Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage From Concept to Reality: Migrating to Data Mesh at BairesDev with Databricks and Monte Carlo

Jon So
Head of Product Marketing at Monte Carlo.
Software solutions company BairesDev provides leading businesses around the world with technology teams on demand. Enterprise organizations like Google, Johnson & Johnson, Pinterest, and Rolls-Royce have taken advantage of BairesDev’s powerful network of talent to solve complex technical challenges.
But, like every company, BairesDev had problems of its own to solve. As one of the fastest-growing outsourcing companies in tech, the firm was facing big challenges around data management, with over 4,000 professionals distributed across more than 40 countries.
To address these issues, the newly formed data engineering team decided to use a data mesh approach to improve data quality, availability, and performance across the organization. We recently sat down with Matheus Espanhol, Data Engineering Manager at BairesDev, and the team at Databricks to learn exactly how his team forged their path to a data mesh.
Quick recap: what is a data mesh?
For a quick refresher, a data mesh is an architectural framework that uses a distributed, domain-specific approach to data management.
Data mesh framework follows four key principles:
- Domain ownership: Data domains need to host and serve their domain datasets in an easily consumable way.
- Data as a product: Apply product thinking to data to ensure that data is easily discoverable, easily read, easily understood — while also applying product principles such as versioning, security, monitoring, logging, and alerting.
- Self-serve infrastructure: Use tools and user-friendly interfaces to develop analytical data products for both analytical end users and development teams.
- Federated governance: Develop overarching rules and regulations to govern operations through computational policies and services.
Here’s why — and how — BairesDev chose to migrate to a distributed data mesh architecture.
More data, more problems at BairesDev
Like many rapidly scaling organizations, in early 2021, BairesDev was dealing with growing pains. To address their data issues, the research and development arm of the company began building a data engineering team from scratch.
