Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Introducing the New ABCs of Data


Alexa Grabell
Alexa is a member of Monte Carlo's Growth team. She is currently pursuing her MBA at The Stanford University Graduate School of Business.
Now that you know your ABCs, next time won’t you ETL with me?
In 2020, it’s simply not enough to collect data about your company to be “data-driven”; to stay relevant, you must also know how to apply it. Underlying this evolution from gut-based decision making to data-driven analytics is a critical need to reason about this data intelligently across your business.
In many ways, the data industry is at a similar stage to where software engineering (and, more specifically, Developer Operations, or DevOps) was about a decade ago. Just now are data teams understanding the importance of automated tooling, eliminating data downtime, and perhaps, most importantly, ensuring high data reliability. In fact, over the past few years, we’ve found that the best data organizations are applying a software engineering mindset to maintain their competitive edge.
In this article, we walk through the ABCs of data, providing an overview of the top terms and concepts today’s data teams need to know:
Data Analytics
(n.) [Pronounced: an-l-it-ks]. See: Data Analyst. An emerging discipline for the collection, integration, analysis, and presentation of large-sets of information to generate business intelligence. Data analytics allow functional areas across a company to make smarter decisions with their data.
Data Analyst
(n.) See: Data Analytics. A data team member responsible for supporting the data scientist and engineer; data analyst roles vary depending on your industry and the size of the company, but they are typically responsible for performing data modeling, identifying patterns in data, and designing/creating reports.
Business Intelligence (BI)
(n.) See: Data Analytics. Methods and technologies that gather, store, and analyze organizational data to help companies make better decisions. Generally speaking, business intelligence refers to the output of data analytics (i.e., intelligence for your business).

Like a library catalog, a data catalog tells you where your data is stored and how to access it. Image courtesy of Dollar Gill on Unsplash.
Data Catalog
(n.) [Pronounced: dah-tuh kat-l-awg] An inventory of metadata that gives users the information necessary to evaluate data accessibility, health, and location. Many modern data catalogs are self-serve, making it easy for data teams to pull information about their data and regulate who has access to it.
Data Downtime
(n.) Etymology: Coined by data reliability company Monte Carlo. Periods of time when data is partial, erroneous, missing, or otherwise inaccurate. Data downtime is caused by bad data, data anomalies, and other issues that can corrupt otherwise good data pipelines.
Data Engineer
(n.) A data team member responsible for preparing data. Data engineers import / clean / manipulate raw data, develop / test / maintain infrastructure, marry systems together, and conduct database administration. Data engineers are increasingly replicating best practices from software engineers (particularly DevOps teams) to collaborate on data management trends and automate flows between data managers and downstream data consumers.
Extract, Transform, Load (ETL)
(n.) The general procedure of copying raw data from one or more sources into a destination system which presents the data differently, via:
- Extract: find the data source, make a copy of the data, then load data into memory
- Transform: reorganize data into a form that suits the needs of the end user (reporting, dashboards, ML) by cleaning, formatting summarizing, joining records from multiple sources, and more
- Load: move data into a destination (data warehouse, data lake, etc.)
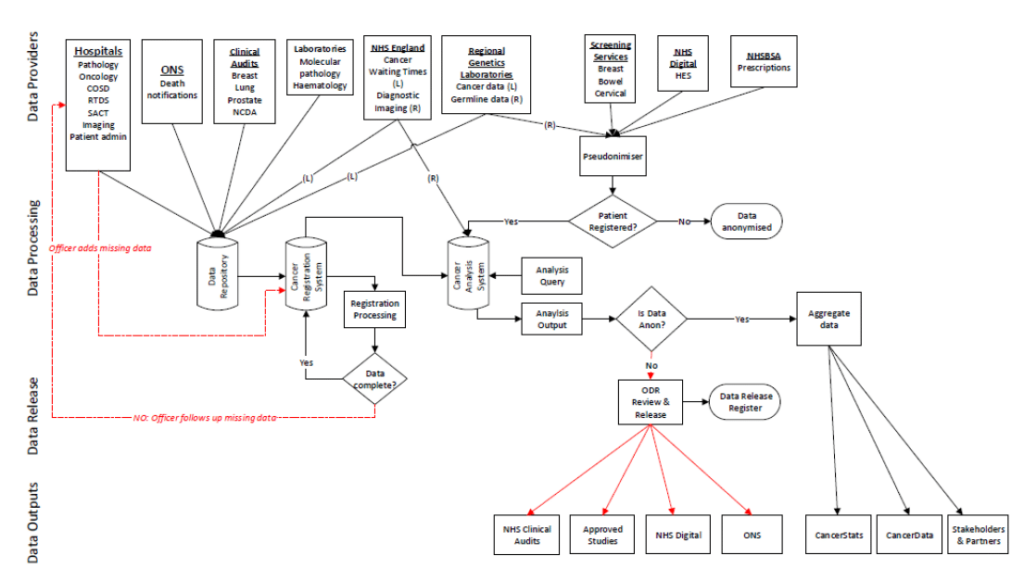
Data Flow Diagram
(n.) A visual means of representing the path of data throughout its lifecycle, often spanning the ETL process across different solutions or steps. This video from SmartDraw does an amazing job of explaining what data flow diagrams are and how to design them.
