Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Build vs. Buy Guide for the Modern Data Stack


Nishith Agarwal
Nishith Agarwal is the Head of Data & ML Systems at Lyra Health. Previously, he served as the Head of Big Data Compute & Storage Platforms at Uber. He is the co-author and PMC of Apache Hudi.
For even the youngest companies, data has become a key differentiating factor, helping organizations secure the competitive edge, build better products, and deliver improved customer experiences.
Nishith Agarwal, Head of Data & ML Platforms at Lyra Health and creator of the popular open source data management framework, Apache Hudi, outlines his blueprint for building (and buying) the data stack of your dreams. In Part I of this series, Nishith discusses some initial considerations and shares a framework for getting started.
In 2022, the data tooling ecosystem is maturing faster than ever before—from the emergence of the data lake house and managed streaming services like Confluent, to impactful and widely adopted new open source tools like dbt, Apache Airflow, and Apache Hudi. Building a data platform has simultaneously never been easier—and more nuanced.
So, with so much change, where do you start?
In this article, I’ll walk through my experience building data platforms for the teams at Walmart Labs, Uber, and Lyra Health to illustrate when I think it makes sense to invest in new tooling, and attempt to answer that age old engineering question: should you buy it or build it yourself?
Over the next several weeks, I’ll be sharing my thoughts on the build versus buy debate as it relates to each of the critical components of your data stack by utilizing the considerations I’ll outline in this article.
Let’s jump in.
Build vs. buy considerations
Back when my career in data first started, there weren’t all that many tooling options available for critical platform functions. So, if we needed something specific for our data stack, building was really our only option.
However, fast-forward to today that’s all changed rather dramatically. There’s been an explosion of solutions powering the data stack, from cloud-based transforms to data observability. This makes the question of “build versus buy” increasingly important for modern data leaders.
If you’ve hired for your data team recently, you know that data engineers are hard to come by. While purchasing new tooling could place additional stress on your bottom line, not purchasing tooling will put that burden back on your engineers. Everything in life is a negotiation—and data platforms are no different.
So, what’s the right answer? Should you take advantage of all those slick new commercial options? Leverage open source tooling? Build components from scratch? A bit of all three?
Well, like all great questions, the answer is… it depends.
In my experience, this question ultimately boils down to five main considerations: cost, complexity, expertise, time to value, and competitive advantage.
So, let’s take a look at each of those in a bit more detail.
Cost & resources
I know, this one’s a bit obvious, but I like to think there’s some nuance to the question beyond simply what’s printed on the sticker price.
Here are some questions I would ask when considering the cost of building or a buying new data tooling:
- What’s your budget for this component of your data stack?
- Will it cost more to hire and train data engineers to build this part of your stack or leverage a managed tool out of the box?
- What opportunities would you lose out on by dedicating resources to building out new tooling?
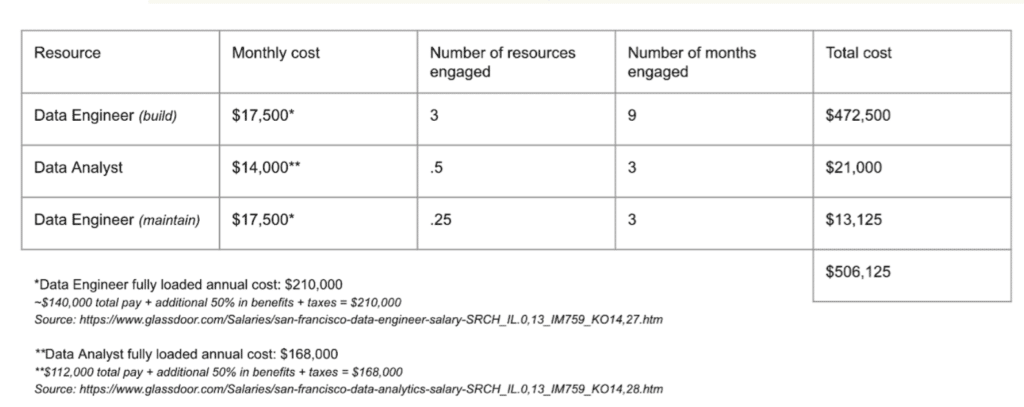
Let’s consider a real world example. When the data team at a leading InsurTech provider was investigating building their own data observability solution in-house, they calculated it would require 30 percent of their data engineering team to build a comprehensive anomaly detection algorithm.
