Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Dr. Squatch Keeps Data Clean & Fresh with Monte Carlo


Michael Segner
Michael writes about data engineering, data quality, and data teams.
Dr. Squatch provides natural products specifically formulated for men who want to feel like a man, and smell like a champion.
Making data-driven decisions is critical for the company to “raise the bar” on men’s personal care products according to their VP of Data, IT & Security, Nick Johnson.
“Our mission as a data team is to help all of our decision makers across the business–from marketing and product to customer experience and finance–make better decisions that are informed by data,” Nick said.
As a result, Dr. Squatch’s data team focuses on analytics and reporting use cases that provide actionable insights to the broader company. Most employees have access to domain specific dashboards and will also engage the data team when their questions are deeper than a dashboard can answer.
“We have a sole data engineer and the rest of our team is pretty analytics focused. You can think of it as nine analytics folks and our singular hero on data engineering. Each analyst is aligned to one or more teams within the business to ensure all of our stakeholders get data support,” said Nick.
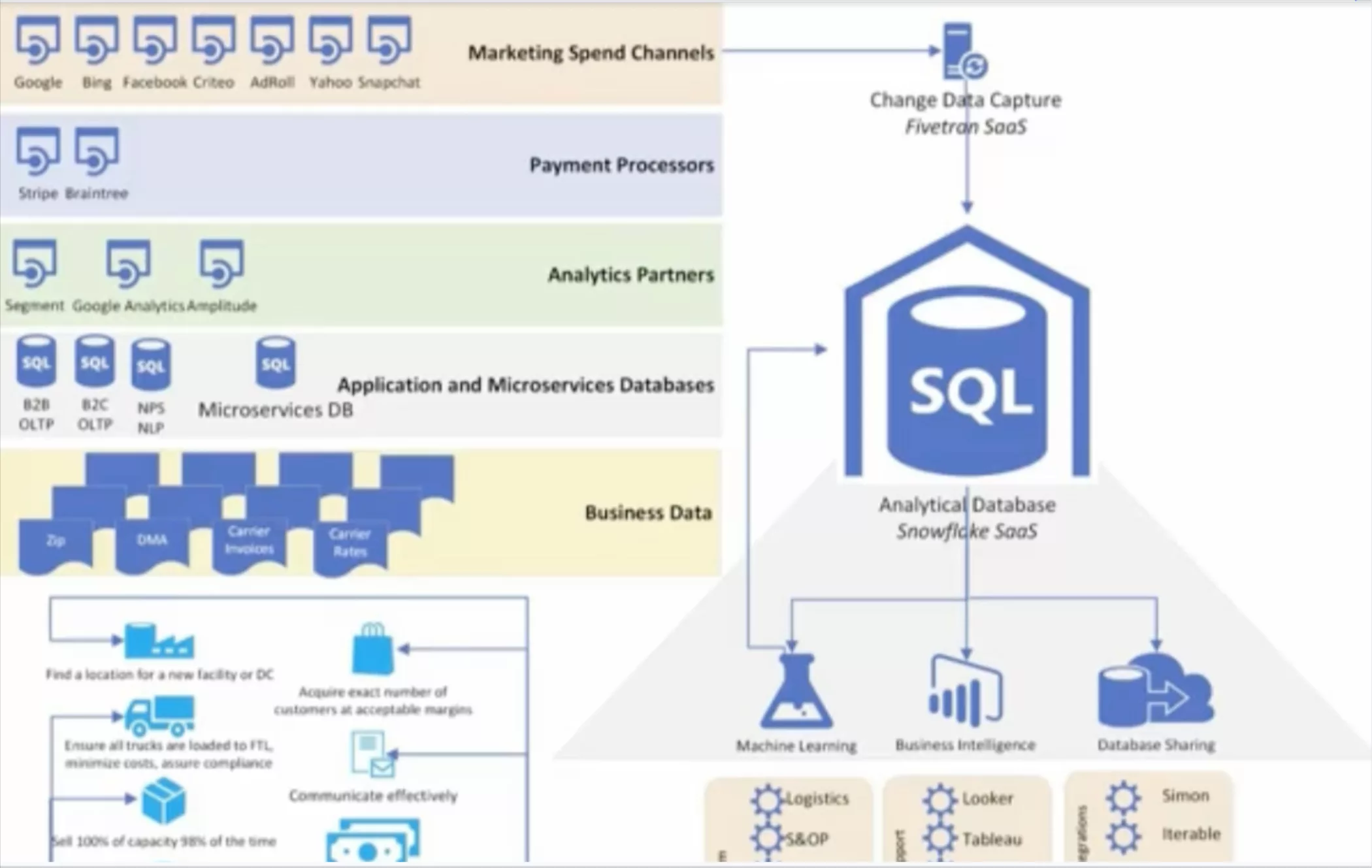
Their stack consists of Snowflake for storage and compute; Fivetran and custom-built pipelines for ingestion; Prefect for orchestration; dbt for transformation; and Looker as their visualization tool.
