Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Reverse ETL: The Missing Piece of the Data Quality Puzzle


Allie Dyer Bluemel
Allie is the Director of Developer Marketing at Census.
When you want to make sound data-driven decisions, it’s critical to have seamless access to fresh and accurate data. However, ensuring data accuracy is no easy task. After all, we’re dealing with thousands of disparate data sources, transformations, reports, and more.
Over the last several years, data engineering teams have been responsible for managing these processes, implementing tightened workflows and better integrations, and championing an industry-wide shift towards treating data like production-grade software and not a siloed entity.
Although key players in the modern data stack have changed the way businesses collect, clean, process, transform, and leverage data and have made insights easily accessible to everyone, challenges remain.
The biggest hurdle? Data trust.
Data testing and data observability solutions have filled the gaps when it comes to monitoring, alerting for, fixing, and even preventing data quality issues in production systems, but data trust extends far beyond these steps of the pipeline.
Far less discussed by equally important to data trust is data access.
While DataOps processes have brought a continuous loop of flexibility, repeatability, and speed to building data pipelines, they can’t address lags between data requests and data delivery. If your data isn’t on time, can it be trusted?
This is where reverse ETL comes in.
Reverse ETL tools eliminate wait times by pushing fresh, real-time data and insights into the apps you use every day. Here’s how.
What is reverse ETL?
Reverse ETL is an operational analytics tool that allows DataOps teams to transform and transfer data from warehouses into their favorite apps and services, flipping the role of traditional ETL tools.
Here’s how the team at Census defines reverse ETL:
Reverse ETL syncs data from a system of records like a warehouse to a system of actions like CRM, MAP, and other SaaS apps to operationalize data.
Reverse ETL helps teams overcome data silos inherent in centralized data warehouses, making real-time, high-quality data available whenever it’s needed. This approach allows data teams to have a tangible impact on business operations and the bottom line.
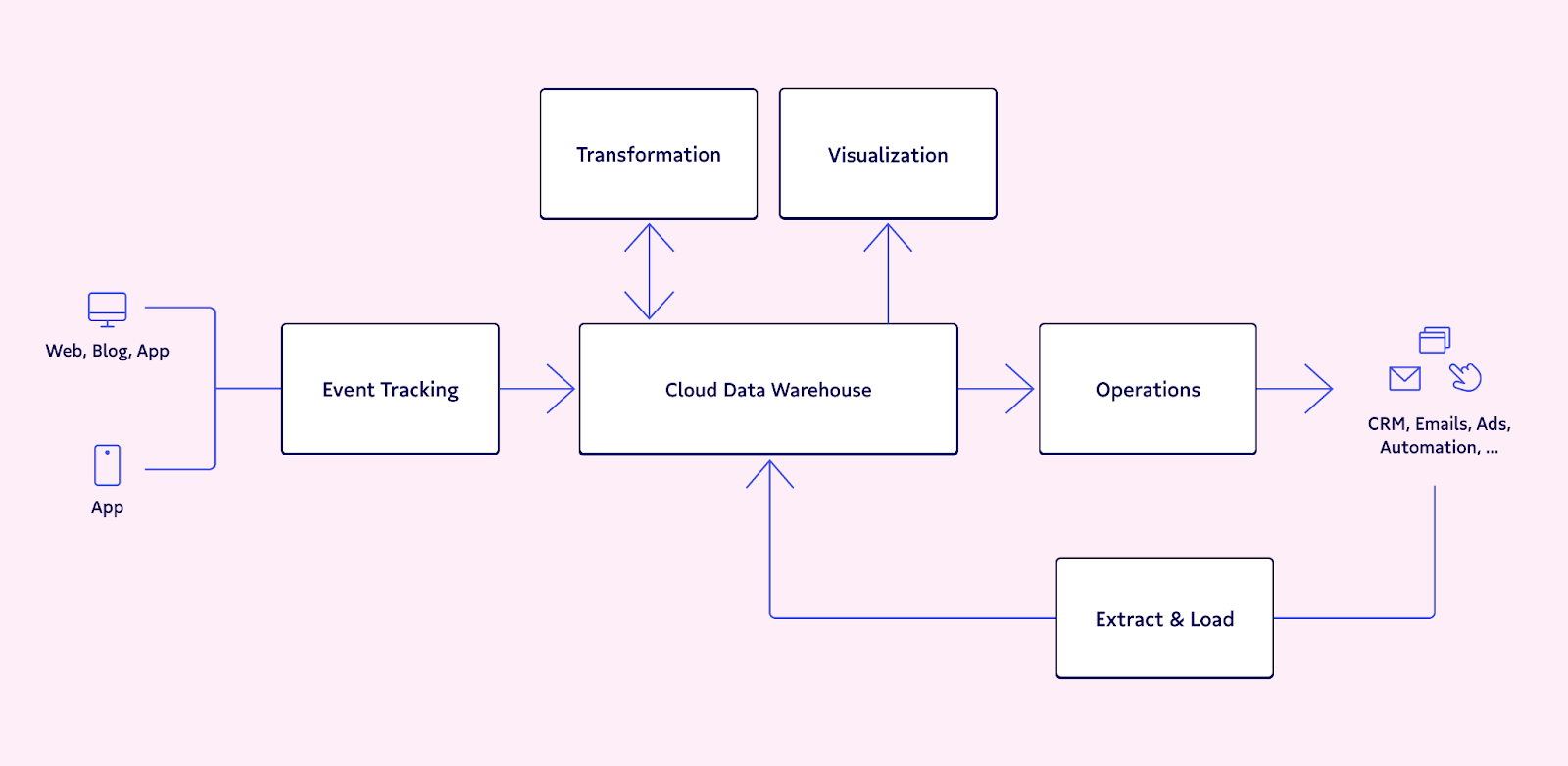
Reverse ETL is important as there’s a functional difference between data warehouses and operational systems. When we operationalize analytics, a traditional ETL tool will pull raw data from different apps. A data modeling tool will clean, process, and transform the data in a warehouse, and a reverse ETL tool will send it back to those same apps (essentially putting the data back to where it came from) for quick access.
