Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Fabric: The Future of Data Architecture

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Despite its prevalence, data can be messy, siloed, ungovernable, and inaccessible—especially to the non-technical employees who rely on it.
Enter data fabric: a data management architecture designed to serve the needs of the business, not just those of data engineers. A data fabric is an architecture and associated data products that provide consistent capabilities across a variety of endpoints spanning multiple cloud environments.
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of data architecture.
If data fabric is the future, how can you get your organization up-to-speed? In this post, we’ll discuss what, exactly, a data fabric is, how other companies have used it, and how you can build one at your company.
Table of Contents
- What is a data fabric?
- The 4 Pillars of a Data Fabric Architecture
- Data Fabric Use Cases
- How Monte Carlo Can Complement Your Data Fabric
- Frequently Asked Questions
What is a data fabric?
A data fabric isn’t a standalone technology—it’s a data management architecture that leverages an integrated data layer atop underlying data in order to empower business leaders with real-time analytics and data-driven insights. Multiple sources of distributed unstructured data across an organization are no problem with this type of data architecture—the data fabric serves as connective tissue across all touchpoints, uses sensors to process data, and rapidly generates usable insights from that data. A data fabric offers unity in a formerly disconnected, incompatible data environment.
Multiple benefits characterize the data fabric. These include:
Seamless integration
A data fabric’s ability to integrate seamlessly with various APIs and software-delivery kits (SDKs) truly differentiates this framework from another type of data management: the ubiquitous data lake. According to this Spiceworks article, “Interoperability between components and integration readiness are defining traits of this design.” By its very nature, data fabric is intended to integrate easily with various platforms and tools, and this flexibility makes the architecture inherently scalable.
Improved security and governance
When data resides in multiple places in multiple forms across an organization, governing that data and ensuring its security is a constant challenge. A data fabric infuses data governance and security across all forms of data, no matter its origin or destination within the organization.
Bob Muglia, former CEO of Snowflake, points to the need for universal standards for data governance, lineage, and metrics as he looks to the year ahead in data engineering, and he champions the use of data fabric in pursuit of this endeavor. “That’s a model worth looking at when it comes to data governance,” says Bob. “It’s a very good template to actually think through how to build some of these [governance standards].”
Reduced reliance on IT
Integral to a data fabric is a set of pre-built models and algorithms that expedite data processing. The upside to these pre-configured models is twofold: first, it means business users can derive and use insights from corporate data more quickly, and second, it means companies don’t need to rely on their IT departments to make sense of data as regularly.
Part of the beauty of the data fabric is its ease of use and accessibility for multiple constituents within an organization, including business users who are not a part of the data engineering team.
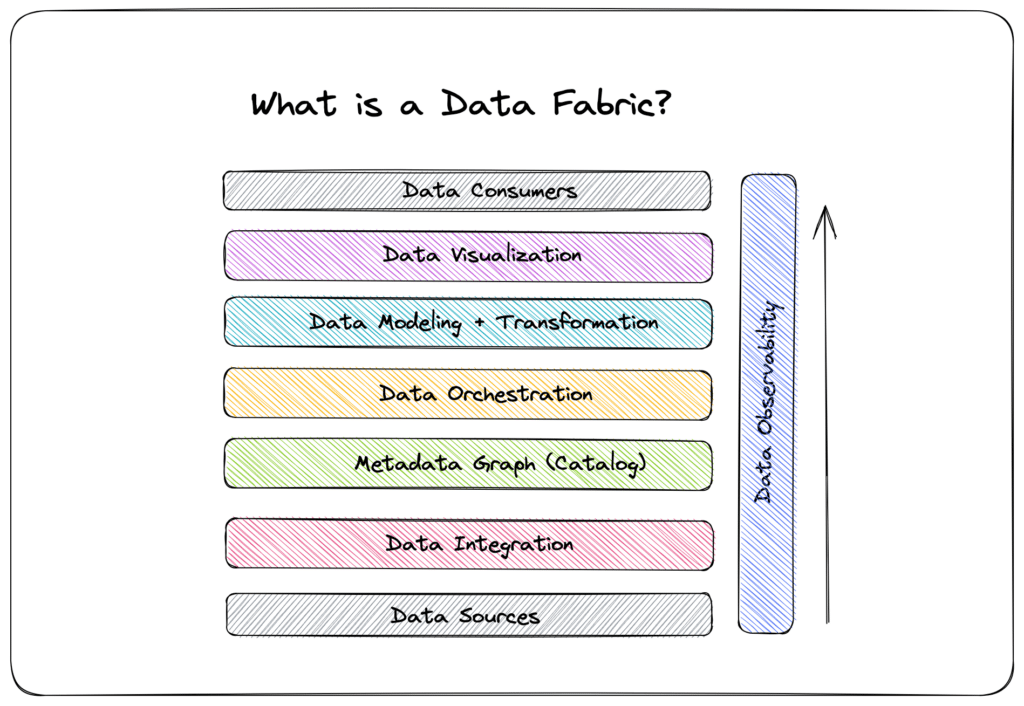
The 4 Pillars of a Data Fabric Architecture
Data fabric is flexible, extensible, and customizable—compatible with various hosting environments and platforms, and a seamless addition to nearly any tech stack. As such, each data fabric looks a little different.
Four commonalities, however, unite all data fabrics. Like other data architectures, such as data mesh, all data fabrics must embody a set of four critical components:
- Data fabric must collect and analyze all forms of metadata
- Data fabric must convert passive metadata to active metadata
- Data fabric must create and curate knowledge graphs
- Data fabric must have a robust data integration backbone
- What does that mean as you build a data fabric at your organization?
Collect and analyze all forms of metadata
A key benefit of a data fabric is its ability to analyze and leverage data-related information quickly and easily across both structured and unstructured data at various points of origin. As your team builds your data fabric, make sure you have a designated way to collect the various metadata associated with your data inputs.
For example, your data fabric should be able to understand whether incoming data is technical, business-related, operational, or social. It will be important to use this context to generate the analysis and insights upon which the business team will depend.
Build a graph model based on the metadata
If a data fabric is designed to meet the needs of the business and to empower business users to leverage data seamlessly, it’s essential that this data architecture can turn unstructured metadata into information business users can understand.
That means your data fabric should be constantly ingesting, analyzing, and leveraging metadata through graph models that present that metadata in an easily digestible, user-friendly way. Because data fabric also takes advantage of AI and machine learning algorithms, the system will get smarter over time and will eventually have the ability to use the insights it gathers from metadata to make more sophisticated data management predictions and recommendations.
Construct knowledge graphs to add depth and meaning
As you build your data fabric, you must keep ultimate usability front-of-mind. The next step in constructing an eminently usable data architecture is to build knowledge graphs, which infuse a semantic layer over your data. That, in turn, makes the data easier to interpret, analyze, and act upon.
This semantic layer is a particular bright point of the data fabric, which consistently makes all types of data—structured and unstructured, business and operational, etc.—coherent and ready-to-use.
Support all types of data users with integrations
To ensure the successful adoption of your data fabric, you first need to ensure all data users across the organization can easily access and utilize the data housed within it.
Your data fabric must integrate seamlessly with all types of data delivery styles (ETL, streaming, replication, messaging, data virtualization, etc.), should support your own data engineering team members, and must empower self-service from business users. A successful data mesh connects with any type of front-end user’s UI and enables them to gain the insights they need to make business decisions quickly and confidently.
Without this integration-readiness, front-end connectivity, and automatic insight delivery, your data fabric will not, in fact, be a data fabric after all—it will be little more than a data lake.
Data Fabric Use Cases
While data fabric is still growing in popularity, several well-known enterprises have already leveraged this framework to improve their data management.
Domino’s

