Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Validation Testing: Techniques, Examples, & Tools


Michael Segner
Michael writes about data engineering, data quality, and data teams.
The Definitive Guide to Data Validation Testing
Data validation testing ensures your data maintains its quality and integrity as it is transformed and moved from its source to its target destination. By applying rules and checks, data validation testing verifies the data meets predefined standards and business requirements to help prevent data quality issues and data downtime.
While this process varies from organization to organization, these unit tests are typically applied by the data engineer after they have built the data pipeline architecture. This is done by:
- Manually writing and scheduling a SQL query;
- Using an automated data profiler like Great Expectations or one within a transformation platform like dbt; or
- Developing custom monitors within a data observability platform
Similar to how there are multiple quality assurance checkpoints as part of the manufacturing process, it is important to implement data validation testing at each stage of the data curation and lifecycle process.
It’s also important to understand the limitations of data validation testing. Like most things, there will be diminishing returns for each new test and new challenges that arise from attempting to execute it at scale.
This guide will walk you through various data validation testing techniques, how to write tests, and the tools that can help you along the way. We’ll also cover some common mistakes we haven’t seen covered anywhere else.
In This Article:
Data validation procedure
We will take a more expansive view of data validation because we believe it’s critical to achieving the objective: ensuring high quality data that meets stakeholders’ expectations. Writing tests that pass isn’t a useful process and of itself, it’s a means to an end.
From this perspective, the data validation process looks a lot like any other DataOps process.
Step 1: Collect requirements
You need to collect requirements before you build or code any part of the data pipeline. Why? If you choose the wrong approach, no number of data validation tests will save you from the perception of poor data quality.
For example, your data consumers might need live data for an operational use case, but you chose to go with batch data ingestion. The data freshness will never meet the requirements, and thus, even if your tests pass the data quality is still poor in the eyes of your stakeholders.
When collecting requirements you will want to cover the basics including: schema, freshness, quality attributes, access, ownership, and more. You should then document this information and even consider creating a data SLA.
Step 2: Build the pipeline
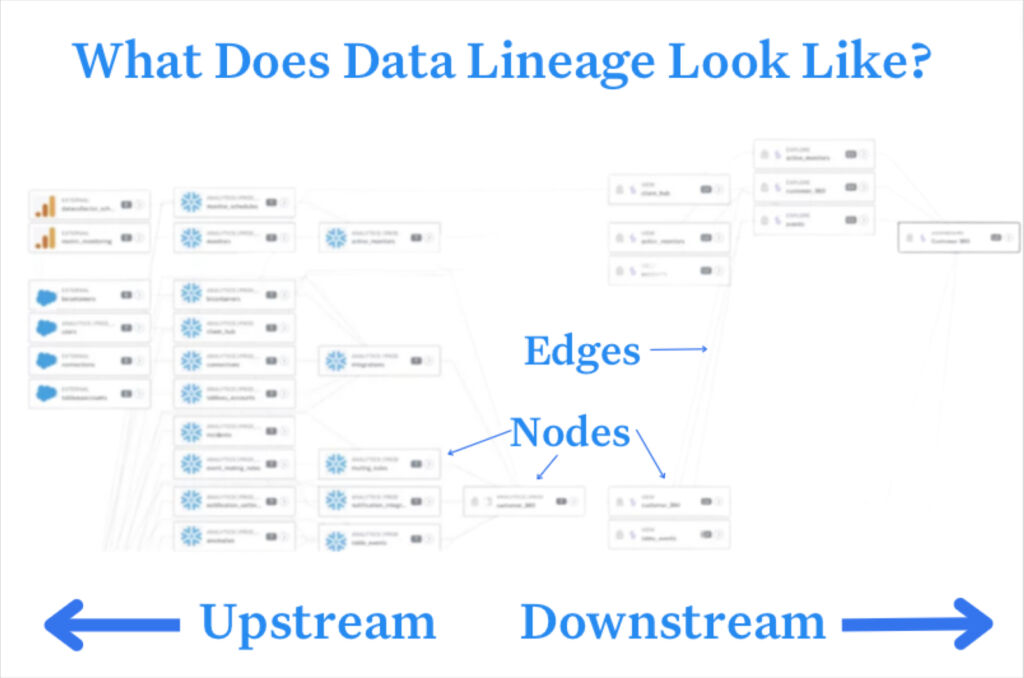
Chances are you are not building a data pipeline entirely from scratch, but rather combining data from new sources with data already in your data warehouse or lakehouse. In these cases it is important to understand data lineage. The reliability of your data product is as strong as its weakest link.
