Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Blend Scales the Impact of Reliable Data with dbt Cloud and Monte Carlo


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Leveraging new data sources is a big part of scaling data adoption. But becoming a data-first organization is about more than just ingesting new data.
The real challenge is what you do with all that data once you have it.
And once you have it, how do you trust it?
Here’s how Blend, a cloud infrastructure platform powering digital experiences for some of the world’s largest financial institutions, combined cloud-based data transforms and data observability to deliver trustworthy insights faster.
Blend powers billions of dollars in transactions each day in its mission to reimagine the future of online banking.
Central to this mission? Fast, accessible, and most importantly, reliable data. DC Chohan, Senior Data Engineering Manager, is helping lead the charge toward data adoption at Blend. “As we’re growing, the number of sources are growing—the number of people relying on data is increasing… Today, we have around 32 sources of data… And 11 to 12 different teams utilize the data on top of our platform,” DC said.
As Blend’s data needs began to grow, it became increasingly difficult to harness their data effectively on their existing platform. More data was critical to power their internal insights and customer-facing products—but they also needed a data platform that could operationalize that data in a way that was fast and accurate.
The challenge: optimizing data modeling and improving reliability at scale
As an enterprise-level cloud-banking platform supporting the likes of Wells Fargo, Blend’s data needs are as large as they are complex.
With three distinct data teams and dotted lines to both growth and revenue operations, Blend’s data function provides operational data supporting everything from product development to standard measuring and performance reporting.
In addition to internal data users, Blend also leverages data in a variety of external data products as well—including the integration of sensitive PII data from their customers’ end users.
But manual SQL querying and a lack of sufficient data quality monitors left Blend with limited engineering resources to develop new products and anomalous data that was prone to cause incidents for users downstream.
Manual transformation querying draining engineering resources
In the early days, the data team was relying entirely on a series of manually scheduled SQL queries in Airflow to manage operational workflows and feed external data products.
But as the company—and its data—began to scale, so too did their bottlenecks. While their SQL queries were technically capable of delivering data to products and BI tooling, the queries were becoming increasingly difficult to run and iterate, requiring constant redeploy fixes to keep pipelines moving.
And because each query was manually created and executed in Airflow, teams like Product Analytics were fully dependent on data engineering to create and implement new workflows. If a new transformation request came in from analytics, either another priority project would need to be paused or analytics would be left waiting until engineering could action the request.
Insufficient data quality monitoring
When it came to managing data reliability, things weren’t any simpler. While more tables and sources meant more opportunities for data discovery, they also meant more opportunities for anomalous data to cause mischief downstream.
“We had an incident where our revenue numbers were skewed…and it was because we weren’t doing the calculations of data quality well,” DC said.
Understanding the importance of data quality, the data team attempted to create a POC data quality framework in-house, using orchestrated validation queries.
“It was supposed to run on some schedule to try to detect anomalies in data…but when we ran it, [the monitors] completely overwhelmed our warehouse… Not only were queries taking a long time, but it was just taking a lot of CPU on the Redshift cluster,” said Albert Pan, a software engineer at Blend.
Recognizing the imminent need to reevaluate their platform’s infrastructure, the team began looking for tooling resources that would allow them to operationalize their data more effectively for modeling and discovery while also ensuring the data was reliable for end users.
With limited time to stand up new integrations, the team needed accessible and easy to scale solutions that worked out of the box.
Enter dbt Cloud and Monte Carlo.
The solution: dbt Cloud and end-to-end observability through Monte Carlo
The Blend data team had three objectives: reduce bottlenecks, improve data reliability, and maintain velocity as their data needs grew.
The solution to their scalability and reliability woes lay in the combination of dbt Cloud and Monte Carlo—where efficient transformation and modeling meets hyper-scalable end-to-end quality coverage.
Improve speed-to-insights with modular SQL and automated anomaly detection
Modular SQL development
dbt Cloud was the natural evolution of Blend’s existing workflows. While it operated under a similar SQL framework to what the data team had created within Airflow, dbt Cloud was purpose-built for the challenges Blend was facing at scale.
Unlike the manual queries the data engineering team had been laboriously creating for each use case, dbt operated on a modular system, allowing the team to run workflows and develop data products faster on the fly.
And because the system was modular, it enabled data practitioners like analysts to self-serve development as well, operating as ad-hoc engineers to create queries and transforms as needed and optimizing engineering resources for priority projects.
“Because a lot of the work in understanding data is within the product analytics team, we didn’t want to have [data engineering] be a roadblock,” said Albert. “We wanted to give them a self-serve tool to be able to develop on, and dbt was a really great way for them to do that.”