Global pizza chain Domino’s has been lauded as “the poster child for digital transformation.” The company famously and successfully digitized its business, enabling customers to order food, track delivery status, earn rewards, and more via the company’s website and app. Frequent customer communication and personalization are key to Domino’s success.
Implicit in Domino’s model is its reliance on multiple types of data from multiple sources. To integrate and unify that distributed data, Domino’s implemented a data fabric. That data architecture has enabled Domino’s to implement end-to-end tracking across the data lifecycle, from point of sale systems to supply chain centers and across all marketing efforts.
Ducati

Ducati, an Italian motorcycle manufacturing company, gained competitive advantage by leveraging a data fabric across its operation. According to Ducati’s data fabric partner NetApp, “This is a quality-over-quantity story. Ducati’s advantage lies in the volumes of valuable performance data that help drive innovation. And this innovation ultimately creates bikes that the competition can only dream of.”
Ducati built a data fabric that leveraged data collected by sensors installed on each of its motorcycles. The framework enabled the company to improve data management and accelerate development as it gleaned information from its thousands of “connected bikes.”
How Monte Carlo Can Complement Your Data Fabric
A growing number of companies are considering data fabric as their data architecture of choice, because a growing number of companies are becoming increasingly reliant on various forms of data coming from various touch points across the organization. In order to optimize data management and build the best possible data management architecture for your organization, it’s first essential to ensure your data is as reliable as possible.
As you set out to build your company’s data fabric, Monte Carlo can help. Our data observability platform makes data more reliable at each endpoint in the data fabric, from ingestion in the warehouse or lake all the way through to the BI layer.
When you’re working with more reliable data, you can reduce the amount of time it takes to detect and resolve data quality issues. You can gain visibility into what data truly matters and what can be deprecated. What’s more, you can understand how data is truly being used at your organization—and by whom.
When you can ensure your end users will work with reliable data, you can expedite adoption and time-to-value for data catalogs. You can also feel confident that users at your organization will more readily adopt your data fabric, because they’ll know they can trust the insights it generates.
Ready to get started building your data fabric with reliable, high-quality data you can trust? Reach out today to learn how Monte Carlo’s data observability platform can help.
Our promise: we will show you the product.
Frequently Asked Questions
What is the future of data fabric?
The future of data fabric involves becoming the primary data management architecture as organizations increasingly rely on varied data sources. It will enhance data integration, governance, and accessibility, empowering business users and reducing reliance on IT.
What is data fabric in layman’s terms?
Data fabric is a data management system that connects and integrates data from various sources within an organization, making it easily accessible and usable for business insights and decision-making. It acts like connective tissue, ensuring that data is consistent, secure, and readily available across the entire organization.
What problem does data fabric solve?
Data fabric solves the problem of fragmented and siloed data within organizations. It unifies and integrates data from multiple sources, ensuring consistent, secure, and accessible data management.
Read more posts.