Now at face value, that doesn’t sound so bad. However, when they ran those numbers against the hard costs associated with each of those engineers, they realized that hard cost was actually upwards of $450,000 per year to build and maintain their data observability tooling in-house—and that was a very different conversation.
Obvious as it is, answering just this one question is enough to steer many data leaders in one direction or another. Staffing requirements and time-to-value (which I’ll get into below) will also play a role in the hard and opportunity costs associated with choosing one approach over the other. Only you can decide which of those costs is higher for your team, and—ultimately—if that juice is really worth the squeeze.
Complexity & interoperability
Modern data stacks aren’t just bigger and more powerful—they’re also more fragmented. As organizations scale, they tend to ask more of their data platforms. Your home-built or open source solution may work with Snowflake today, but will it work once they release a major feature update? And does it work with the 20 other solutions you need to plug and play together?
That’s not to say that buying is always the right answer. Far from it. As companies scale beyond a certain point and begin to build in-house tooling to meet more nuanced data needs, that complexity can grow beyond what managed plug-and-play solutions can support. Plug-and-play solutions may only address 70% of use-cases, leaving the engineering team in a difficult spot to come up with creative, tech-debt filled solutions for the other 30%.
In this case, interoperability with the company’s high value in-house tooling becomes the greatest concern. For example, Fivetran’s ingestion tooling might not talk to your authentication mechanisms used internally, making it difficult to automate ingestion out-of-the-box.
So, we see again, there’s no one-size-fits-all solution when it comes to the question of interoperability. But as important as cost and interoperability are, neither of those questions can be answered until you know what kind of engineering resource you have to work on your platform projects. Which leads me to my next consideration: expertise.
Expertise & recruiting
Another consideration that should factor into your decision is the expertise of your team.
Whether you’re integrating a new tool, leveraging open source tools like Great Expectations, or raising up your platform from scratch, you can’t do anything without the necessary engineering support. And that means taking an honest look at your team’s time and capabilities.
What’s your team’s structure and capacity? Does your team have the expertise to build this component in-house? Will they be able to maintain it efficiently without sacrificing valuable time for other priority projects?
Throughout my career in data, the way my teams have responded to the question of build versus buy has varied pretty wildly from one organization to the next—and that’s due in large part to the skillsets of those teams.
At a company like Uber running its own data centers, you’ll find engineers with varied skill sets—from infrastructure engineers working on automating container deployments to platform engineers building pluggable and extensible platforms to support custom requirements of the Uber stack, and data engineers who are building, supporting, and maintaining the large number of datasets and models used throughout the company. So, when it came to building our data platform in-house, we could generally find the right skillset and resource to do the job—and due to the complexity of our architecture and breadth of potential use cases, finding that skillset in-house was a necessity.
But at Lyra Health, that’s not the case. We aren’t experts in building data infrastructure, so we focus more on leveraging existing cloud solutions to solve more of our infrastructure challenges while dedicating more engineering resources to leveraging our expertise in data product development.
Let’s go back to our previous example of the InsurTech platform for a moment. The hard cost for building their data observability solution was roughly $450,000. Let’s assume for the sake of argument that cost was both within budget and agreeable for their data team. That build-out still required the dedicated resource of nearly four full-time data professionals. If any of those engineers lacked experience in data quality tooling or were already at capacity maintaining critical data products, it really wouldn’t matter how much that build out cost because there wouldn’t be enough expertise available to complete it. And even if there were, there’s no guarantee what their team built would offer equivalent quality coverage or feature parity with alternative out-of-the-box solutions.
The other question to consider is how recruiting factors into your decision. Will choosing one tool over another impact your ability to hire and retain top talent in the future?
Oftentimes, data engineers will choose opportunities that enable them to expand their experience with industry standard tooling like dbt and Snowflake. So, while choosing to build your tooling in-house might make the most financial sense in the beginning, it may affect your ability to staff and retain top talent in the long-term.
Time to value
This also plays into the cost of your tooling. How long will it take to build the tool you need versus buying it? And how long will it take to realize its value? Is it a complex in-house ML tool that will require months of training? Or is it a simple SQL query you can spin up in a couple hours?