The new team conducted internal interviews with different business units to understand the challenges. They found some common pain points:
No cohesion in tech or processes
Different pipelines were being built with different technologies by different teams, creating duplication and inconsistencies across the organization. There was no data catalog or centralized metadata management in place to help facilitate data discovery, and poor availability was a frequent roadblock.
Lack of trust in data
Consumers didn’t trust the data, especially when other teams were producing it. Complaints of data quality issues were rampant, and there was no data observability in place to help manage and improve reliability.
Most domains may have had some good practices and non-formal agreements in place around data privacy and access, but since there were no global standards in place for policies or workflows, there was little confidence in data quality across domains.
Data performance couldn’t keep up
Analytical workloads were struggling to support the company’s growth, with performance and concurrency issues cropping up regularly.
Tackling technical and organizational problems
The BairesDev team decided to use the data mesh model to rebuild their data platform and team structure. “The data platform is not only to solve technical problems but also to reduce the complexity of organizational and culture changes,” said Matheus.
To address both organizational and technical challenges, his team looked at each domain’s roles and responsibilities and worked to solve the specific problems each team was facing. Rather than starting from a centralized place to solve all the problems at once, they looked at each team and tried to find solutions they could reuse across domains — looking at each of the four data mesh pillars to guide their efforts.
Domain ownership
Defining the boundaries of different domains and identifying key owners allowed the data engineering team to build on the strong culture of autonomy already in place at BairesDev.
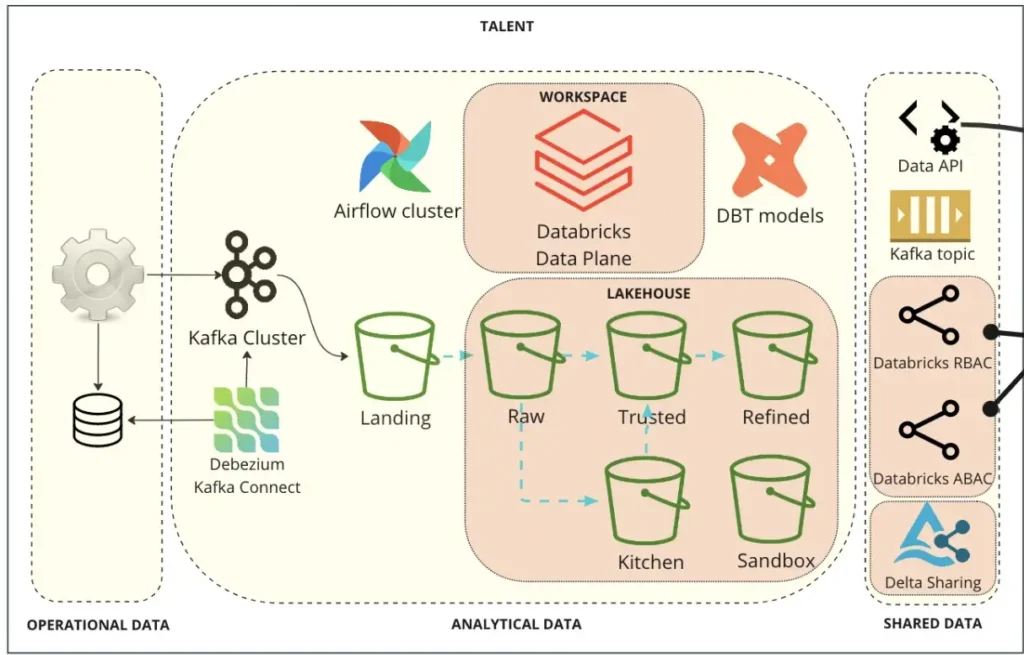
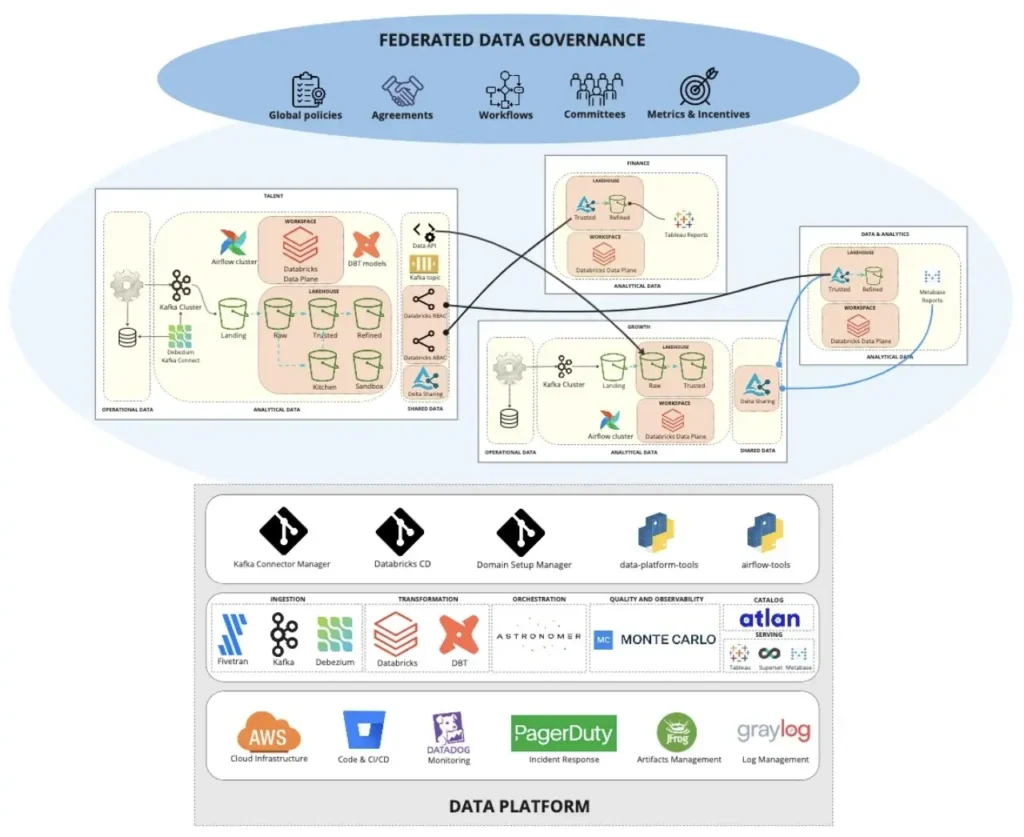
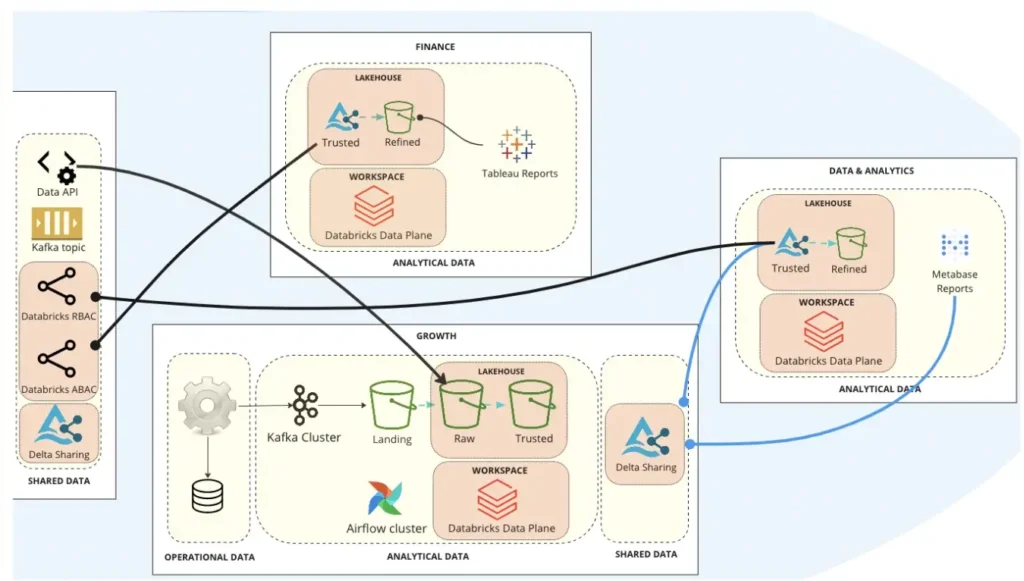
The team provided each domain with the components they needed from the larger data platform to reach their goals, and to store data locally. This helped keep the team’s autonomy intact while cutting down on the duplication and inefficiencies that plagued the pre-mesh paradigm at BairesDev.
