Product demo.
Product demo.  What is data observability?
What is data observability?  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Mesh vs Data Lake: Pros, Cons, & How to Decide


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs data lake” is right at the top of that list. But which is better? And more importantly, which one is right for your organization?
In this post we compare and contrast the data mesh vs data lake to illustrate the benefits of each and help discover what’s right for your data platform.
In a self-service data landscape, every team wants their business intelligence served up hot and fast. But while most every company would consider themselves a “data-first” organization, not every data architecture is treated to the same level of democratization and scalability.
From blunting the never-ending stream of ad hoc queries to wrangling a legion of disparate data sources, every data team understands the need to efficiently manage their organization’s data needs—and the painful reality that their current data architecture probably isn’t cutting it.
But with a seemingly endless stream of competing approaches and philosophies, what is the right way to approach your data architecture for democratization and scalability?
In this post we’ll look at the dizzyingly buzzy data mesh and how it stacks up to the more traditional aggregated architectural approach of a data lake.
Data mesh vs data lake: who will win? Let’s dive in to find out.
What is a data lake?
Before we can look at the data mesh and how this new architectural paradigm stacks up, let’s first take a deeper look at the data lake, what it is, and how it serves modern data teams.
A data lake (like Databricks) is a data repository that provides storage and compute for structured and unstructured data—often for machine learning, streaming, or data science. They allow organizations to ingest and manage large volumes of data in an aggregated storage solution when they might not be entirely sure how they’ll use that data in the future, whether for business intelligence or data products.
Data lakes offer flexibility over most warehouse solutions, but often at the cost of quality and queryability, which limits access to quick insights.
Historically, data lakes tend to be preferable for companies with large volumes of data, data science, and AI and ML training development—supported by a healthy team of data engineers.
So, what is a data mesh and what makes it different from a data lake?
Data mesh vs data lake: what’s the difference?
If a data lake is one approach to data architecture, a data mesh is its philosophical opposite. Similar to the advent of micro-services for software engineering, data mesh is a transition away from monolithic structures and towards flexibility, scalability, and accessibility.
So, what is a data mesh vs data lake? First conceptualized by ThoughtWorks consultant Zhamak Dehghani, a data mesh is a data platform architecture that embraces the ubiquity of organizational data by implementing a domain-oriented, self-serve approach to data management, while a data lake is a storage solution that prioritizes storing large amounts of unstructured data to be transformed later for consumption. A data mesh may leverage a data lake as its central data store, but is not in itself a complete data architecture that can dictate how that data will be managed.
Data mesh borrows from Eric Evans’ theory of domain-driven design, which is a software development paradigm that matches the structure and language of code with its corresponding business domain.
Unlike the monolithic data infrastructures of old that bundle storage and production into a centralized data lake, a data mesh supports distributed data. Data mesh architecture relies on domain-specific data consumers to optimize their domain’s data products—charging each domain owner with the responsibility for managing their own data pipelines based on their unique use cases—and leveraging a universal interoperability layer that applies the same syntax and data standards to tie it all together.
Here’s what that data mesh would look like conceptually:

3 key differences
The key differences between a data mesh vs data lake can be summarized this way:
- In a data lake architecture, the data team owns all pipelines, while in a data mesh architecture, domain owners manage their own pipelines directly.
- A data mesh architecture facilitates self-service data usage whereas a data lake architecture does not.
- A data mesh requires stricter data standards, including alignment on formatting, metadata fields, discoverability, and governance.
Now, let’s take a look at each in a bit more detail.
Is a data mesh better than a data lake?
In the great debate of data mesh vs data lake, it’s important to understand the differences in methodology before we can understand which approach might be right for our data teams.
