Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 3 Reasons You Can’t Rely on Testing Data Pipelines to Find Quality Issues

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
In 2021, testing data pipelines alone isn’t sufficient for ensuring accurate and reliable data. Just as software engineering teams leverage solutions like New Relic, DataDog, and AppDynamics to monitor the health of their applications, modern data teams require a similar approach to monitoring and observability. Here’s how you can leverage both testing and monitoring to prevent broken data pipelines and achieve highly reliable data.
For most companies, data is the new software.
Like software, data is fundamental to the success of your business. It needs to be “always-on”, with data downtime treated as diligently as application downtime (five nines, anyone?). And just like your software, adhering to your team’s data SLAs is critical for maintaining your company’s competitive advantage.
While it makes sense that many teams would approach testing their data with the same tried-and-true methods they apply to testing the accuracy and reliability of their software, our industry is at a tipping point: testing data pipelines alone is insufficient.
Relying on testing data pipelines to find issues before you run analysis is equivalent to trusting integration and unit testing to identify buggy Python code before you deploy new software, but it’s insufficient in modern data environments. In the same way that you can’t have truly reliable software without application monitoring and observability across your entire codebase, you can’t achieve full data reliability without data monitoring and data observability across your entire data infrastructure.
Rather than relying exclusively on testing data pipelines, the best data teams are leveraging a dual approach, blending unit testing data pipelines along with constantly monitoring data pipelines. Let’s take a closer look at what this means, and how you can start to monitor data pipelines across your own stack.
What do we mean by testing data pipelines?
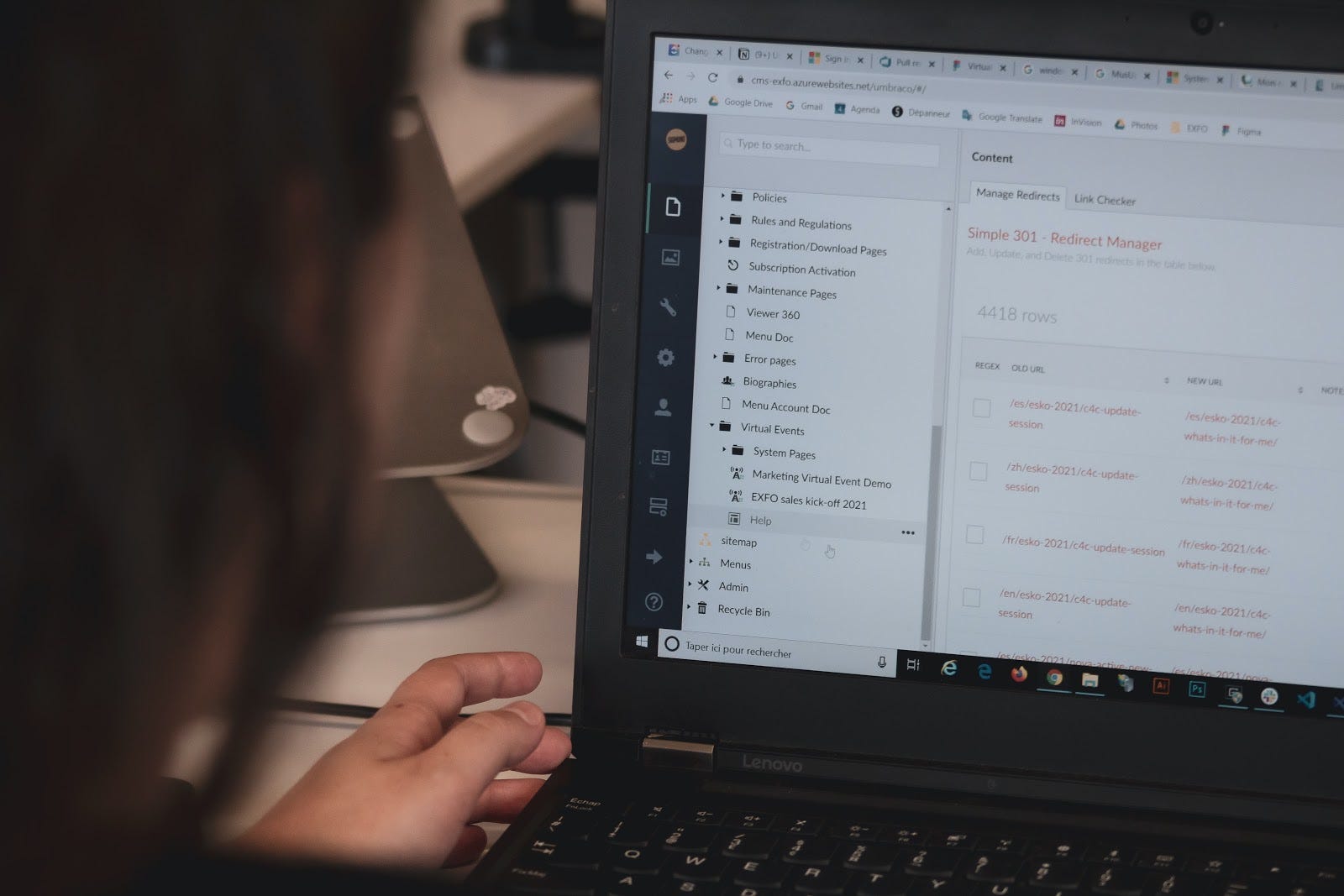
Data pipeline validation involves testing your assumptions about your data at different stages of the pipeline. Basic data pipeline testing methods include schema tests or custom data tests using fixed data, which can help ensure that ETLs run smoothly, confirm that your code is working correctly in a small set of well-known scenarios, and prevent regressions when code changes.
