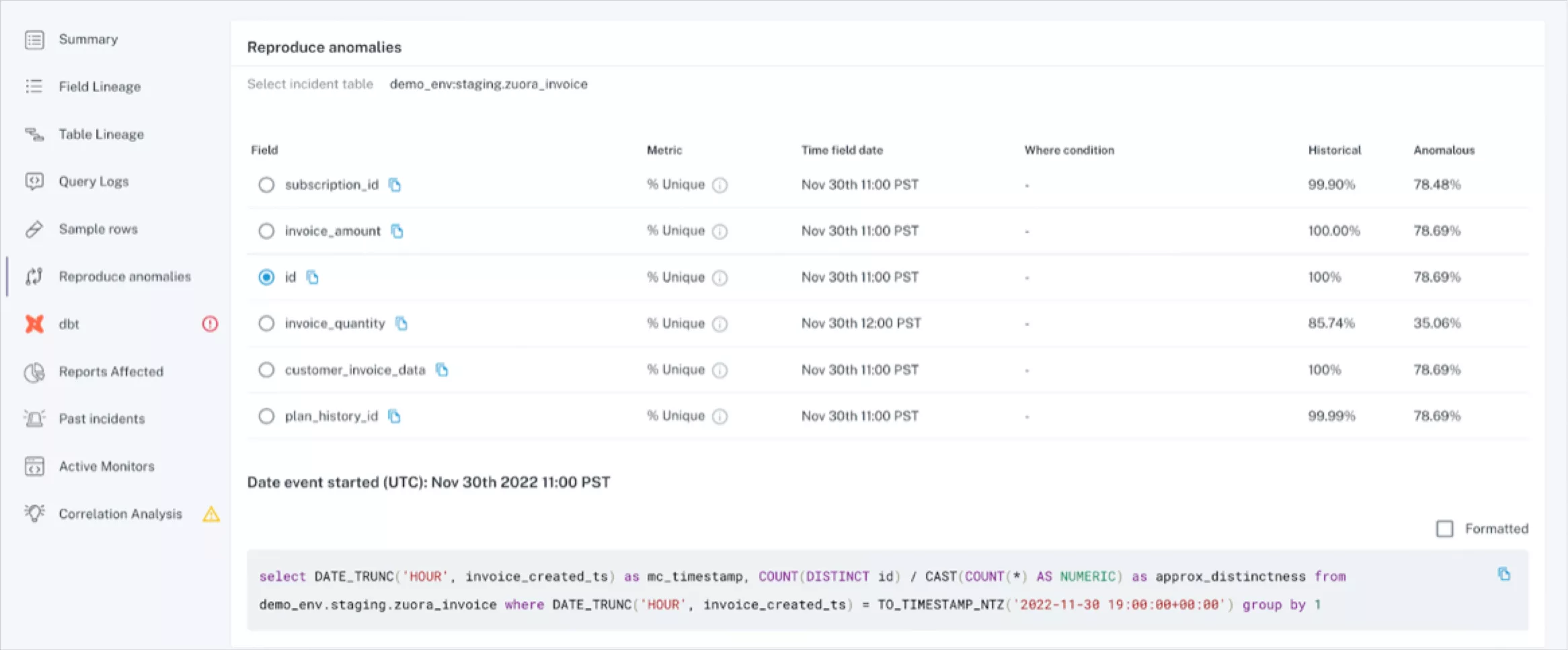
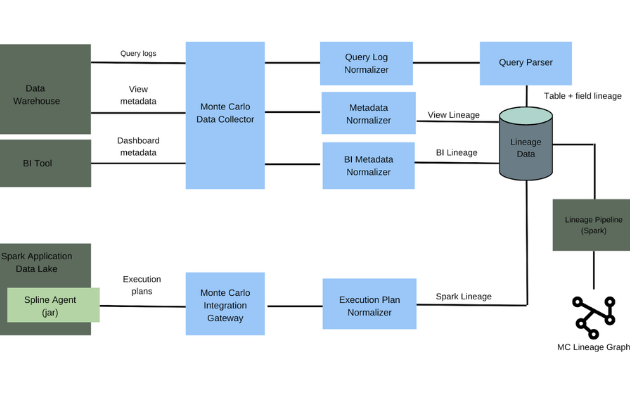
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is dbt Testing? Definition, Best Practices, and More


Molly Vorwerck
Molly is Head of Content & Communications @ Monte Carlo.