Automated end-to-end anomaly detection
But faster insights are only as good as the data they’re built on. And up to that point, Blend had struggled to qualify the health of their data in a meaningful way. What the data team needed was an efficient way to monitor for anomalies across the full breadth of Blend’s sources and production tables without the need for manual configuring.
“A year ago, data discovery was the most important. We were asking, ‘what should we do with this data?’ Now we’ve reached a stage where data reliability is the most important,” DC said. “We want to calculate ROI for everything we invest in. The market has changed the strategy of how we reliably use the data. And that’s where Monte Carlo comes into the picture providing that insight in a very reliable way.”
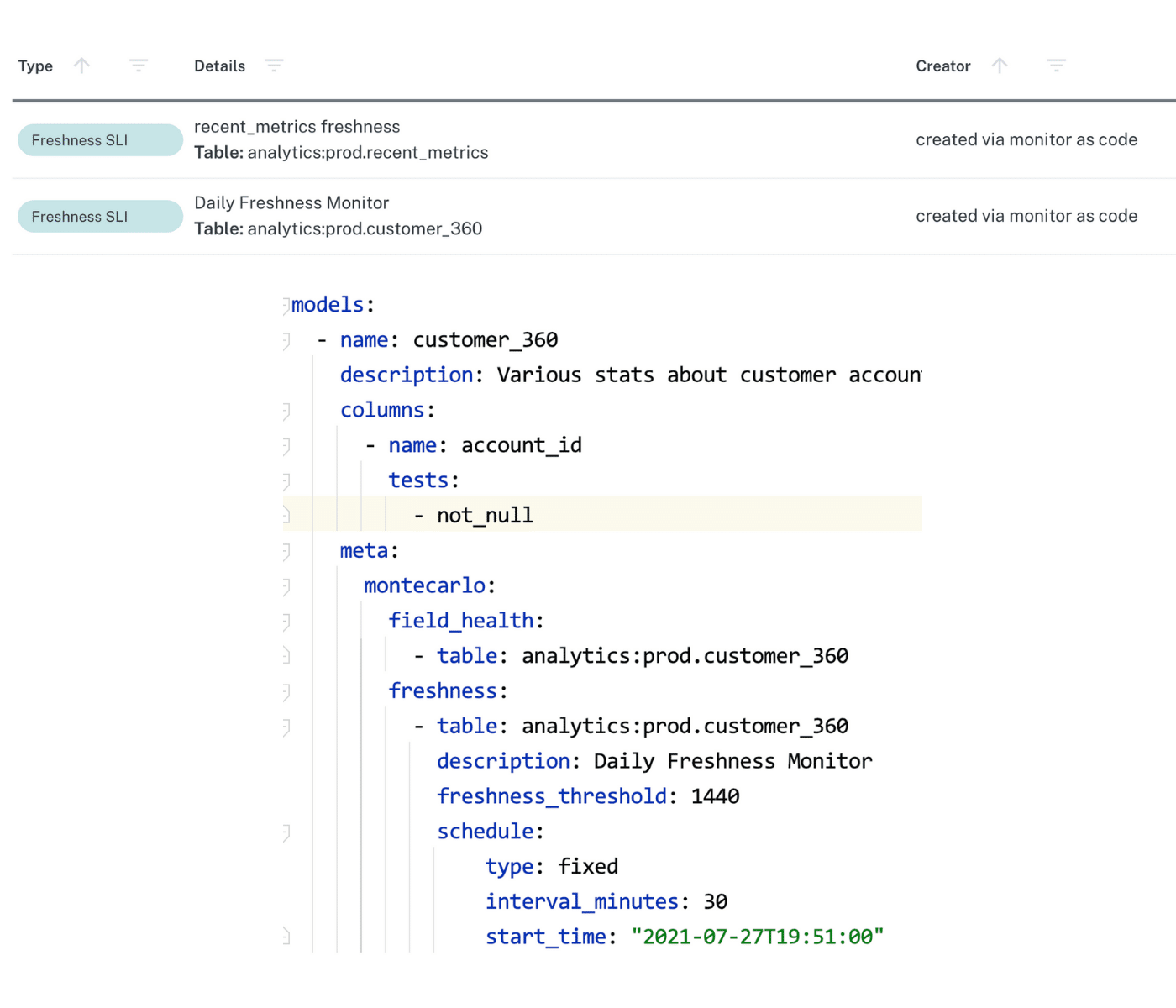
Utilizing Monte Carlo’s no code implementation, Monte Carlo’s ML-powered monitors were instantly deployed across 100% of Blend’s production tables out-of-the-box— evaluating freshness, volume, and schema changes automatically without any configuring or thresholding.