When building the pipeline you will want to consider components beyond data quality including how PII will need to be handled, idempotency, and data optimization.
Step 3: Sample the data, smoke test, data diff
After you’ve developed your data pipeline you’ll want a quick and dirty way to see if you did it correctly. It doesn’t make sense to turn on the spigot if your pipeline will be spewing sewage, nor does it make sense to start applying validation tests that will all noisy fire at once.
Sampling the data involves running the pipeline on a small subset of data to see if there are any easy to spot inconsistencies or errors. A smoke test is a more in-depth process involving synthetic data, and data diff is the process of understanding how code changes impact the number of rows produced in the target table.
Step 4: Write and implement data validation tests
There are many types of data validation tests (more on that in the next section), but you can consider three different types of tests.
- The tests that are common across every data pipeline and help ensure basic functionality and quality. Data engineers should be able to apply these without requiring much input. For example, most (really all) tables should have a primary key, like user_id, which should never have a NULL value. Ensuring schema continuity, perhaps as part of a data contract, would be another common data validation test.
- The tests that are specific to a dataset and reflect business logic or domain expertise that will typically need to be gleaned from a data analyst or business stakeholder. For example, this column represents currency conversion and should never be negative. Or, this column is for transactions in Bitcoin which should be a float rather than integer data type since they are frequently done in fractions of a coin.
- The tests that monitor for drift or data anomalies. For example, order_amount has never exceeded $100 and there is a new value of $150. These types of tests are the most difficult as the thresholds are difficult to determine and will require some historical data to profile against.
Step 5: Continuously improve and deploy
There is always another pipeline to build, so it’s understandable why so many data teams stop the data validation process at the previous stage.
However, data engineers should make it a standard operating procedure to check back in with data consumers to gauge satisfaction levels and surface any additional requirements that should be validated with additional tests.
This is also an excellent time to take a step back and assess your data quality framework as a whole. Our research shows data teams spend up to 30% of their time on data quality related tasks, but issues still make it to business stakeholders “all or most of the time.” This is because writing data validation tests is tedious and only provides coverage for a small subset of issues that can be anticipated.
If your team is experiencing capacity or data trust issues, you will likely want to consider adding data observability and machine learning driven anomaly detection to your data validation approach.
Data observability can also help by surfacing data reliability metrics to your data teams so they can accurately assess if the data set will be a fit for their needs. Your data team can imbue trust in its products within the catalog, just like Amazon.com generates trust by providing key metrics and warranties.
Data validation testing techniques
Let’s dive into common data validation testing techniques. These include:
- Range Checking: For example, if a field is supposed to contain an age, the range check would verify that the value is between 0 and 120.
- Type Checking: For example, if a field is supposed to contain a date, the type check would verify that the value is indeed a date and not a string or a number.
- Format Checking: For example, if a field is supposed to contain an email address, the format check would verify that the value matches the standard format for email addresses.
- Consistency Checking: This technique checks if the data is consistent across different fields or records. For example, if a field is supposed to contain a country, and another field in the same record contains a city, the consistency check would verify that the city is indeed in the country.
- Uniqueness Checking: For example, if a field is supposed to contain a unique user ID, the uniqueness check would verify that no other record contains the same user ID.
- Existence Checking: For example, if a field is supposed to contain a non-null value, the existence check would verify that the value is not null.