Data testing is the first step in many data engineers’ journey toward reliable data. And one of the most popular approaches is dbt testing. dbt (data build tool) is a SQL-based command-line tool that offers native testing features.
But there’s a lot to understand in order to both create the most value from your dbt tests and avoid leaning too heavily on a time-intensive process. So in this article, we’ll dive into the nitty-gritty of dbt tests: what they are, how they work, how to run them, and how to handle their limitations.
Along the way, we’ll provide plenty of examples to help you learn exactly how you can use dbt tests to improve data reliability — and when you might need to look beyond dbt for full data quality coverage.
Table of Contents
The need-to-know basics of dbt
Data engineers use dbt to facilitate analytics workflows. More specifically, teams use dbt to write transformations as SQL queries, version control the code, and deploy transformations incrementally.
dbt also happens to be an incredibly handy tool for running many data quality tests. You can use dbt to validate the accuracy, freshness, and reliability of your data and data models, ideally identifying any issues before they cause downstream impacts on analytics and decision-making. And since source data changes often — sometimes multiple times per day — most teams use dbt testing continually as part of their production pipelines.
Defining dbt tests
There are two primary ways to define dbt tests: generic and custom. Generic, predefined tests are out-of-the-box tests that you can apply across multiple data models. Custom tests are — you guessed it — customized tests you develop for a specific data model.
These two types of tests often work together within dbt. You can easily apply generic tests across all your models for general data quality checks, and then develop custom tests to ensure specific business rules are being followed for specific models or fields.
How to run generic or schema tests in dbt
Within dbt Core, you’ll encounter a set of generic, predefined tests that can be easily applied to columns in your models by adding a few lines of YAML (a human-friendly data serialization language) in your dbt project.
Since these tests are used to validate the correctness of your data models’ schema, they’re also called schema tests.
The most common generic tests include:
- Uniqueness, which asserts that a column has no repeating values
- Not null, which asserts that there are no null values in a column
- Referential integrity, which tests that the column values have an existing relationship with a parent reference table
- Source freshness, which tests data against a freshness SLA based on a pre-defined timestamp
- Accepted values, which checks if a field always contains values from a defined list
Let’s get specific about these so-called generic tests. Here are step-by-step instructions to run generic or schema tests in dbt.
- Define your dbt model
First, you need to have a defined dbt model which can be described as a select statement. This model will be saved as `.sql` file within the `models` directory of your dbt project.
For example, this is what your `orders` model might look like:
```sql
-- models/orders.sql
SELECT
order_id,
customer_id,
order_date,
order_amount
FROM
raw_schema.raw_orders_table
```- Create the schema.yml file
In the same directory as your model, create or update the `schema.yml` file. We’ll use this file to define tests for your model.
- Define your tests
In the `schema.yml` file, define your tests associated with the appropriate column of your model. For example, here’s how to declare schema tests for ‘unique’ and ‘not_null’ to the ‘order_id’ column in your `orders` model:
```yaml
-- schema.yml
version: 2
models:
- name: orders
description: "A table containing all orders"
columns:
- name: order_id
description: "The unique identifier for each order"
tests:
- unique
- not_null
```- Run your tests
After you’ve defined your tests, you can run them using the following command in your terminal:
```shell
$ dbt test“`
When you run this command, dbt compiles the test definitions into SQL queries, executes these queries, and displays the test result.
With dbt testing, no news is good news. Your test passes when there are no rows returned, which indicates your data meets your defined conditions.
If any rows are returned, the test has failed. Time to investigate.
- Iterate and refine
When a test fails, start by thoroughly examining the failure details in your dbt model and test results to understand why it failed. This investigation will guide you toward what needs to be adjusted, whether it’s refining your data transformation logic or modifying the test query itself.
Once you’ve implemented these adjustments, it’s time to verify them by running the schema test again — not just to ensure that your adjustments resolved the initial problem, but so you can validate that your data is now adhering to your standards of quality and accuracy. A passing test means you’ve improved the trustworthiness of your data.
- Schedule and automate
You’ll need to run schema tests continuously to keep up with your ever-changing data. If your datasets are updated or refreshed daily, you’ll want to run your schema tests on a similar schedule. This helps ensure your data quality is consistent over time, given that new data isn’t always guaranteed to follow the same properties as old data.