Data Governance
(n.) [Pronounced: dah-tuh guhv-er-nuhns] The process of managing the availability, usability, and security of data in an organization, frequently based on internal policies and external regulations regarding the application of said data. Buzzy term in the data world due to GDPR, CCPA, and other important pieces of legislation around data compliance.
Data Hub
(n.) A type of data architecture that collects data from multiple sources, similar to a data lake. Unlike a data lake, however, a data hub homogenizes data and may be able to serve data via various formats.
Data Ingestion
(n.) [Pronounced: dah-tuh ĭn-jĕs′chən ] The process of acquiring and importing data for use, either immediately or in the future. Data can either be ingested in real-time or in batches.
Data Join
(n.) The process of combining two data sets, side-by-side, such that at least one column in each data set must be the same.
Knowledge
(n.) See: Business Intelligence. The outcome of applying ETL to data as a means of generating actionable and understandable insights based on raw information. The Data, Information, Knowledge, and Wisdom (DIKW) hierarchy elaborates on the distinction and correlation between data and knowledge. A data team is responsible for transforming data into knowledge for use by their broader enterprise.
Data Lake
(n.) A vast pool of raw data for a purpose that is not yet defined, usually stored as object blobs or files. See: data lake vs data warehouse.
Database Management System (DBMS)
(n.) [Pronounced: dah-tuh-beys man-ij-muhnt sis-tuhm] A software application or package designed to manage data in a database, including the data’s format, field names, record structure, and file structure. DBMS’ come in a variety of flavors depending on the users’ industry or discipline.
Data Mart
(n.) A form of a data warehouse that focuses on a single functional area (i.e., sales, finance, marketing, etc.).
Data Mesh
(n.) [Pronounced: dah-tuh mesh ] Etymology: originated in Zhamak Dehghani’s landmark ThoughtWorks article on the distributed data mesh. A type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-service design. Relies on ensuring universal data reliability at all points of the entire architecture and stages of the data life cycle.