- Referential Integrity Checking: This technique checks if a data value references an existing value in another table. For example, if a field is supposed to contain a foreign key from another table, the referential integrity check would verify that the value exists in the referenced table.
How to write data testing validation tests
Data validation testing can be done in various ways depending on the tools, languages, and frameworks you’re using.
Example data validation test in Excel
For smaller datasets, you can use spreadsheets like Excel or Google Sheets to perform basic data validation tests. Both allow you to define validation rules for your data and highlight cells that don’t meet these rules.

Let’s say you only wanted decimal values in a certain column. In Excel you can select the field, select data validation under the data tab, select the decimal option under Allow.
Example data validation test in SQL
If your data resides in a relational database (warehouse or lakehouse), you can write SQL queries to perform data validation tests. For example, you can use SQL queries to check for data freshness.
For example, let’s assume you are using Snowflake as your data warehouse and have integrated with Notification Services. You could schedule the following query as a Snowflake task which would alert you Monday through Friday at 8:00am EST when no rows had been added to “your_table” once you have specified the “date_column” with a column that contains the timestamp when the row was added.
CREATE TASK your_task_name
WAREHOUSE = your_warehouse_name
SCHEDULE = 'USING CRON 0 8 * * 1-5 America/New_York'
TIMESTAMP_INPUT_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
AS
SELECT
CASE WHEN COUNT(*) = 0 THEN
SYSTEM$SEND_SNS_MESSAGE(
'your_integration_name',
'your_sns_topic_arn',
'No rows added in more than one day in your_table!'
)
ELSE
'Rows added within the last day.'
END AS alert_message
FROM your_table
WHERE date_column < DATEADD(DAY, -1, CURRENT_DATE());Many data observability platforms, like Monte Carlo, allow you to deploy custom monitors (basically validation tests) with a SQL statement as well.
Example data validation test with dbt
ETL tools often include data validation features. You can define validation rules that the data must meet before it’s loaded into the target system.
dbt is a popular open-source transformation tool that can be used for data testing. There are four standard tests you can use out-of-the-box with dbt. These include: not NULL, unique, accepted values, and relationships.
Here’s an example of how you might write a test in dbt:
In dbt, tests are defined in a YAML file. Let’s say you have a table named users and you want to test the uniqueness of the user_id field and also check that the age field is never negative. You would define these tests in your schema.yml file like this:
version: 2
models:
- name: users
columns:
- name: user_id
tests:
- unique
- not_null
- name: age
tests:
- name: accepted_values
config:
values: ['>= 0']In this example, the unique and not_null tests are built-in dbt tests. The accepted_values test is a custom test that checks if the age field is greater than or equal to 0.
To run the tests, you would use the dbt command line: dbt test.
This command will run all tests defined in your project and output the results. If a test fails, dbt will provide details about the failure, which can help you identify and correct the issue.
Example data validation test with Great Expectations
There are also specialized data testing frameworks like Great Expectations (Python-based) that allow you to define and run data validation tests as part of your data pipeline. After you installed, initialized, and created an expectation suite, you can edit the test within your IDE.
A not null test for a user_id field would involve a JSON snippet that looked like this:
{
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "user_id"
}
}Example data validation test with Monte Carlo
As previously mentioned, you can create custom monitors in Monte Carlo using pre-built templates or writing a SQL rule. Let’s say you wanted to create a not NULL validation test for the resource_id field on the analytics:prod.client_warehouse table.