Once you have a set of reliable schema tests, use a tool like dbt Cloud, Apache Airflow, or a task scheduler to run the tests on a regular basis.
How to run custom data tests in dbt
When you need to account for specific business scenarios or enforce domain-specific rules that aren’t covered by generic tests, it’s time to use a custom data test.
Custom data tests in dbt (also known as just good old-fashioned “data tests”) are user-defined SQL tests for validating more complex relationships or conditions in data.
For example, you can write a custom data test to check:
- Whether the total sum of individual product prices in all shopping cart orders equals the total revenue
- Whether every ‘Subscription Renewal’ event occurs only after a ‘Subscription Activation’ event for a given customer ID
- Whether every product follows a given status update sequence as it moves through the supply chain, such as ‘Manufacturing’, ‘Quality Check’, ‘Shipping’, and ‘Delivery’
Custom data tests can be used to help ensure revenue is calculated correctly, data is entered accurately, and business rules are followed — just to scratch the surface.
Itching to get started? Here are the step-by-step instructions to run a custom data test in dbt.
- Identify the data quality rules
Before you start composing any SQL statements, take time to identify the specific data quality rules or constraints you want to enforce. You’ll need to determine the conditions or criteria that the data should meet to be considered valid.
For example, you might want to confirm that the ‘discount_percentage’ in a ‘sales’ table is always between 0 and 100. You can use your custom test to verify that certain numerical fields fall within that expected range.
- Create a data test file
First, you’ll need to create a new SQL file within the ‘tests’ directory in your dbt project. You’ll want to give the file a meaningful name that reflects the purpose of the test, and follow the naming convention of ending with ‘_test’. In the discount percentage example we just discussed, you might use ‘discount_range_test’.
- Write the data test
In the data test file, write a SQL query that checks for the specific data quality rule you want to enforce. You’ll use SQL functions, operators, and clauses to define the conditions and criteria for the test, making sure the query accurately reflects the data quality rule you identified earlier.
For example, our discount range test would look like:
```sql
-- tests/discount_range_test.sql
SELECT *
FROM {{ ref('sales') }}
WHERE discount_percentage < 0 OR discount_percentage > 100
```- (Don’t) configure your test
Just to be clear, custom data tests don’t require additional configuration in a ‘schema.yml’ file. By placing the SQL file in the ‘tests’ directory and naming it appropriately, dbt knows to run this file as a test.
- Run the data test:
Finally, save the data test file and run the dbt test command. Just like with schema tests, you run custom data tests using the following command in your terminal:
```shell
$ dbt test
```This will direct dbt to run all of your tests — both schema and custom data tests — and return results.
If your custom data test is successful, your query will return zero rows. (Remember, no news is good news.)
- Iterate and refine
But if your test does return any rows, dbt will provide detailed information about the specific data that didn’t meet the criteria. Explore what happened and make the necessary adjustments to resolve the issue. Run the test again to validate that the initial problem is solved and that your data meets your quality and accuracy standards.
- Schedule and automate
Just like schema tests, custom data tests in dbt are typically not run just once but are incorporated into your regular data pipeline to ensure ongoing data quality. The frequency of the tests typically depends on your specific business needs and the update schedule of your data.
Custom data tests are generally run every time a dbt `run` command is executed to process your transformations. This ensures that whatever transformations you have made didn’t unintentionally introduce any quality issues into the data. Often, teams run custom data tests as part of a deployment pipeline, or scheduled on production systems via job schedulers like Apache Airflow, dbt Cloud, or via in-built schedulers in your data warehouse solution.
Common dbt testing use cases
Time to make all these how-to instructions come to life. Here are some common use cases for dbt tests.
Data type validation
Within dbt, data type validation confirms that the data in each column is of the expected data type, such as integers, strings, or dates. These kinds of tests are particularly important when ingesting new data or integrating disparate data sources, where inconsistent or incorrect data types can pop up that could cause downstream errors.
For example, let’s say your company has customer data from both a Customer Relationship Management (CRM) system and a website’s analytics platform. Both systems track ‘customer_id’, but the CRM system uses integer values, like 123456, while the analytics platform uses alphanumeric strings, like ‘CUST123456’.
