Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Why Your Data Incident Management Process Is Broken…And 5 Steps to Fix It.


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Too many teams approach data incident management like a game of group whack-a-mole. Multiple stakeholders from multiple teams swinging wildly at whatever pops up from the incident hole—and occasionally hitting each other in the process.
Whether it’s an unexpected change to the data, a shift in SQL logic, a runtime error, or some other nefarious gremlin in your pipeline, how you manage data quality incidents plays a critical role in both the reliability of your data and—more importantly—the value of it.
One of the primary reasons we struggle to manage data incidents well is because we struggle to define and manage our data products well. Once you understand what your data products are, what goes into them, and how they’re being used, you’ll be better equipped to define what your data incident management process should look like too—and who exactly should own it.
In this piece, I’ll cover why data incident management should (probably) happen at the data product level, how to manage those incidents effectively, and who should be responsible along the way.

Table of Contents
The problem with most data incident management
Like it or not, data quality incidents are inevitable. You could invest in the best engineers and modern infrastructures, but you still can’t always control the quality of the data that runs through your pipelines. That makes the need for a data incident management process inevitable as well.
But just having a process isn’t enough—you also need to have a strategy for how you apply that process to your data pipelines. Great monitors and expertly defined incident ownership applied across the wrong datasets is still the wrong data incident management process.
Too many teams start triaging and managing incidents without sufficient understanding of the goal they’re trying to achieve. They’ll abstract the solution away from the value by managing data quality incidents on an ad hoc basis, and while they’re likely getting better data in some sense, it’s probably not the better data they need.
Ad hoc data incident management is totally reasonable on a small scale. The problem is that your data quality pain won’t stay small forever. If your organization is growing, your data quality pain will be too. And when that time comes, you’ll need a strategy in place to monitor and plugs holes quickly.
There comes a point when the whack-a-mole philosophy of data incident management just doesn’t scale any more. And on that day, you’ll need a way to prioritize, operationalize, and assign responsibility for the data quality incidents that really matter.
Incident management by data product
It’s easy to overcomplicate the data incident management process. We start looking at things like SLAs before we’ve even defined what matters—and WHY. The problem with this approach is that it results in a process that’s simultaneously too broad AND too shallow to be effective.
The solution here is to adjust our thinking—from solving problems to delivering impact. What is it that we need to monitor to add the most value to our organization, and how can we guarantee the quality of that data from ingestion all the way to consumption?
In other words we need to manage incidents at the data product level.
If we define our management by product, not only will we understand what to prioritize, but we’ll understand how to monitor it, who should be involved, and where to look when something goes wrong.
Here’s a quick five-step approach to what that would look like.
5 steps to managing incidents at the data product level:
- Define your critical data products and create monitors.
- Define accountability model: i.e. Data product/you built it, you own it; but also, how to handle inevitable hand-offs across a pipeline.
- Manage communication: Incident owner, dependent teams, consumers; effective escalation and delegation (if you know what your data products are, you know who should be involved).
- Troubleshooting: Finding the root cause of the incident, on-call rotations, minimize time-to-resoution.
- Review incidents: Retros to determine where you can make systemic improvements, both to your data products and to your monitoring, comms, etc.
Now, let’s take a look at those in a bit more detail.
Step 1. Defining your critical data products
Not every asset is a data product—nor should it be. Data products should be limited to those mission critical assets that you’re expected—and prepared—to invest the resources in to maintain.
If you’re part of a large organization like Pepsi, you may have 50 data products that you’re responsible to maintain. If you’re a pre-IPO startup, you may only have three to four.
A good place to start—particularly if you’re a small team—is to find those data products with outsized impact across your organization. These should be data products that are leveraged by multiple teams to support critical business use cases. Some questions you can ask to determine whether you should be managing incidents on a particular data asset include:
- Is this a critical ML model?
- Is it customer facing?
- Is it financial in nature?
- Is this critical for decision making?
- What’s our risk exposure if an incident were to occur in this pipeline?
- How many downstream consumers or teams will be impacted?
Obviously anything public facing needs to be monitored closely—but your critical internal assets are also just as important. Understanding the size and breadth of the impact of an incident on a particular asset will help you identify what products need to be included in your incident management process.
Monitoring your data products
Once you know what your critical data products are, create monitors to cover the production pipelines end-to-end for those data products. Start by tackling a low watermark for your product using automated monitors then scale as needed with additional tools like SLAs and even contracts where needed for specific assets. Creating a low watermark for your monitoring is simple and scalable with the right out of the box tooling.
Of course, just because you haven’t determined an asset to be a data product doesn’t mean you just let that pipeline run amok either. Apply broad ML-powered monitoring for things like freshness, volume, and schema across the full breadth of your environment will allow you programmatically maintain less important tables while you focus on intentionally monitoring those handful of critical assets.