“It really started becoming a very automated workflow where we didn’t have to tune it or babysit it a lot,” Albert continued.
Monte Carlo’s automatic field-lineage also meant the team could root-cause incidents at a glance, resulting in faster resolutions and a deep understanding of the downstream impact of anomalies across pipelines.
Meet external data SLAs with system stability and Slack alerts for breakages
While Blend’s Airflow framework provided a means for the data engineering team to manually schedule queries, the system was bulky, tedious, and prone to frequent breakages, making it nearly impossible to use as a reliable solution for external data products.
“Given that Blend is enterprise software handling data for a lot of large financial institutions, our data is a product ,” said Noah Hall, a product analyst at Blend. “Without dbt, we just wouldn’t be able to live up to the kind of agreements we have in terms of providing them visibility into their own data…or it would take many more months to actually get these products out the door.”
And if anything within their customer-facing data products did break—or anywhere else for that matter—Monte Carlo would be there first with automated alerting through Slack to alert to breakages in real time, while also giving Albert, DC, and the rest of the team the tools to fix them.
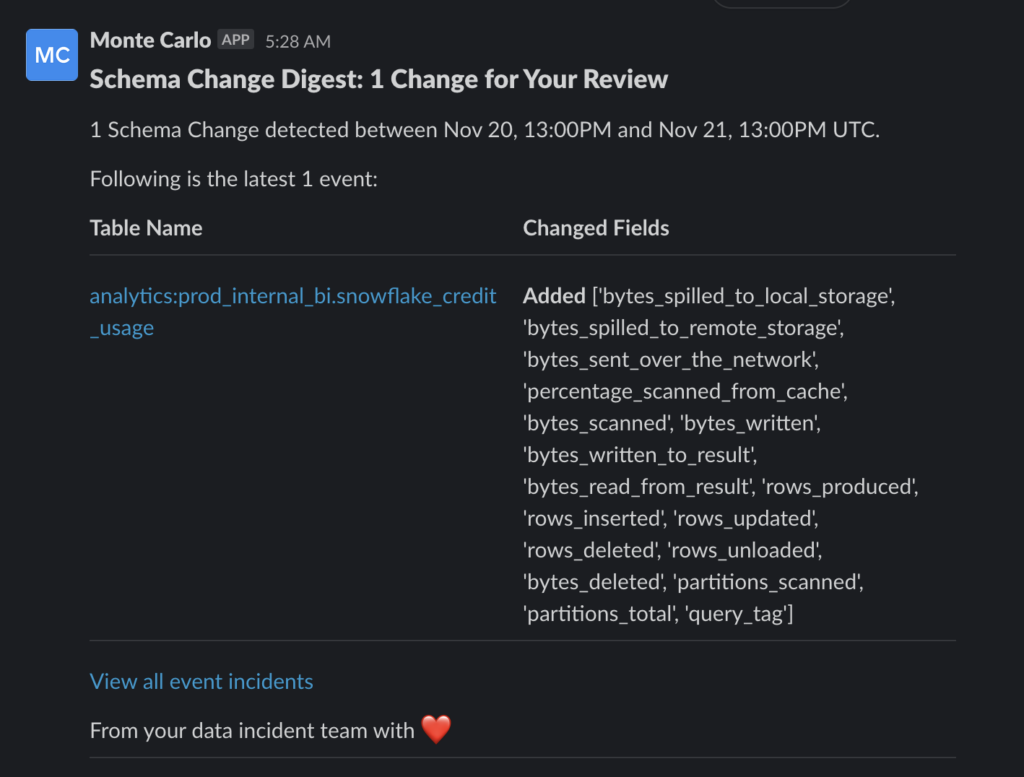
“We have many cases where folks would say, ‘Hey, we’re not seeing this data. We’re not seeing these rows. Where are these?’” said Albert. “It’s never great when a customer tells you that something is wrong or missing. So, we wanted a proactive solution that could tell us when something is wrong, and we can fix it before they even know. That’s one of the main reasons why we use Monte Carlo.”
Minimize compute-power with pre-processed operations and metadata monitoring
Modular SQL operations to pre-process data
Blend divides its codebase into a variety of microservices to support customer applications. Unfortunately, most of the processing required for these SQL operations are too compute intensive to execute live as dashboards are opened by users.
To reduce the strain on Blend’s compute resources, the product analytics team uses dbt’s modular SQL framework to pre-process complex SQL operations before creating the dashboards that will ultimately be consumed by internal and external users.
“An application might use different microservices for different income verification integrations in the mortgage application process. So, to even get the foreign key out of one of those microservices that will allow you to join it back to the application ID might be stored in a JSON blob,” said Noah. “We use dbt to modularize that different microservices data and extract some of those key pieces of information so that we can build out the clean end-user data into a table that will be queryable efficiently by our dashboarding tools.”