When you integrate these two systems into a single database and try to unify the ‘customer_id’ field, you might end up with a mixed column containing both integers and alphanumeric strings. By running a custom data test to validate the data type, you can identify and address the issue to maintain data integrity:
```sql
-- tests/customer_id_numeric_test.sql
SELECT customer_id
FROM {{ ref('merged_customers') }}
WHERE customer_id ~ '[^0-9]'
```If the test returns any rows, it indicates some values in ‘merged_customers’ are not integers, and the test fails.
Completeness checks
Another common type of dbt testing is a completeness check, which makes sure that certain key columns aren’t missing any values — in other words, that these columns don’t contain any NULL values. These fields could be important identifiers, timestamps, or any other data crucial for analysis and processing.
If null values appear in your data where you don’t expect them, it usually indicates missing or unknown data — which sometimes could indicate potential quality issues depending on the specific dataset and use case.
For example, an e-commerce business could have an ‘orders’ table should always have a ‘customer_id’ and ‘order_date’ for each order. A missing ‘customer_id’ or ‘order_date’, i.e., a NULL value in these fields, would interrupt the analysis of customer behavior or sales trends.
In dbt, the built-in schema test `not_null` can be used to build completeness checks. Here’s how you can define it in your `schema.yml` file:
```yaml
version: 2
models:
- name: orders
columns:
- name: customer_id
description: "The unique identifier for each customer who made an order"
tests:
- not_null
- name: order_date
description: "The date when order was made"
tests:
- not_null
```In the above scenario, dbt will check the `orders` model to make sure every row has a value for `customer_id` and `order_date`. If it finds any NULL values in these columns, the test fails, indicating that there are incomplete records.
Consistency and integrity checks
Another common use case for a custom data test? Consistency and integrity checks that confirm your data adheres to specified rules or constraints, such as a cross-record validation.
In our metaphorical e-commerce business, let’s imagine the `orders` table has a `total_order_value` field generated by multiplying the `quantity` of each item by the `price_per_item`. One business rule might state that `total_order_value` should always be equal to `quantity` times `price_per_item`.
To ensure that the `total_order_value` field is calculated correctly, you could create custom dbt testing to validate the business rule:
```sql
-- tests/order_value_test.sql
SELECT order_id, quantity, price_per_item, total_order_value
FROM {{ ref('orders') }}
WHERE total_order_value != ROUND(quantity * price_per_item, 2)
```In this test, you’re selecting fields from ‘orders’ where the ‘total_order_value’ field doesn’t equal the result of ‘quantity’ times ‘price_per_item’ (rounded to the nearest cent if dealing with dollars, hence the use of ROUND function).
If the test returns any rows, it indicates some records have a discrepancy between the ‘total_order_value’ and the multiplication of ‘quantity’ and ‘price_per_item’, and the test fails. (Note, the specifics of the SQL used might vary based on your SQL dialect and the particular business rule you’re enforcing.)
Business rule validation
Similarly, another custom data test use case is a business rule validation. This could involve everything from complex conditional logic to basic assumptions about how your data should look. Business rule validation tests are typically very unique to your business or domain and are key in ensuring that your data accurately reflects the real-world business phenomena it represents.
There are countless examples of these kinds of data tests, but let’s say you have a business rule that the `order_amount` must always be greater than or equal to zero. Custom dbt testing for this could look like:
```sql
-- tests/order_amount_test.sql
SELECT *
FROM {{ ref('orders') }}
WHERE order_amount < 0
```FROM {{ ref(‘orders’) }}
WHERE order_amount < 0
“`
In this example, using the custom data test, you’re selecting records from ‘orders’ model where the `order_amount` is less than zero. If the test returns any rows, the `order_amount` field’s negative values violate your business rule, and the test fails.
Running dbt tests
Running dbt testing can be done locally on your own machine, or within a CI/CD pipeline. In any case, you’ll likely want to set them up to run again and again. And again.
Running dbt tests locally
When you’re crafting and troubleshooting new data models, you may want to run your dbt tests locally. Before you begin, ensure that you have installed dbt on your machine and have a working dbt project, with the necessary source data connected and tests defined in your `schema.yml` files.
Then, follow these steps:
- Open a terminal and navigate to your dbt project directory. Each dbt test is an encapsulation of a SQL `SELECT` statement that is expected to return zero rows for a successful test. When you run dbt test, dbt will execute these SQL tests against your models in your transformed database.