As Matheus describes, the diagram above shows an example of how a domain-specific data producer sends data from relational databases to Kafka Cluster, then stores data in S3 buckets within the domain’s AWS account. They can transform the data (either in batch or streaming) in their own Databricks workspace, and conduct modeling in their dbt repositories. Depending on the data consumers that need to receive the data, the domain team can use the appropriate tools, like APIs, Kafka, or Delta Sharing.
Data as a product
To introduce a “data as a product” approach, Matheus and his team worked with domain-specific data producers to establish capabilities for sharing data across domains. This could include making data available to end consumers such as other applications, other Databricks warehouses, or BI tools.
Federated governance
The data engineering team worked with domains to start establishing global standards and processes. But with domain-specific ownership, that wasn’t an easy task.
“Governance seems to be the hardest to implement because of the decentralization,” said Matheus. “So we needed a lot of automation to make sure domains will follow global policies defined by the company or even local policies defined in the domain.”
BairesDev implemented Monte Carlo’s data observability platform to help automate data quality standards without overwhelming teams or undercutting autonomy. Each domain team had data operations leads who received access only to their own data sets within Monte Carlo. Within the data observability platform, they could manage incidents, evaluate findings, and receive targeted notifications and alerts via PagerDuty or domain-specific Slack channels.

Self-serve platform
The data engineering team worked with each domain to understand their needs and define the scope of the self-serve data platform they would require. Matheus and his team used out-of-the-box tooling to help accelerate time-to-value whenever possible, including Databricks as a data lakehouse, Kafka Connector Manager to automate replication setup, and Terraform to provision components for the domains in a standardized way.
How data mesh improved data availability and reliability
This distributed, domain-specific approach to a data platform architecture helped BairesDev scale its analytical workloads and rebuild trust in data.
Teams retained their autonomy, and the self-service platforms meant domains were more easily able to share and discover data across the organization. Thanks to the newly federated governance and automated observability tooling, teams had more trust in the greater volumes of data they were now able to access.
The lessons BairesDev learned about implementing data mesh
Implementing a new data platform architecture wasn’t all smooth sailing, of course. Matheus described a few key lessons he and his team took away from their crash course in data mesh.
Lesson 1: There will be pushback
A few common objections popped up across BairesDev as the data engineering team worked with domain owners to rebuild their data platform — and Matheus developed answers for each of them.
Objection: “Building a data mesh isn’t my priority right now.”
Response: Identify the current problems the domain teams do care about, and articulate how data mesh could help solve them.
Objection: “We don’t have the skills on our team to do this work.”
Response: The data engineering team took on the implementation work themselves, and helped any domain team who needed extra resources to hire the right people once the new platform was up and running.
Objection: “This kind of data platform is way more than we need.”
Response: Each domain team received a dedicated data engineer to function as a “customer success” manager for the domain’s project, helping the domain team solve challenges and see value from the new platform right away.
Objection: “This will bring the kind of learning curve that will delay my projects.”
Response: Matheus and his team developed capabilities to help accelerate adoption, and prioritized using technologies that would help provide value right out of the box.
Lesson 2: Don’t build everything from scratch
Knowing that time to value would be a huge concern from domain teams, Matheus and his data engineering colleagues chose to build their stack from managed data tools whenever possible.
If specific data pipelines needed custom technology, the team supported them — but by using tried-and-true solutions for their core platform, they were able to reduce the scope and timeline of the buildout.
“With so many capabilities to deliver at the same time to start onboarding domains, we realized it would take too much time for starting to deliver value to the business,” said Matheus. “We chose managed data tools like Databricks, Monte Carlo, Fivetran, Astronomer, and Atlan to avoid wasting time keeping the services running, and prioritize the development of things that each domain really needed to develop their data pipelines.”
Embark on a data mesh journey, just like BairesDev
Ultimately, using a data mesh framework helped BairesDev solve meaningful problems around data consistency, quality, and availability within their organization. Despite the challenges that teams raised in the face of this new framework, by focusing tightly on the problems that were most important to their stakeholders, Matheus and his team were able to create buy-in and deliver on the promise of data mesh.
Curious how data observability and other principles of data mesh could help improve your team’s approach to data management? Reach out to the Monte Carlo team to learn how to drive adoption and trust of your data mesh with better data quality.
Our promise: we will show you the product.
Read more posts.