The important thing to remember here is prioritization. Once we have an understanding of the data products to monitor, we can appropriately arrange our resources to provide the right coverage for each product. Which brings us to step two: who actually owns incident management at the data product level.
Step 2: Define accountability
The question of who owns incident management isn’t unique to managing incidents at the product level—but it does make answering that question a whole lot easier.
There’s a reason why baseball players are assigned positions. If the baseball flies into the outfield or skids over to short-stop, they already know who’s responsible for catching it. The same should be true of your incident management process.
Where teams get into trouble is when they fail to define ownership for a particular incident. Without adequately defining ownership, you’ll either end up jumping over each other to catch and remediate—or worse yet, no one catching it at all.
So, the question is: should ownership apply across domains and source owners or within the data team itself? Or both?
A lot of teams will attempt to put in place a hand-off to ops or maintenance teams in order to free up developers for more critical projects. While that can have its advantages, in my experience, nothing works as well as the “you build it, you own it” philosophy (as long as ownership is maintained across teams and not specific individuals).
Context matters in data incident management. In most cases, the data team will be uniquely positioned to support the management and resolution of data incidents because they already have the context to understand the structure of each data product and its dependencies—whether that’s source tables that are leveraged by multiple downstream teams or a data product defined for a specific purpose that’s made up of multiple source systems.
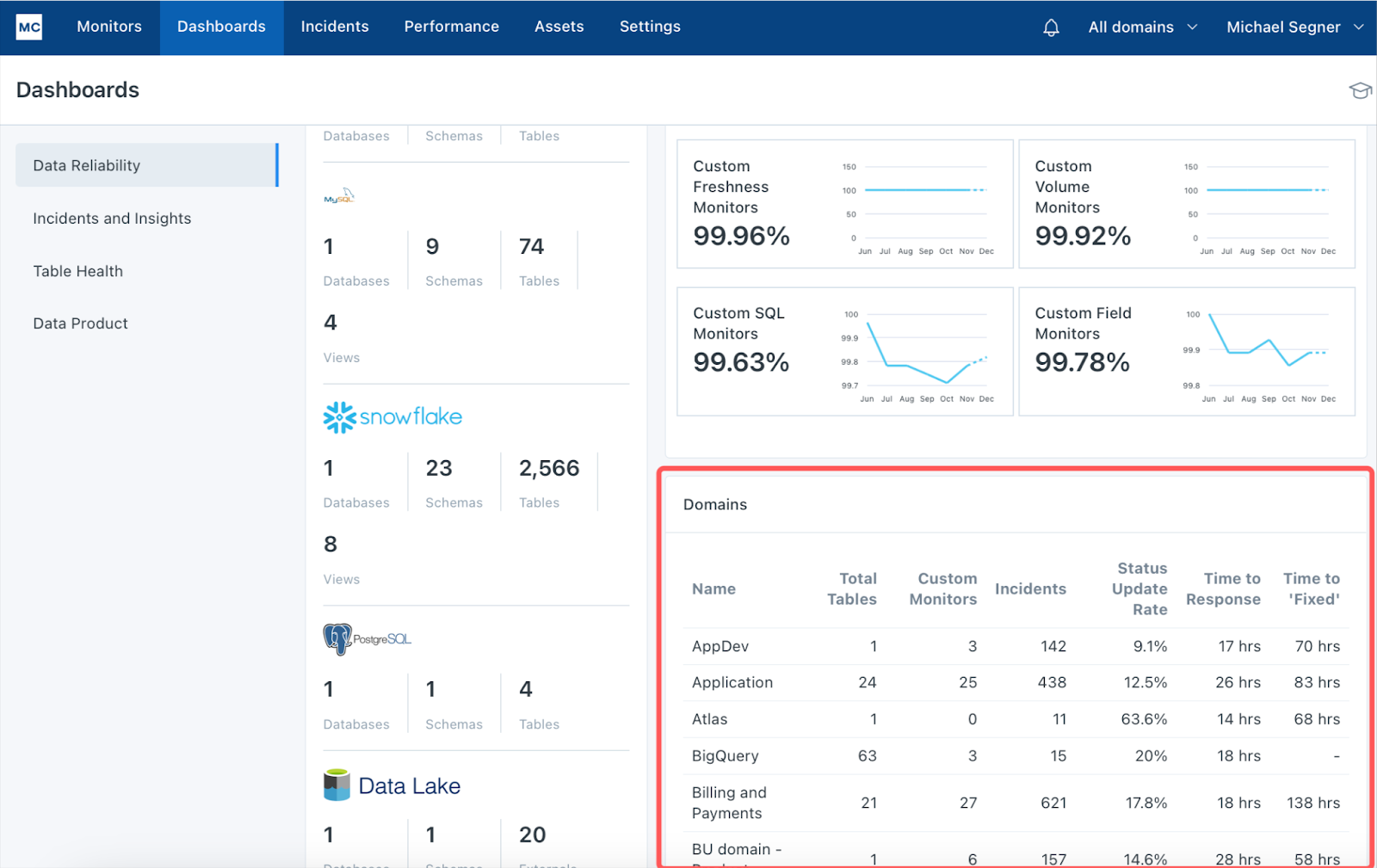
Of course, every data team is different, and every data product is different. So, what’s more important than choosing one philosophy over the other is choosing one philosophy and sticking to it. Where teams get into the most trouble is when they create a spaghetti monster that flings ownership across multiple strategies.