You could simply create a field quality rule for that table and select the field:
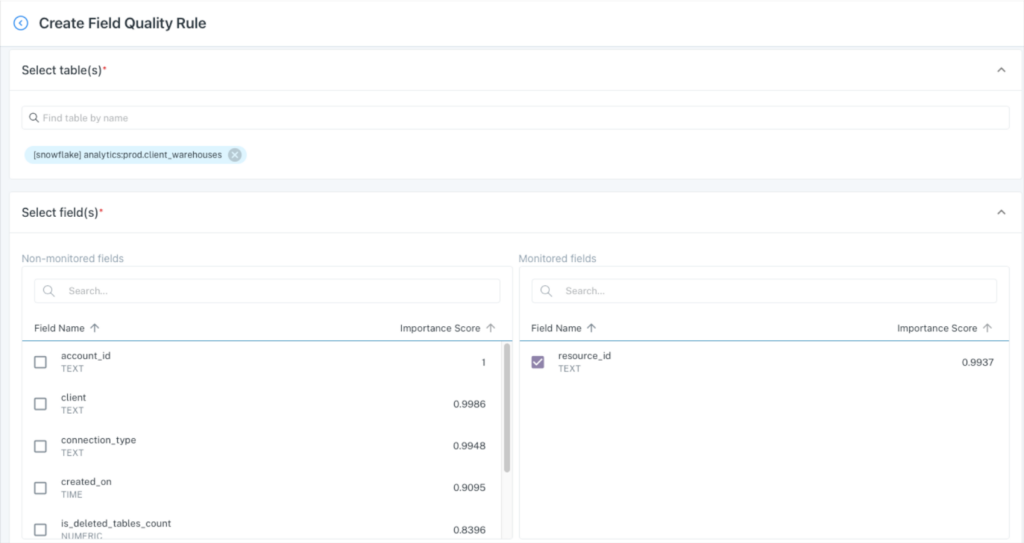
Then select %null metric and the threshold. You’ll notice that it generates a SQL query, but no code is required.
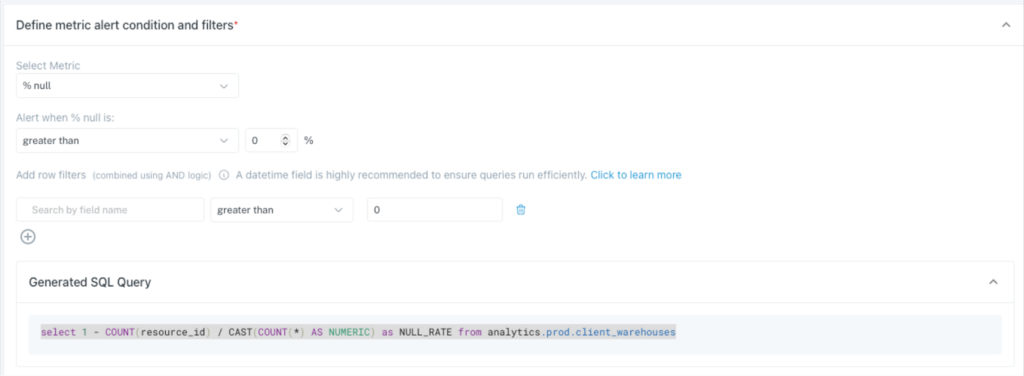
Even better, you can specify how the alerts are routed and to what particular Slack or Teams channel. On top of all that, you would also have broad machine learning coverage across this and all your tables for schema, freshness, volume, and other quality anomalies.
What’s next? Alerts versus circuit breakers
One key data validation testing question you will need to answer is: what happens when a test fails? There are essentially three options:
- Alerting: This is the most common. The data in question enters and stays in the environment while the data engineering team investigates the failed test. The downside is that the data may be used in the interim, or it is dependent on the data team to notify users of the issue.
- Circuit breakers: The data pipeline is stopped so no data enters the warehouse. Circuit breakers create data downtime by design, so it should only be used for the most important pipelines in situations where no data is better than bad data. A common use case would be customer facing data.
- Buyer beware: An alert is sent and the data is still available to be used, but there is some sort of automatic notification for data consumers either as part of a data product dashboard or other mechanism.
Data validation testing limitations and mistakes
If you are doing data validation testing wrong, it can do more harm than good. Your team will be spinning their wheels without creating any tangible value for the business. Here are some limitations to data validation testing and common mistakes to avoid.
