Product demo.
Product demo.  What is data observability?
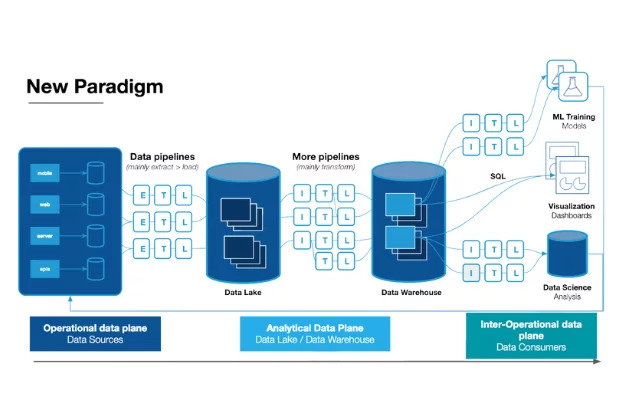
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Top 5 Data Engineering Deep Dives in 2022


Michael Segner
Michael writes about data engineering, data quality, and data teams.
No one wants to read marketing fluff, especially not data engineers. These builders and architects are prone to scoff at any article detailing concepts at a “high-level.”
Everyone understands that data lineage and data pipeline monitoring are important, but the real question is, “how do you build it?”
Caveat emptor, the following articles are for the technically inclined and definitely not for the faint of heart.
Table of Contents
- How ELT Schedules Can Improve Root Cause Analysis For Data Engineers
- Data Observability: How to Build Your Own Data Anomaly Detectors Using SQL
- Building Spark Lineage For Data Lakes
- Using the Airflow ShortCircuitOperator to Stop Bad Data From Reaching ETL Pipelines
- Building End-to-End Field Level Lineage for Modern Data Systems
- The common thread: teach a man to fish or offer him fish as a service
How ELT Schedules Can Improve Root Cause Analysis For Data Engineers
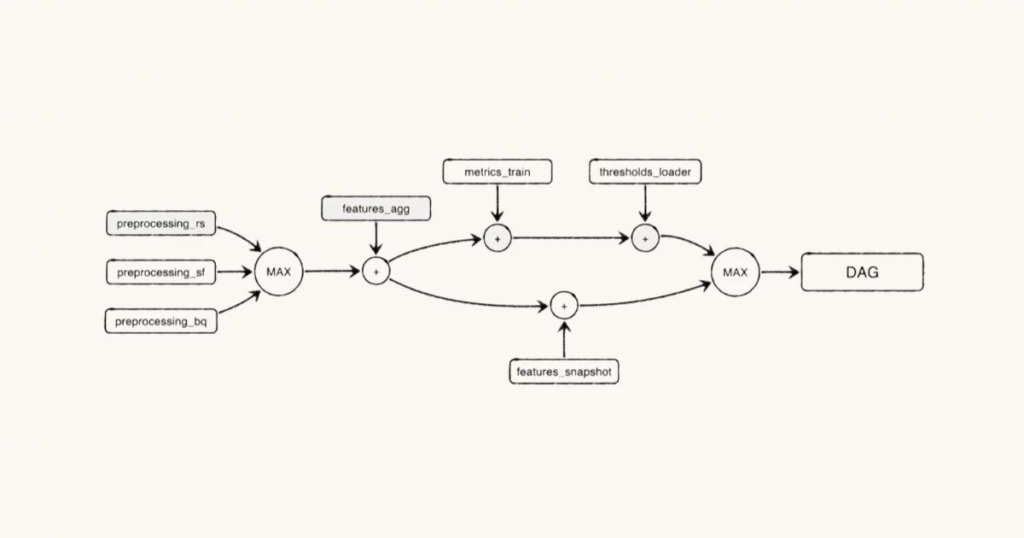
Let’s dive into the deep end of the pool with what can only be described as a dissertation on how leveraging Bayesian Network can help data engineers understand the probabilistic runtime of jobs in a DAG to pinpoint which pipeline job was the failure’s root cause.
There are charts, there are equations, there is code. What else could you need from a forward-looking proposal on better root cause analysis solutions?
Data Observability: How to Build Your Own Data Anomaly Detectors Using SQL

The same author, Monte Carlo data scientist Ryan Kearns, dives into how to build machine learning driven data anomaly detectors using SQL.
There are a lot of reasons your team may not want to do this, but regardless Ryan provides a step by step guide and GitHub environment for you to follow along.
Building Spark Lineage For Data Lakes
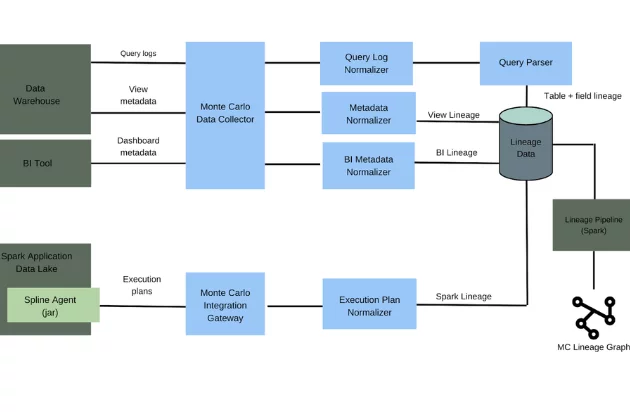
Everyone writes about the successful projects, but you learn more from the failures. Our engineering team at Monte Carlo describes why developing Spark lineage for data lakes is so much harder than for data warehouses.