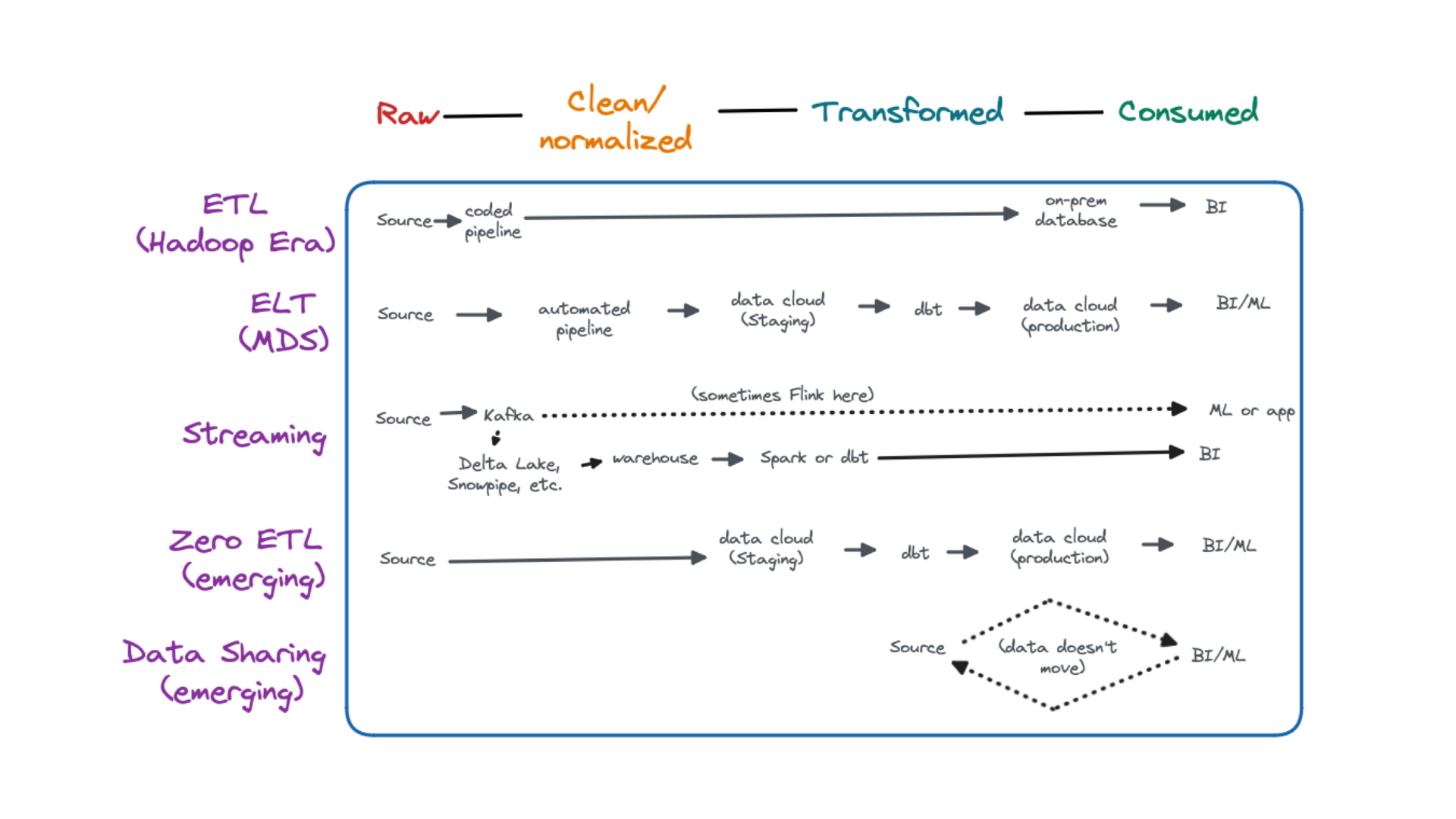
Up until recently, most companies hadn’t even adopted a data lake, much less a data mesh. Instead, companies leveraged a single data warehouse to power their data motion. That one solution would be connected to a myriad of BI tools based on the organization’s needs. While necessary at the time, this architectural philosophy also created significant technical debt—placing undue strain on the small group of specialists tasked with building and maintaining it.