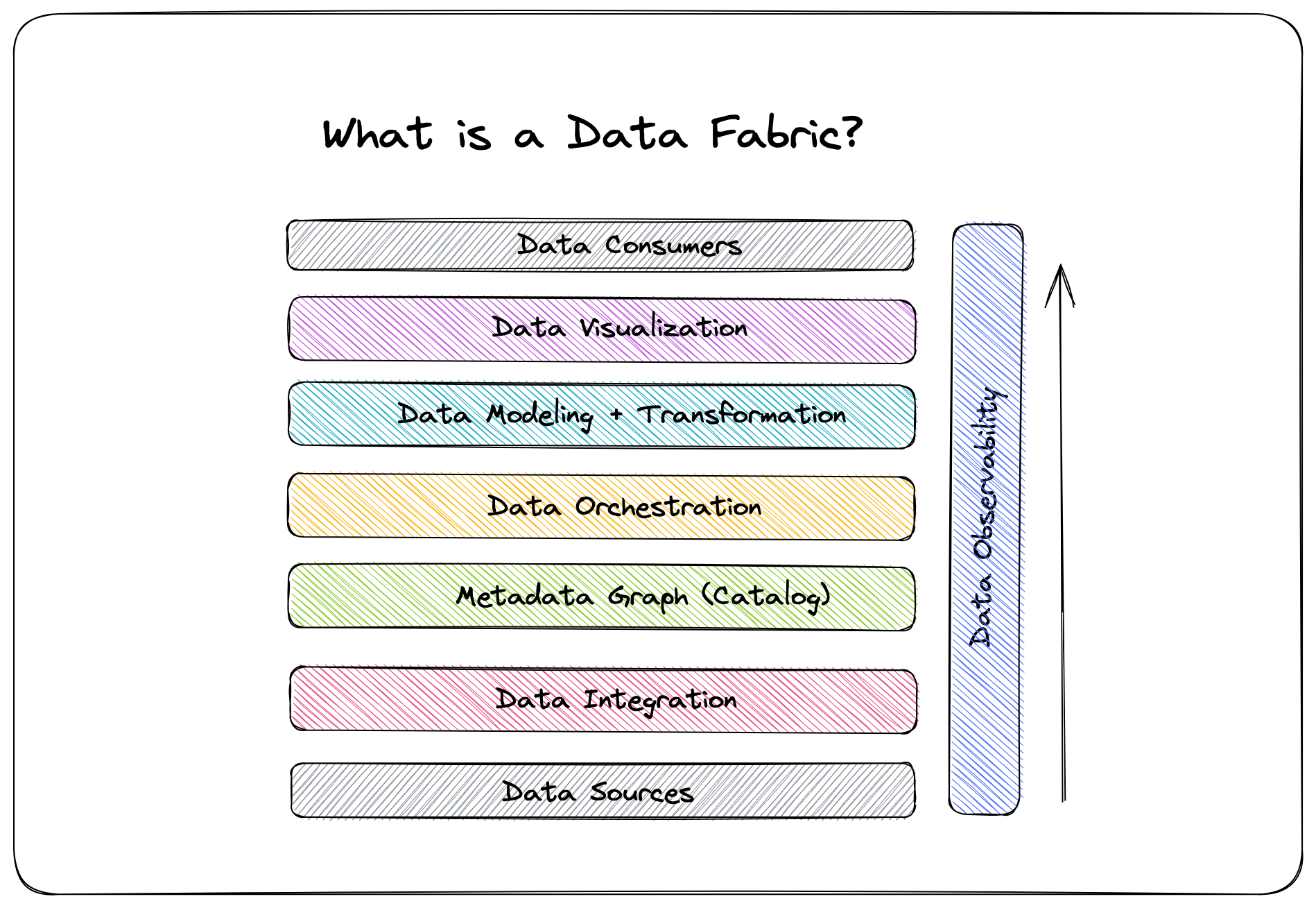
Data Observability
(n.) [Pronounced: dah-tuh uhb-zur-vuh-buh-luh-tee] Etymology: Inspired by the software engineering practice of observability. An organization’s ability to fully understand the health of their data over its entire life cycle and surface data downtime incidents as soon as they arise; includes ability to understand the five pillars of data observability:
- Freshness: how up-to-date data tables are and the cadence at which tables are updated
- Distribution: if data’s possible values are within an acceptable range and format
- Volume: completeness of data tables and insight on the health of data sources
- Schema: changes in organization of data and health of data ecosystem
- Lineage: which upstream and downstream ingestors are impacted and which teams are generating data and accessing it
Data Operations (DataOps)
(n.) A discipline that merges data engineering and data science to support an organization’s data needs, much in the same way developer operations (DevOps) helped scale the software engineering field (version control, iterative agile development, collaboration, etc.). Automation is increasingly playing an important part in the DataOps practice re: addressing data downtime, akin to how automated tools help DevOps teams ensure high application uptime and minimize downtime.
Data Platform
(n.) A central repository for all data, handling the collection, cleansing, transformation, and application of data to generate business insights. A must-have re: scalability and sustainability for large data organizations.