If your data exists in a siloed structure and multiple stakeholders have the power to make changes to the data (like software engineers), horizontal ownership might make the most sense for you. If you have sufficient resources and unilateral control over your data ecosystem, you’ll probably be better served by handling incidents within your own team instead. But whatever you choose, make a proactive decision about how ownership will be assigned and stick to it.
If you choose to maintain ownership within the building team, define your terms. Create SLAs. Assign product owners. Make sure those teams are trained on how to manage incidents effectively (more on that in a second).
If you’re going wider, communicate with the data team to make sure they understand the expectation.
No ownership model is worse than an ownership model that you don’t maintain.
Step 3. Manage communication
The beauty of a clearly defined data product is that you already know how it’s structured and who’s using it. That means you also know exactly who should be informed if something goes wrong.

Look, alert fatigue is real. And managing your incidents by product isn’t the end-all solution to that problem. However, it is a very good start.
By ordering your data incident management process around data products as opposed to tables or general SLAs, you’ll be able to optimize the volume of alerts coming in as well as clearly define the communication chain that supports them.
Every incident communication plans needs to have three things:
- The incident owner who will receive the alert
- Dependent consumers leveraging that product who need to be kept informed
- And how you’ll escalate or delegate the issue to the source manager or other relevant parties.
Step 4: Triage and troubleshoot
The most important part of any data incident management process is triaging and troubleshooting. The goal here is to minimize time-to-resolution. And like most elements of data incident management, this gets significantly easier when you’ve clearly identified your critical data products.
If you’re a relatively small team, you’ll likely rely on your incident owners (either internal to or outside the data engineering team) to take point troubleshooting. Again, this is much easier if your incident owners are also responsible for building and maintaining your data products.
Relying on a single source for building and troubleshooting requires operational excellence to minimize resource drain, so choosing the right data quality tooling is all the more important here (See this post from Nishith Agarwal on the benefits of buying over building for small teams).
If you’re a slightly larger team with more data products to maintain, you may choose to adopt Mercari’s approach and assign specific on-call reliability engineers to triage and troubleshoot incidents instead. While this has some obvious benefits for resource management and response time, it also enables your team to more easily catch recurring issues that could require improvements to the underlying infrastructure.
One resource that’s critical to minimizing time-to-resolution regardless of team size is lineage. This enables you to see at a glance what specific sources feed your critical data products and what teams are impacted.
While table level lineage is available in some form through solutions like dbt, column-level lineage will require a more advanced and programmatic data quality solution like Monte Carlo to understand upstream and downstream dependencies.
Step 5: Incident post-mortems
When it comes to incident management, the best defense really is a good offense. If your data products are critical enough to require a structured process for incident management, they’re critical enough to warrant a proactive approach to improvement as well.
By conducting regular incident reviews, you’ll empower your team to continuously improve your data products, from the structure of your pipelines all the way down to your monitoring strategy and comms plan.
Again, if you choose to assign dedicated on-call reliability engineers (or at minimum limit ownership to within your data engineering team), you’ll be better equipped to identify and improve recurring issues across your pipelines.
Continuous improvement ensures that you can continue to meet critical SLAs as your environment evolves and that your team is able to deliver reliable value for your stakeholders for the life of your data products.
Keep your eye on the reliability prize
Even with the greatest data incident management process, you’ll never totally eliminate data quality incidents. As your environment continues to evolve, new sources are added, new teams are created, and new use-cases are discovered, data quality incidents will follow.
As sure as the sun rises, you will be triaging and troubleshooting again.
The goal isn’t to eliminate data quality incidents. The goal is to optimize your ability to catch and remediate incidents in a way that provides the maximum value to your stakeholders. And that all starts with understanding what your consumers need.
If you reject ad-hoc incident management steps and train your data org to have an eye toward creating long lived data products, you’ll be one step closer to delivering reliable data products that help your organization realize the value of its data.
Find out how Monte Carlo’s data observability platform can supercharge your incident management process by helping you detect, resolve, and prevent data incidents faster.
Our promise: we will show you the product.
Read more posts.