They’ve also added a cost optimization tool called Keebo that sits on top of Snowflake. Keebo learns Dr. Squatch’s warehouse usage then determines times when it’s best to reduce/increase warehouse size and time-out periods to maintain performance while decreasing cost.
To ensure that their stack was able to deliver high quality data across their myriad analytics use cases, they relied on data testing with dbt. While effective at capturing known issues, like null values and duplicates, they quickly realized that they needed a more comprehensive approach to reliability to maintain fresh data as they grew.
“We had a lot of dbt tests. We had a decent number of other checks that we would run, whether they were manual or automated, but there was always this lingering feeling in the back of my mind that some data pipelines were probably broken somewhere in some way, but I just didn’t have a test written for it,” said Nick.
The solution? End-to-end data observability with Monte Carlo.
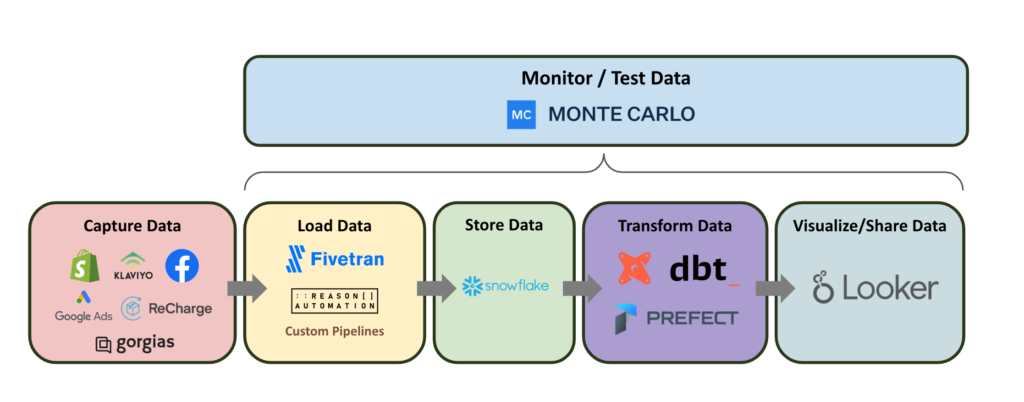
Challenge: Capturing anomalies to prevent broken pipelines and inaccurate analytics
The team evaluated multiple data quality monitoring solutions before launching formal evaluations of Monte Carlo and a competitor that relied nearly exclusively on manual threshold setting.
“The other tool just required too much setup. It was almost like setting up a custom model for every field that we cared about, which wasn’t exactly what we were looking for,” said Ken Nguyen, the ‘singular data engineering hero’ at Dr. Squatch. “We needed something to look at everything at once, which is exactly what Monte Carlo is.”
“The main criteria we had was to save time while expanding our monitoring coverage. Instead of needing to set up every test for every field that we add, we can now just safely assume Monte Carlo will cover that. It’s not feasible to write the same test for every field,” he added.
The Dr. Squatch data team also sought to ensure they were the first to know about any anomalies and dramatically reduce their time-to-detection.
Solution: Real-time anomaly detection and lineage across all production tables
Given the multi-layered dependencies of their data products and dashboards, Ken, Nick, and the rest of the Dr. Squatch team knew that they needed their observability to cover more than just a few key tables.
“Before Monte Carlo, if there was an issue that made its way into a dashboard, but nobody on that team used the dashboard for a bit, that could have been a problem for 12, 18 or more hours before they notify you it’s broken,” said Nick.
Now, with Monte Carlo, they are alerted either before or at the same time as their users, which allows them to take action faster – before it causes an issue downstream.
“There’s also a reputational component. If your team is getting out ahead of data incidents, that’s just better than a business stakeholder flagging it for you,” he said.