But what makes this a post worth reading is the discussion on why we decided to discard the original solution for a more practical, elegant one involving our partners.
Using the Airflow ShortCircuitOperator to Stop Bad Data From Reaching ETL Pipelines
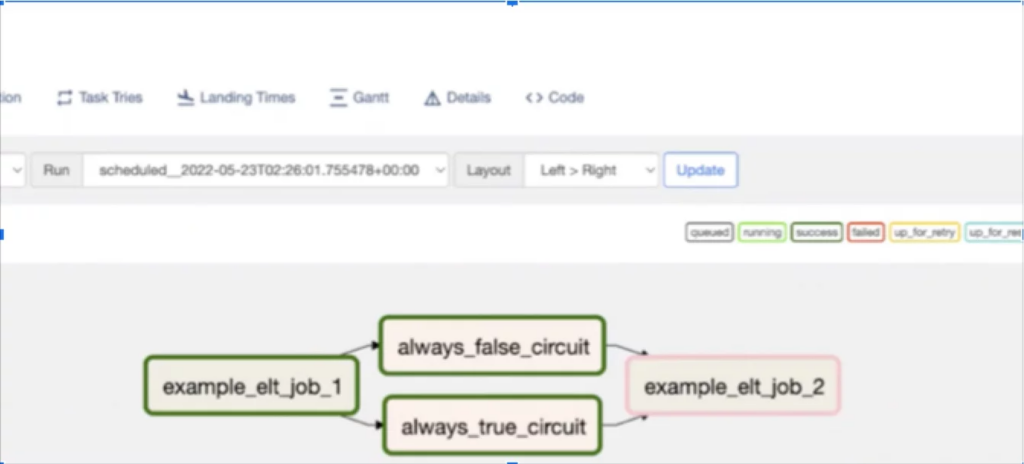
The data downtime equation is: number of incidents x (time to detection + time to resolution). Data observability can help reduce time to detection and resolution, but it can also help reduce the number of incidents as well.
Circuit breakers, essentially data quality tests that will stop data from landing in the data warehouse or lake if it fails, are a prime example. Our founding engineer, Prateek Chawla, provides a step by step guide on how to build these data circuit breakers in Airflow along with explaining when (and when not) to leverage this tactic.
Building End-to-End Field Level Lineage for Modern Data Systems
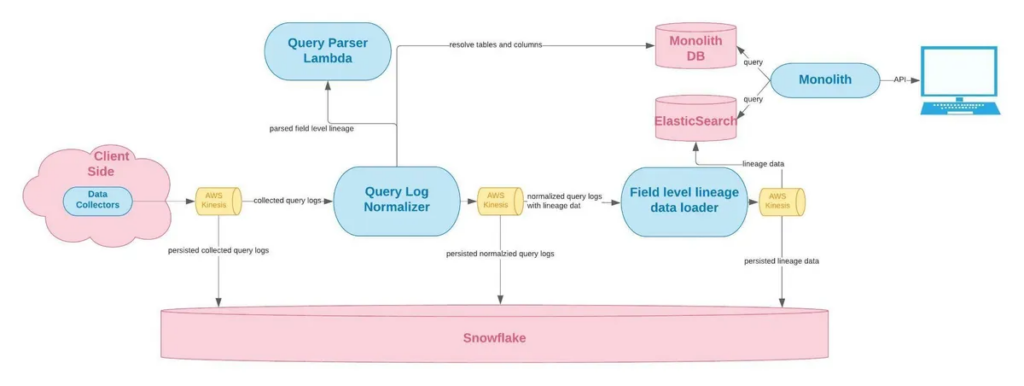
This was our deepest, most technical article in 2022. The process of developing field-level lineage was incredibly complex and describing the engineering breakthroughs was no easier (OK maybe a little easier).
We highlight our architecture as well as how we developed the logic in our parser to reverse engineering field-level dependencies based on SQL queries when the sheer number of possible SQL clause combinations is extraordinarily high. In fact, our original prototype only covered about 80% of possible combinations!
The common thread: teach a man to fish or offer him fish as a service
We like showing how the sausage is made at Monte Carlo (apologies for the mixed food aphorisms).
Not only does it help demonstrate the complexity and value of our solutions, it gives back to the engineering community of which we consider ourselves a member. We also know the true value of our platform is that it will always be easy to use, highly available, and constantly updated.
That’s because we are constantly innovating, and to that end, you can expect more technical deep dives in 2023.
Interested in diving into the technical details of data quality? Schedule a time to talk with us using the form below.
Our promise: we will show you the product.
Read more posts.