- To run your tests, enter the following command in your terminal:
cmd:
```shell
$ dbt test
```By running this command, dbt will compile all your defined tests into SQL queries, and then execute these queries on your defined data models in the database.
dbt testing in a CI/CD pipeline
Incorporating dbt tests into a Continuous Integration/Continuous Deployment (CI/CD) pipeline ensures the testing of your data transformations occurs at every code change, promoting consistent data quality and reliability.
Here’s a basic overview:
- Configure your CI/CD platform to automatically pull the latest version of your dbt project repository on each commit. You will also need to securely store and provide dbt with the necessary credentials to access your target database.
- With pipelines, the environment starts clean every time. So, in your pipeline script, specify a step to install dbt and any dbt packages your project relies on.
- Run your dbt models and tests. Often, you’d separate these into two steps in your pipeline: dbt run and dbt test. The `dbt run` command will compile and execute your models, thus transforming your raw data into analysis-ready tables. Once the models are created and data transformed, `dbt test` should be executed. This command runs all tests defined in your dbt project against the transformed data.
- Configure your pipeline to handle failures effectively. If a test fails, i.e., the `dbt test` command exits with a non-zero code, you want your pipeline to halt and notify the team. This could be implemented as an email alert, a message in a shared chatroom, or an update on a dashboard.
- Make sure logs are accessible for future reference. This will help you debug any failures and understand the health of your data pipeline over time.
By integrating dbt testing into your CI/CD pipeline, you ensure that your data transformations are continuously tested and validated as your codebase evolves and involves more contributors, maintaining the integrity and reliability of your data models.
Scheduling and automating dbt tests
dbt testing is rarely a one-and-done event — because your data is constantly changing, you’ll want to run generic and custom data tests continuously, based on how frequently your datasets are updated.
Tools like dbt Cloud, Apache Airflow, or task schedulers can automate your testing. And whenever you make changes to your dbt models (beyond the data itself), plan to run these schema tests again as part of your dbt CI/CD pipeline. This ensures your data quality and structure aren’t affected by alterations to your models.
Storing test failures
When a dbt test fails, you obviously want to troubleshoot and resolve any issues. But even after you re-run a test and confirm that your solution worked, you may want to store your test failures in dbt — in other words, you capture and retain the records that caused a particular test to fail.
When you configure dbt to store test failures, dbt will create a new table in the database each time a test fails, containing the rows that caused the test to fail.
These tables provide a more detailed insight into what exactly went wrong and why the test failed, helping you diagnose and rectify any issues with your data models more efficiently. Once you’ve identified the problem, you can use the failed data to replicate the error scenario and verify if the modifications you’ve made are resolving the issue. Storing test failures also provides traceability that assists in identifying patterns and recurring issues, and improves communication on your team by providing clear context for problem-solving.
You can enable the storage of test failures in your `dbt_project.yml` file by adding the following configuration:
```yaml
test:
+store_failures: true
```Keep in mind that retaining these records does incur more storage cost and management resources, so make sure to clean the stored failure tables regularly. Also, remember data governance. Stored test failure data should adhere to your relevant policies or regulations, including data privacy and security, and is only made accessible to the appropriate team members.
Integrating test failure tracking with incident management systems
When you run dbt tests within your CI/CD pipeline, you can usually integrate test failure tracking with your incident management system (IMS) or a workplace communication tool (like Slack or Microsoft Teams) to streamline error handling and resolution procedures. You can auto-populate incident tickets with all the necessary information from your failure logs (including the test that failed, failure reason, the relevant model, and maybe even a snapshot of the offending data, if privacy policies permit).
From here, you can assign the ticket to the relevant person/team, tracking progress, and ensuring resolution. After resolving the issue, don’t forget to re-run your dbt tests to ensure the solution has worked. Over time, these incidents provide valuable data points for analysis. You can analyze recurring failures to pinpoint systemic problems, inefficiencies, or areas for improvement in your data models or transformations.
It’s important to note that dbt testing is often “all on” or “all off” – meaning, you can’t mute or triage alerts natively with the tool. Implementing a data observability solution can help manage failed tests in a more graceful and targeted manner that allows you to automatically route incident alerts to the proper channels and provide instantaneous insights into the root cause of the issue.
Remember, configuration details would vary based on the specific tools you’re using for your CI/CD pipeline and incident management system. Always make sure you’re handling sensitive or personal data properly when managing test failures and integrating systems.
Limitations of dbt Testing for High-Quality Data
While dbt testing offers many benefits, it’s important to remember that dbt is fundamentally a manual Transformation (T) tool in ELT processes — not a comprehensive data governance or data management solution. There are some limits to keep in mind as you build a dbt testing discipline.