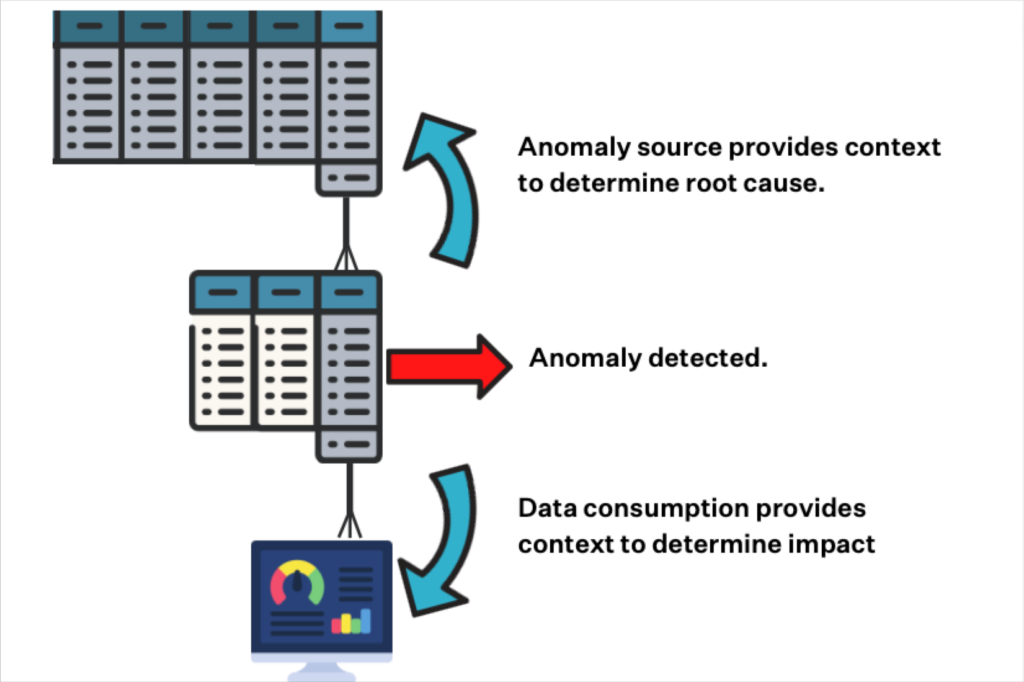
Broad monitoring across every table in their warehouse along with end-to-end data lineage has provided new context into incidents, improving their time-to-resolution for data quality issues by several hours.
“The fact we can see data outages on the specific table or schema really helps us identify where the data anomaly is coming from. Is it coming from Fivetran directly? Is it coming from some model in dbt? This is another place where we save time,” said Ken.
Outcome: Immediate time-to-value with out-of-the-box ML-based monitors
For Dr. Squatch, the Monte Carlo setup was easy and time-to-value was instant.
“Immediately when we turned on Monte Carlo, it started flagging stuff that we hadn’t looked at. We were getting useful alerts on the first day,” said Nick.
As the primary person tasked with resolving data anomalies, Ken has found Monte Carlo anomaly alerting to be accurate and modular.
“One of my favorite features of the platform is how I can curate what types of anomalies get alerted on Slack and to what channel they get routed. I think that helps a lot where it flags things we should take a look at, grouping them in such a way to avoid alert fatigue,” he said.
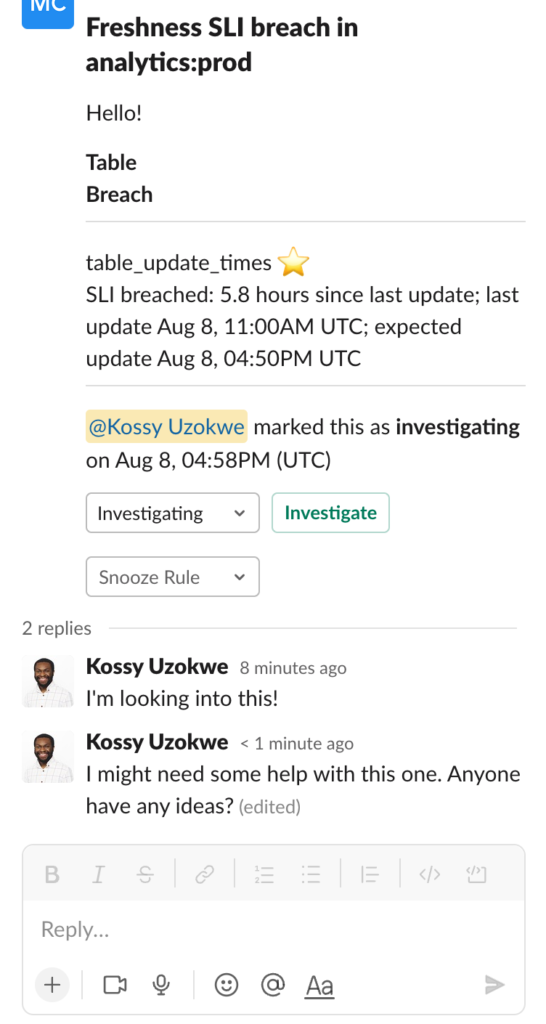
Dr. Squatch data analysts and data engineers also find Monte Carlo’s automated data monitoring and alerting to be a valuable complement to their dbt and data modeling activities as well.