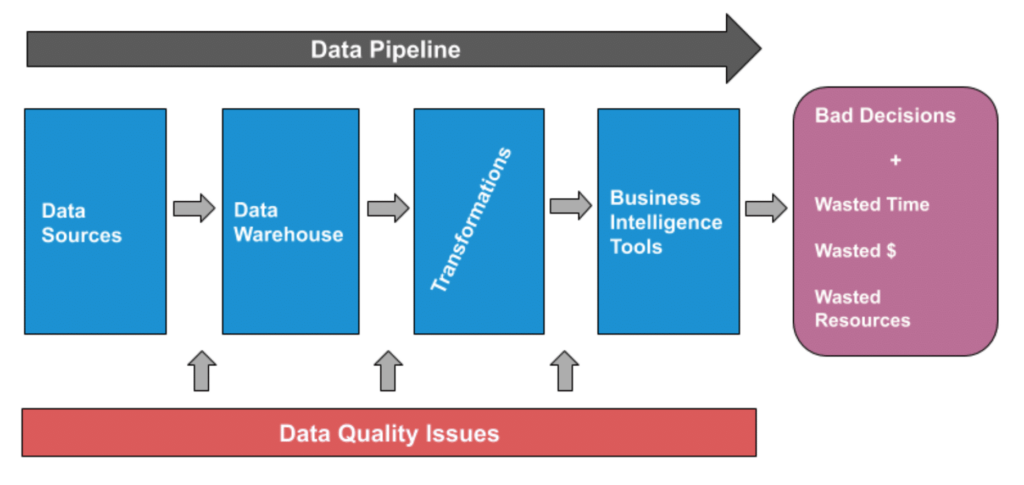
Data Quality
(n.) The health of data at any stage in its life cycle. Data teams can measure data quality through a simple data quality KPI that calculates data downtime. Data quality issues can happen at any stage of the data pipeline.
Data QA Testing
(n.) See: data quality.The maintenance of a desired level of data quality for a given service or product.
Data Reliability
(n.) [Pronounced: dah-tuh ri-lahy-uh-bil-i-tee] Having full confidence in data’s accuracy and consistency over its entire life cycle. In short: if data is not reliable, it cannot be trusted. Modern data organizations rely on data reliability to increase revenue, save time, make smart decisions with their data, and ensure customer trust.
Data Scientist
(n.) A data team member responsible for analyzing and interpreting data. Data scientists provide insights and answers to key business questions via quantitative means. Increasingly, data scientists are tasked with building ML algorithms to make predictions about the business.
Data Source
(n.) The location where data originates from (file, API feed, database, SaaS application, etc.).
Data Table
(n.) A way of displaying data in a grid-like format of rows and columns, generally organized in relation to X and Y axes.
User Interface (UI)
(n.) [Pronounced: yoo-zer in-ter-feys] The means through which a user and a computer system interact. In the context of data analytics, a UI presents an easy to digest way for consumers to understand data, insights, and knowledge in a given data store.

Data Visualization
(n.) [Pronounced: dah-tuh vi-zhoo-uh-lai-zei-shn] The graphic representation of data, often incorporating images that communicate relationships between data points. Data lineage is a helpful and increasingly popular form of data visualization for mapping connections between upstream and downstream data sources, i.e., in the case of data downtime.
Data Warehouse
(n.) A central repository for structured, filtered data that has already been processed, often for a specific purpose. Cloud based data warehouses are often referred to as modern data warehouses.
X-value
(n.) See: data table. The horizontal value in a pair of coordinates, whose value is determined by measuring parallel to the x-axis.
Y-value
(n.) See: data table. The vertical value in a pair of coordinates, whose value is determined by measuring parallel to a y-axis.
Data Zone
(n.) Not to be confused with the “danger zone,” data zone refers to sub-sections of a data lake that correspond to the format of the data (i.e., raw, structured, transformed, etc.).
What’s next for data teams?

We anticipate that over the next decade, the data industry will witness an explosive growth of the DataOps field. Much in the same way that New Relic, DataDog, and Honeycomb have taken the site reliability and observability fields by storm, DataOps is ripe for its own movement centered around the core concepts of data reliability and observability.
As organizations generate more and more data, data infrastructure and workflows will only increase in complexity, requiring data teams that can ensure data trust across your entire company.
What data trends are you excited about? Schedule a time to talk to us and/or request a demo with a few clicks.
Our promise: we will show you the product.
Read more posts.