning it’s helpful for even the least tech-savvy of consumers. While users can get started for free with Dagster, enterprise-level accounts will require custom pricing.
What is Astronomer Data Orchestration?
Astronomer is an open-source, cloud-native data orchestration platform powered by Apache Airflow. Astronomer is designed to empower users to focus on their pipelines rather than their Airflow instance. Among its benefits, Astronomer enables faster data pipeline development, increases data availability, and facilitates a comprehensive view of the data landscape. Users can get started with a free 14-day trial.
How to Ensure Data Trust Across ETL Orchestrated Pipelines
Like every layer of the data platform, data orchestration can’t exist in a vacuum. While data orchestration presents plenty of benefits for the modern data stack, it also presents a few challenges as well. If you’re investing in data orchestration, leveraging data observability is critical to the success of your data pipelines.
There’s no doubt that orchestrating data delivers faster speed to insights; but it’s not just the data that will be moving faster through your pipelines. As pipeline velocity increases, the speed of data quality issues will too.
When data quality issues arise, end-to-end data observability gives data teams at-a-glance visibility into the upstream and downstream dependencies affected by orchestration. And as your data orchestration grows, automated data quality checks ensure that your quality coverage grows right along with it.
Ready to drive even more value from your orchestration tooling? Learn how Monte Carlo can scale data reliably across your entire pipeline and ensure high-quality data at the orchestration level and beyond.
Our promise: we will show you the product.
Read more posts.