Data lineage and impact analysis
While dbt testing plays a crucial role in data quality for many teams, there are a few limitations around data lineage and impact analysis to keep in mind.
Limited visual lineage
dbt includes a `dbt docs generate` command that produces a visual representation of your model dependencies, which can be somewhat helpful. However, this lineage view is limited to the transformations within dbt and doesn’t include extraction from source systems or post-transformation steps, such as how data is surfaced in BI tooling.
Limited depth of lineage
Out-of-the-box dbt does not inherently maintain detailed lineage such as column-level lineage or the lineage of particular records. You can manually build macros in dbt to carry source metadata through your transformations, but this takes considerable time and resources and still won’t provide field-level lineage across the full data lifecycle.
Limited impact analysis
When it comes to complex impact analysis capabilities, dbt likely won’t provide everything you need. For example, it doesn’t provide native features to show what the potential impact would be on downstream models or reports if you were to change a specific transformation in the middle of your dbt project.
Non-comprehensive testing
dbt’s data tests are powerful and flexible, especially with schema tests and custom data tests. However, writing comprehensive tests for very large datasets or complex business rules can sometimes be challenging and time-consuming.
Does dbt testing cover all your governance bases? No — but as part of a larger ecosystem that includes specialized tools covering extraction, loading, visualization, and governance, dbt works very well within its intended scope.
Challenges with cross-database testing
While dbt largely abstracts away the specifics of individual databases, testing across multiple databases can pose some challenges. Not all SQL dialects and database features are uniformly supported across all databases, so certain functions that work on one database might not work or behave differently on another. Differing data types, transaction support, and other complexities can make it tricky to design efficient cross-database testing.
Considerations for scalability and performance
While dbt has features to enable scalability, depending on the size and complexity of your data and transformations, you could run into a few issues around performance at scale. Extremely large datasets or complex functions can take a long time to run and lead to high memory usage. You also may need to adjust or rewrite tests over time to accommodate larger volumes of data.
Furthermore, dbt tests are fairly manual in nature, requiring a lot of engineering resources to implement and maintain. This can make it challenging to keep pace with the growth of your data environment.
Data observability: a better, more scalable option for data quality management
While dbt testing isn’t a one-size-fits-all solution for ensuring data reliability across your entire data lifecycle, it’s a welcome complement to data observability tooling.
Data observability provides end-to-end visibility into your data health across every step of the data lifecycle, from ingestion to analytics and BI tooling. It includes automated monitoring and alerting to speed up time-to-detection of data issues, and complete field-level lineage to facilitate faster time-to-resolution.
While data testing, including dbt testing, is useful to detect issues that you can predict — otherwise called “known unknowns” — in certain datasets and models, data observability accounts for every issue that might arise across your entire data stack. Testing validates your assumptions about data, such as “no null values in this table” or “values in this column should always be between 0-10”.
By contrast, observability will tell you when a dashboard hasn’t updated for a month, a change to your codebase caused an API to stop collecting data, or an accidental update to your ETL meant certain tests didn’t run in the first place.
These “unknown unknowns” can lie dormant in your datasets for days, weeks, or even months, potentially impacting downstream reports or products without ever being detected by a traditional data test. Since data observability tooling integrates across your entire data ecosystem, including dbt, you get end-to-end coverage and full visibility at every step of the pipeline. Observability also uses machine learning and automation to scale (without requiring manual work to write and maintain tests), saving immense time and resources over the long run.
How dbt testing and data observability work together
None of this is to say that dbt tests aren’t absolutely necessary. They are — testing your datasets and models can help catch issues before data enters production. But even the most comprehensive dbt tests can’t detect every possible problem that may arise, and they won’t catch issues that occur outside of the transformation layer of your data stack.
That’s why dbt testing and data observability can work together beautifully to ensure your data is trustworthy, reliable, and available when and where your data consumers expect it. The Monte Carlo integrations with dbt Core and dbt Cloud provides streamlined notifications, troubleshooting, metadata management, and more. It’s how leading data teams, like our friends at Blend, are optimizing data modeling and improving reliability at scale.
Curious to learn more? We could talk data quality all day long. Contact our team to get into the weeds on data testing, data observability, and how they work together to deliver data reliability.
Our promise: we will show you the product.
Read more posts.