And how important is time to your team? Is it better to choose an out-of-the-box solution and realize the value of your data faster or build a custom solution to leverage your data in a different way?
Again, these are questions only you and your data team can answer.
Buying will often provide a much quicker time to value, but not always. If your company has an extensive security review process for external vendors, it can sometimes be faster to build in-house to avoid extensive approval processes in favor of meeting critical, urgent business needs. Only your team will know your specific circumstances.
But the importance of time-to-value extends beyond the initial launch of your data platform. It’s important to consider the time required to maintain your platform’s tooling as well.
An in-house tool will require more time to build—but don’t forget that in-house tooling also requires more engineering time for support and enhancements too.
Let’s take the example of data pipeline implementation. In the complexity of today’s data environments, teams and systems often need to work within a varied set of technologies. While some implementation work can be new, it often consists of fairly repetitive tasks that take up essential engineering time.
Implementing a data pipeline to integrate with varied systems might not take long in isolation, but because much of this process can be repetitive, purchasing an out-of-the-box solution like Fivetran to automate might make more sense.
Now, if your tech debt is relatively light and you have the resources available, maintaining your in-house tooling might not be a problem for your team. But as your data platform ages and functionality requirements change, remember that what worked initially might not scale so well a few years down the road—and you may end up revisiting your build versus buy discussion when that time comes.
Competitive advantage
Finally, and arguably the most salient question in the build versus buy debate: will building your own tooling give your organization a competitive advantage?
This question gets to the philosophical heart of the build versus buy debate. Can your team’s expertise really deliver demonstrable value from an in-house solution over and beyond what it could get from a managed solution? And is that even a focus for your organization?
All things being equal, if you can achieve the same strategic advantages—and meet your functional requirements—from an out-of-the-box solution, it’s probably difficult to justify the time and resources for custom tooling. However, if you need your data platform to function in a way that a managed solution simply can’t—whether because the tools lacks the appropriate feature-set or because the architectural complexities of your data environment would limit you from using a managed tool to it’s full potential—then no amount of time or money can make that solution work for your team.
It should also be noted that while there’s certainly still an advantage to be had from innovating on the data stack, those opportunity gaps are closing quickly as modern cloud-based solutions march forward. Now what competitive advantage means can vary pretty substantially from one company to the next. But feature sets, sophistication, and interoperability are value propositions that are becoming increasingly associated with out-of-the-box platform solutions. And as that gap continues to narrow, competitive advantage will come less from your platform and more from how you actually enrich, manipulate, and monetize your first party data.
Build vs buy: everything is a negotiation
Whether it’s your business intelligence or your transform tooling, there’s never a one-size-fits-all solution for every data team. How you structure your data platform will depend entirely on your own unique circumstances and how you apply these four considerations.
Key takeaways
Understand your resources and how much you’re willing to invest
Just because something sounds expensive doesn’t mean it is. Oftentimes, a solution that sounds expensive on the front end will end up saving money in the long run by reducing workload, driving down compute costs, or encouraging greater operational efficiency.
Understand the needs of your organization’s individual platform
Building can be good. Buying can be good. But both will depend on the individual needs of your platform. Knowing what’s most important to your organization and how new tooling will impact your ability to scale in the near term can give you a clear line of site into how to build out your stack today.
Understand time-to-value and the opportunity cost of building versus buying
How long are you willing to wait? Will waiting deliver a strategic advantage? Will building or buying facilitate greater interoperability in the future? The skill sets of your team and the availability of resources will determine whether it makes sense to leverage an out of the box solution or invest the time and engineering resources to build something in-house.
Remember, building is a big investment and one you shouldn’t take lightly. If you don’t understand the real value—and costs—of what you’re building, you probably aren’t ready to build it just yet.
Over the course of this series, we’ll look at each of the critical components of the data stack in more detail to discuss how cost, expertise, time to value, and competitive advantage apply across situations.
Check out Part 2—Build vs Buy: Data Warehouse, Data Lake, and the Data Lake House
Check out Part 3—Build vs Buy Data Pipeline Guide
Interested in learning more about how to build a more reliable data platform? Reach out to Nishith or the Monte Carlo team.
Our promise: we will show you the product.
Read more posts.