“With data observability, our analysts know almost immediately if there’s a big problem, which is a huge time saver. Obviously, the code goes through multiple reviews, but no process is perfect,” said Associate Director of Analytics & Strategy Danielle Mendheim.
“If there is an issue, it can be addressed immediately while the pull request is fresh in their mind rather than having to readjust a sprint weeks later to account for it. I’d estimate it saves our analyst team a couple of hours every week from having to re-open pull requests and adjust code.”
The team has also found Monte Carlo’s incident resolution features, including Anomalous Row Detection, to be major time savers as well.
“When an error does pop up, whenever a root cause analysis insight is there, that eliminates the time we would need to take to manually query the error to see what it is,” said Ken. “The platform automatically shows how this specific field is correlated with this change and we can quickly understand the error.”
For example, once the team saw a spike in an increased number of rows that correlated to a specific country, which made it easy to dismiss because they had just launched in that country. They were happy that it was flagged even if it didn’t require any action, saving them time and stress.
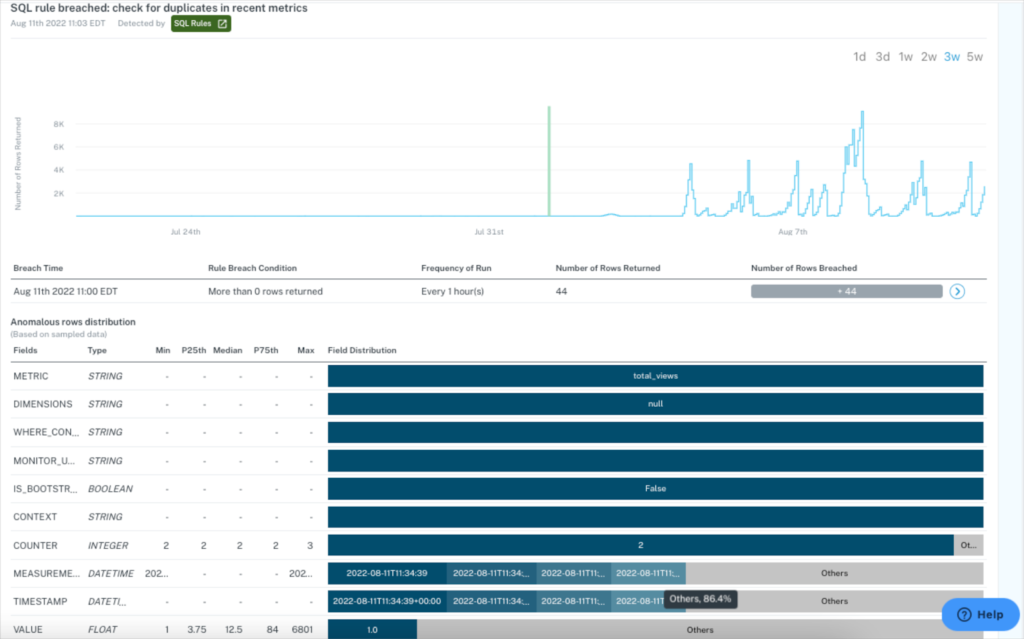
Outcome: Quick impact analysis with end-to-end lineage and data platform insights
By using data lineage to understand the impact of an incident downstream, Danielle and her team can be proactive communicators and partners to the business.
“I use lineage when we have big data outages and I need to know what and who it’s impacting. I’m able to inform our stakeholders if their data is down or if it hasn’t been affected because I can see all of that in the lineage,” she said. “Our analysts will also use lineage graphs to understand how any changes they make may impact data assets downstream.”