Testing data pipelines helps by conducting static tests for null values, uniqueness, referential integrity, and other common indicators of data problems. These tools allow you to set manual thresholds and encode your knowledge of basic assumptions about your data that should hold in every run of your pipelines.
In fact, testing data pipelines is a great solution for specific, well-known problems and will warn you when new data or new code breaks your original assumptions. You can even use testing to determine whether or not your data meets your criteria for validity — such as staying within an expected range or having unique values. This is very similar in spirit to the way software engineers use testing to alert on well understood issues that they anticipate might happen.
But, much in the same way that unit tests alone are insufficient for software reliability, testing data pipelines by itself cannot prevent data quality issues.
Here are 3 reasons why a hybrid approach that marries testing and monitoring is needed to pave the way forward for the modern data stack.
1. Data changes, a lot
In software engineering, we heavily use testing to find anticipated issues in our code. However, every software engineer knows this is insufficient if she is looking to deliver a highly reliable application. Production environments tend to have much more variability than any engineer could hope to anticipate during development.
Whether it is an edge case in business logic, hard-to-predict interactions between software components, or unanticipated input to the system, software issues will inevitably occur. Therefore, a robust strategy to reliability will combine testing as a sanity check, with monitoring and observability to validate correctness and performance in the actual production environment.
Data is no different. While testing data pipelines can detect and prevent many issues, it is unlikely that a data engineer will be able to anticipate all eventualities during development, and even if she could, it would require an extraordinary amount of time and energy.
In some ways, data is even harder to test than traditional software. The variability and sheer complexity of even a moderately sized dataset is huge. To make things more complicated, data also oftentimes comes from an “external” source that is bound to change without notice. Some data teams will struggle to even find a representative dataset that can be easily used for development and testing purposes given scale and compliance limitations.
Monitoring and observability fill these gaps by providing an additional layer of visibility into these inevitable — and potentially problematic — changes to your data pipelines.
End-to-end coverage is critical
For many data teams, creating a robust, high coverage test suite is extremely laborious and may not be possible or desirable in many instances — especially if several uncovered data pipelines already exist. While testing data pipelines can work for smaller pipelines, it does not scale well across the modern data stack.
Most modern data environments are incredibly complex, with data flowing from dozens of sources into a data warehouse or lake and then being propagated into BI/ML for end-user consumption or to other operational databases for serving. Along the way from source to consumption, data will go through a good number of transformations, sometimes into the hundreds.
The reality is that data can break at any stage of its life cycle — whether as a result of a change or issue at the source, an adjustment to one of the steps in your data pipeline, or a complex interaction between multiple data pipelines. To guarantee high data reliability, we must therefore have end-to-end visibility into breakages across the ETL pipeline. At the very least, we must have sufficient observability to be able to troubleshoot and debug issues as data propagates through the system.
Testing data pipelines becomes very limited with that in mind for a several reasons, including:
- Your data pipelines may leverage several ETL engines and code frameworks along the way, making it very challenging to align on a consistent testing strategy across your organization.
- Strong coupling between transformations and testing introduces unreliability into the system — any intended change to ETL (or, in some cases, unintended failure) will lead to tests not running and issues missed.
- The complexity and sheer number of data pipeline stages can make it quite onerous to reach good testing coverage.
And this just scratches the surface of data testing’s limitations when it comes to ensuring full data reliability.
Data pipeline testing debt
While we all aspire to have great testing coverage in place, data teams will find that parts of their data pipelines are not covered. For many data teams, no coverage will exist at all, as reliability oftentimes takes the backseat to speed in the early days of data pipeline development.
At this point, going back and adding testing coverage for existing data pipelines may be a huge investment. If key knowledge about existing data pipelines lies with a few select (and often very early) members of your data team, retroactively addressing your testing debt will, at the very best, divert resources and energy that could have otherwise been spent on projects that move the needle for your team. At the very worst, fixing testing debt will be nearly impossible if many of those early members of your team are no longer with the company and documentation isn’t up to date.
A solid data pipeline monitoring and data observability approach can help mitigate some of the challenges that come with data testing debt. By using an ML-based approach that learns from past data and monitors new incoming data, teams are able to create visibility into existing pipelines with little to no investment and folklore knowledge, as well as reduce the burden on data engineers and analysts to mitigate testing debt as it accrues.
The next step: data monitoring and data observability
In 2021, data engineers are at a critical juncture — keep pace with the demands of our growing, ever-evolving data needs or settle for unreliable data. For most, there isn’t a choice.
Just like software, data requires both testing and monitoring to ensure consistent reliability. Modern data teams must think about data as a dynamic, ever-changing entity, and applying a different approach that focuses not just on rigorous testing, but also continual monitoring and observability.
By approaching data reliability with the same diligence as software reliability, data teams can ensure the health of their data at all times and across several key pillars of data health, including volume, schema, freshness, lineage, and distribution — before they affect your business.
Want to learn more about the differences between testing data pipelines and data observability? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.