Uneven application
We all know we should brush our teeth three times a day, but are you confident everyone on your team is doing it every day? Data validation testing is a similar habit.
Everyone on the data team knows they should be doing it, and have the best intentions of doing it, but pressing deadlines and ad hoc requests get in the way.
Most of the data teams we interact with have a very uneven data validation process unless engineering leadership has repeatedly emphasized it as a priority over other aspects of the job. Even then, new tables get created without validation rules applied immediately. Just like data documentation is rarely perfect, so too are manual data testing strategies.
Little understanding of the root cause
The table that experienced the anomaly or data quality issue rarely holds the necessary context to adequately determine the cause of the problem. The data ecosystem is just too interdependent for that.
Unfortunately, root cause analysis is the hard part. Our research shows data teams spend an average of 15 hours or more trying to solve data issues once they’ve been identified.
To accelerate troubleshooting, data teams typically need to move upstream and leverage tools provided by data observability platforms such as data lineage, correlation insights, query analysis and more. Otherwise you won’t have context to determine if the data quality incident was caused by a system, code, or data issue (or where in the pipeline it might lie).
Alert fatigue
Data can break in a near infinite amount of ways. When teams experience a data quality issue that wasn’t caught by a data validation test the most common response is to layer on more tests.
As a result, data teams have alarm bells ringing all day without any context on the impact that can help them triage. Is it an issue that will find its way to a critical machine learning application or a dashboard checked once a quarter? Without data lineage there is no way to tell.
Business logic or key metrics go unvalidated
It’s easy for data engineers to understand that a primary key column should never be NULL, but it’s much harder to set non-absolute thresholds on key business metrics without input from data analysts, analytical engineers, or other data consumers. As a result, this step is frequently overlooked.
Validate only one part of the pipeline
Data validation tests are best deployed on your most important tables, but that doesn’t necessarily mean your most curated tables in your gold layer. It can be especially important to test or profile data as it first lands raw in your environment, especially if it is coming from third parties. Each step of the transformation process for critical data products should be evaluated to see if a data validation test is appropriate.
No coverage for unknown unknowns
In our experience, about 80% of data quality issues occur in ways that no one anticipated. You can’t anticipate all the ways data can break, and if you could it is incredibly difficult to scale across all of your pipelines. Monitoring for these issues with machine learning can help fill those coverage gaps.
“We had a lot of dbt tests. We had a decent number of other checks that we would run, whether they were manual or automated, but there was always this lingering feeling in the back of my mind that some data pipelines were probably broken somewhere in some way, but I just didn’t have a test written for it,” said Nick Johnson, VP of Data, IT, and Security at Dr. Squatch.
The right tool for the right job
Once you’ve validated your data, the journey isn’t over. Data can become corrupted, go missing, or become outdated at any time as it moves throughout your systems.
Data validation testing, though vital, only goes so far. Some of the downsides include 1) you have to anticipate all the ways things could go wrong, 2) you have to understand the rules to apply them (does a data engineer know that a currency conversion column can’t be negative?), and 3) try to scale over a million items.
Given these challenges, it’s clear that something more encompassing, something that can keep an eye on the entire lifecycle of the data is needed. That’s where data observability comes in.
A data observability platform like Monte Carlo keeps an eye on your data at all times, providing automated monitoring across every production table and down to your most critical fields.
The platform uses machine learning to automatically determine what to monitor and the thresholds to set based on your historical data incidents and incidents across thousands of customers. And as soon as a data incident or anomaly is detected, Monte Carlo notifies data owners to quickly triage and resolve incidents before they affect the business.
This isn’t to say your team should never conduct data validation testing, just that it is an activity best reserved to set alerts on the most understood, absolute thresholds for your most critical data products. For everything else, there’s data observability.
Learn more about how data observability can supplement your testing. Set up a time to talk to us using the form below.
Our promise: we will show you the product.
Read more posts.