Comprehensive metadata monitoring for freshness, volume, and schema changes across production tables
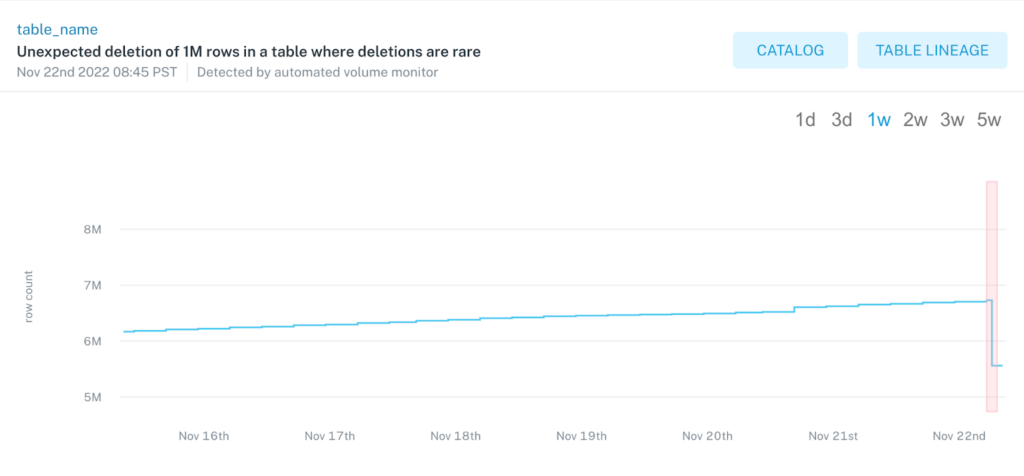
Unlike Blend’s in-house POC program which relied on time-intensive and CPU-heavy queries within their Redshift cluster, Monte Carlo’s end-to-end data observability minimized impact on warehouse performance.
“One of the things Monte Carlo offers is a very light way to [monitor data] by collecting metadata, which doesn’t impact warehouse performance on a significant level like our original POC project did,” said Albert.
Monte Carlo’s monitors avoid excessively querying data directly by using that metadata, pulled from native objects such as information schema, to automatically generate thresholds for freshness, volume, and schema changes. Those thresholds continue to be updated over time as well, to ensure that updated processes are accurately reflected in data quality rules. This solution saved on Blend’s compute costs while simultaneously giving the data team visibility into the health of its pipeline from ingestion to consumption.
In addition to broad monitoring across all of its tables, Monte Carlo also allows the data team to opt-in to deeper custom data monitors on critical data sets to identify when the data fails a specific user-defined logic as well.
By using Monte Carlo’s automated monitoring for common anomalies and limiting custom monitors to critical production data sets, the data team was able to provide powerful cost-effective quality coverage across Blend’s pipelines without sacrificing deep monitoring where it counts.
Outcome: Immediate time to value, reduced compute costs, and improved data reliability
dbt’s cloud-based transformation tool democratized data development at Blend by offering a modular approach to SQL queries that gave development power to analysts and practitioners while improving the stability of the platform.
Meanwhile, Monte Carlo provided scalability for data quality by offering a solution that went beyond the warehouse to provide convenient data quality coverage for Blend’s entire pipeline—from ingestion to consumption—right out of the box.
By combining the operational efficiency of dbt Cloud’s data transform tools with the scalability of end-to-end data observability through Monte Carlo, Blend has:
- Reduced time-to-value by 4 months for a new data quality solution when compared to internal POC frameworks
- Improved data trust for internal and external users with automated data quality checks across tables
- Dramatically improved speed-to-insights with modular SQL development for practitioners
- Reduced warehouse and compute costs with pre-processed SQL operations and broad automated metadata monitoring
What’s next?
Transformation and data observability solutions in hand, the data team has already set their sights on building out new infrastructure and data products utilizing their new resources.
“At the infrastructure level, we’re going to focus on building real time pipelines and a tracking framework… And on the other side, we also want to keep enhancing our products, which is the STP that we service our external users,” said DC.
Continuing to champion Monte Carlo to data users outside their team and integrating observability into existing platforms also remains a high priority on Blend’s data roadmap.
Integrating dbt Cloud and Monte Carlo has not only enabled Blend to harness their data faster—it puts their data consumers at the top of the priority list. And if that’s not a win, what is?
Wondering how dbt Cloud and Monte Carlo can integrate with your data stack? Reach out to our teams!
Our promise: we will show you the product.
Read more posts.