That’s where the data lake came in. The data lake began winning ground thanks to its ability to offer real-time data and stream processing without increasing the burden on data teams. With a data lake, data could be ingested, enriched, transformed, and served up from a centralized platform with relatively limited tech debt for the solution itself.
But today, even the data lake approach has begun to fall short for some data teams. While a central ETL pipeline can certainly reduce technical debt, it also gives teams less control as data volume scales. And as distributed data adoption grows across modern organizations, the increase in use-cases is also increasing the strain on centralized platforms—and the data teams responsible for them.
Data mesh may just offer a solution.
While the idea of a data mesh might seem contradictory to a data lake at first, it can actually offer the best of both worlds. Domain-oriented data architecture relies on a centralized database like a distributed data lake as the engine of the data platform—but it relies on individual domains (or business areas) to manage the pipelines. This approach allows teams to limit tech debt, while at the same time promoting an agile data motion for distributed data-forward companies.
Unlike a single data lake with a centralized ETL pipeline, a data mesh promotes autonomy because it facilitates experimentation without increasing strain on the data team as those needs scale.
But just because the data mesh is innovative doesn’t mean it’s the right approach for every organization. So, how do you know if a data mesh is right for your platform architecture? Let’s take a look at a few of the differences between a data mesh vs data lake.
Pipelines and data owners
Who owns the data has historically been a pretty simple question to answer—particularly as it pertains to a data lake. When unstructured data is aggregated into a data lake, it’s up to the data engineers with the requisite SQL experience to build and manage those ETL pipelines. Pretty straightforward, right? But while this is no doubt a simple way to answer the question of data ownership, is it the best way to answer it? Cue the data mesh vs data lake debate.
Unlike a centralized data lake, a data mesh federates data ownership across each domain. These domain data owners are responsible for managing their data as its own product, facilitating the communication of distributed data across locations as needed.
In the example of a data mesh, the data team becomes responsible for managing the infrastructure as opposed to the data itself, empowering domain leaders with accessible self-serve tooling to manage ingestion, cleaning, and aggregation of their domain’s respective data purview to generate assets for business intelligence applications and data products.
Once a dataset has been productized by a given domain, domain owners can leverage that data for everything from analytics to operational needs.
Data consumption (self-service)
To be self-service or not to be self-service—that really is the question we have to answer when we’re considering a data mesh vs data lake.
Where a data lake relies on the data team to operationalize and deliver data to functional teams, a data mesh allows users to abstract away the technical complexity and focus on leveraging data for their individual use cases.
You could even go so far as to say self-service is the goal of a data mesh—facilitating fast, agile data products for downstream users. But if a data mesh were easy, every data team would already have one—and a data mesh certainly isn’t without its challenges.
One of the primary concerns of the data mesh vs data lake—and domain-oriented design in general—is the duplication of efforts to maintain pipelines and infrastructure by each functional domain. But the key lies in a domain-agnostic infrastructure. By utilizing accessible cloud-based tooling into a single central platform for pipelines, storage, and streaming, data teams can create a self-serve engine that’s maintained and protected by a single data team.
While the data team is responsible for the engine of consumption, each domain can be individually responsible for leveraging that engine for their own use-cases—offering the support to easily self-serve data as well as the autonomy to own the process of pipeline development without relying solely on the availability of an over-extended engineering team.
Collaboration and data standards
Like much of what we’ve discussed so far—data governance is relatively straightforward for the traditional data lake platform architecture, if not the most useful.
In the case of a data lake vs data mesh, governance and the sharing of data is managed through a single gatekeeper—the data team. Standards and responsibilities need not be shared across teams because all data needs are serviced and fulfilled by staff data engineers as needed.