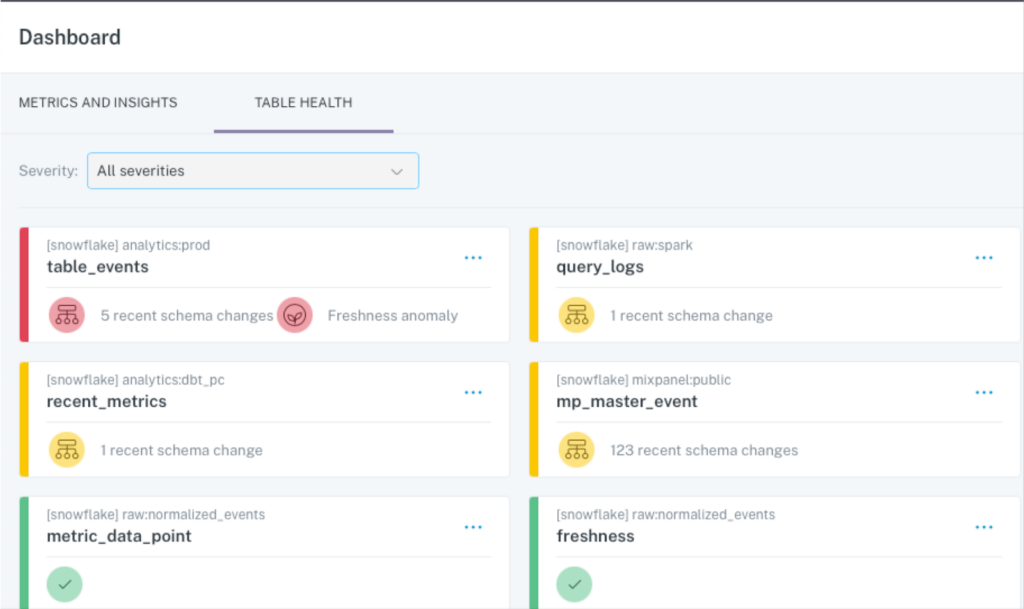
One of Nick’s favorite features are Monte Carlo Insight Reports which has enabled him to prioritize resource allocation to effectively prevent incidents before they occur.
“Monte Carlo has given me a better picture of which pipelines and data sources are the most problematic. So if there is a source always throwing errors or never showing up on time, we can either swap sources, get a new software tool, or change our pipeline in some way to prevent these errors,” he said. “The platform gave me a mental picture of where to invest time fixing pipelines or changing data sources because that is where we are seeing the most frequent errors. Whereas before Monte Carlo, we’d only see a portion of the errors that were flagged by a stakeholder or maybe a dbt test.”
Nick is also a self-described fan of deleting or retiring unused data assets that are surfaced by both lineage and Insight Reports.
“The whole team is trying to build new things and I’m trying to prune them. I like being able to go into lineage and in a singular, unified view see if a table is useful. Previously I would have had to look at the DAG, go into dbt, and then go into Looker and see what tables are referencing this model table. I love lineage” he said. “The clean up suggestions are great too. It’s just easy validation. You can clean things faster that way and it’s a good guardrail for knowing what not to delete.”
Results: 10+ hours per week saved and future data downtime prevented
Monte Carlo has generated concrete results for the Dr. Squatch data team, not the least of which is increasing their “singular data engineering hero’s” capacity by about 15%.
“I would say it saves me around an hour a day from not having to set up tests or manually checking certain areas every morning. Instead I get sent a Monte Carlo alert in a Slack channel, which is incredibly convenient,” Nick said.
Coupled with the several hours per week saved by Nick, Danielle, and the broader data organization, this led to 10+ hours of time savings per week – time better spent helping their team generate reliable insights for the business.
The Dr. Squatch team has also been able to leverage Monte Carlo and its field health monitors to prevent errors that may otherwise have had an impact on the business.
“We use field health monitors on our critical tables to look at things like the discount percentage. If the discount percentage is extremely high, or we’ve had a spike in people coming in with $0 orders that shouldn’t be, we take action fast,” said Nick.
Danielle remembers a specific instance where lineage helped the analyst team avoid negative consequences downstream as well.
“An analyst pushed a change, and all three of us approved the pull request. Somehow we had missed the kinds of downstream duplicates the change would cause. It was crazy to me how fast we were able to identify that,” she said. “We got the alert as soon as it ran, and we knew exactly where that duplication was happening. I didn’t even have to be involved. The analyst was able to figure out where to fix the code. It saved us a lot of time in the long run.”
For Ken, knowing Monte Carlo has his back allowing him to provide high-quality data to the rest of the organization is priceless.
“I would say peace of mind is the biggest value. You can trust what the data is doing and focus on other places instead of dividing your attention. That kind of focus is extremely valuable.”
Interested in learning how you, too, can have squeaky clean data? Reach out to Michael and the rest of the Monte Carlo team.
Our promise: we will show you the product.
Read more posts.