But innovation requires sacrifice. And when it comes to governance, a data mesh requires a more tailored approach. It’s inevitable that some data (both raw sources and cleaned, transformed, and served data sets) will be valuable to more than one domain. To implement a successful data mesh, each domain must adhere to a universal set of data standards that can support effective collaboration between domains.
Among other things, a data mesh requires alignment across formatting, metadata fields, discoverability, and governance. And like microservices, each data domain will also need to agree on SLAs and quality practices to protect downstream consumers.
Data fabric vs data mesh vs data lake
Up until recently, the debate has been largely between data mesh vs data lake architectures (which is probably pretty obvious from the title), but you can always trust the great wide field of data to throw us a curveball.
Where a data lake represents the centralization of data management and data mesh represent its decentralization, data fabric falls somewhere in the middle by advocating for centralized data management but democratized access.
Much like a data mesh, a data fabric isn’t a standalone technology, but it does rely on a variety of specific technologies to be successful. Data fabric is a data management architecture that leverages an integrated data layer atop underlying data in order to empower business leaders with real-time analytics and data-driven insights.
The biggest benefit of a data fabric over a data mesh is its ability to handle large amounts of distributed unstructured data. For teams already leveraging a data lake, data fabric can be a great way to incorporate self service into your organization by acting as connective tissue across those touch points.
Don’t forget data observability
As exciting as a data mesh is for modern data teams, your data mesh vs data lake debate will mean nothing unless data quality is also a priority.
Autonomy and democratization will always introduce new risks to an organization—the same is true for your data platform. While data engineers may be able to manage some data quality motions in-house on a traditional data lake architecture, that idea goes right out the window with a data mesh.
No domain can truly own their data if they don’t own the quality of their data as well. A good data mesh mandates scalable, self-serve data observability that empowers domain owners to both trust and maintain the integrity of their data health autonomously.
The data mesh paradigm prescribes having a standardized, scalable, and accessible way for individual domains to answer the following questions:
- Is my data fresh?
- Is my data broken?
- How do I track schema changes?
- What are the upstream and downstream dependencies of my pipelines?
Data observability allows for compute-light, automated, and self-serve data quality monitoring for domain owners, making data reliability accessible for data users.
Should you implement a data mesh for your organization?
While implementing a data mesh vs data lake offers some very obvious—and attractive—benefits, it’s not without its challenges either. So, before you begin your data mesh journey, it’s important to consider whether a data mesh is right for your team.
A data mesh is best for distributed organizations where data is a key component of cross-functional operations. These organizations tend to leverage large volumes of data sources and require faster experimentation with that data as a key component of their business operations. Disconnected data producers, scaling data consumers, and backlogged data teams are all signs that a data mesh is worth exploring.
Check out our simple calculator below to see if investing in a data mesh could be right for your organization. Simply answer each question with a number, then add your answers together to get your total—or your data mesh score. The higher your score, the more likely your organization will be to benefit from a data mesh.
- Quantity of data sources. How many data sources does your company have?
- Size of your data team. How many data analysts, data engineers, and product managers (if any) do you have on your data team?
- Number of data domains. How many functional teams (marketing, sales, operations, etc.) rely on your data sources to drive decision making, how many products does your company have, and how many data-driven features are being built? Add the total.
- Data engineering bottlenecks. How frequently is the data engineering team a bottleneck to the implementation of new data products on a scale of 1 to 10, with 1 being “never” and 10 being “always” ?
- Data governance. How much of a priority is data governance for your organization on a scale of 1 to 10, with 1 being “I could care less” and 10 being “it keeps me up all night”?
Did you score above a 10? Your organization would probably benefit from implementing some data mesh best practices, but a full data mesh is probably still a bit further down the road. Did you score above a 30? Congratulations—your organization is maturing rapidly and you’re in the data mesh sweet spot.
Is your company in the data mesh vs data lake debate? Reach out to Barr Moses and Lior Gavish with your experiences, tips, and pain points. We’d love to hear from you! Or book a time to speak with us below.
Our promise: we will show you the product.
Read more posts.