With reverse ETL tools, like Census, and data observability platforms like Monte Carlo, data teams can rely on fresh, (almost) real-time data to drive better decision-making.
Reverse ETL makes it possible for data teams to achieve true DataOps principles and treat their data as a product. Namely, this new tooling capability allows data teams to apply software product development principles–such as testing, versioning, monitoring, and continuous delivery–beyond just dashboards and into every tool data consumers rely on.
Why data teams should use reverse ETL
The modern data stack includes data integration tools (like Fivetran or Snowplow), data storage (or warehouses like Amazon Redshift, Google BigQuery, or Snowflake), data modeling (with a pre-configured library of data models to make your data usable in various scenarios), data observability, data discovery, and data operationalization (to pull data out of warehouses and into apps like HubSpot or Salesforce).
For example, reverse ETL tools address the operationalization component by moving data out of the warehouse to where it’s most needed – in Salesforce, HubSpot, or any other application used by the business to make decisions. By doing so, they can easily automate workflows, improve the quality of fresh and accurate data, and, most importantly, accelerate access to data and insights.
Codifying analytics protocols
When data teams add reverse ETL to their data stack, they can seamlessly access, process, integrate, model, and visualize their data. Together, these tools generate code and configurations that ensure that the right actions are always taken to deliver valuable insights. This approach also helps business, operations, and analytics teams work better together daily.
Enabling value working analytics
Reverse ETL ensures that data teams consistently work with accurate data on top of predefined frameworks and systems. This approach enables insightful analytics that helps boost performance and much more.
Quality, performance, and real-time monitoring
When your pipelines are codified and automated, detecting and resolving abnormalities and vulnerabilities is much easier. If there’s technical debt or security issues in the data, code, or configurations, you’ll be alerted to it immediately. When you monitor security, quality, and performance in real time, you can also continuously detect potentially unforeseen variations and deliver operational statistics.
This approach helps teams make the most of the modern data stack, breaking down data silos and pushing accurate data directly to where it’s actionable. For example, reverse ETL populates BI tools and apps with precise and detailed information to empower teams to be more productive and effective on a daily basis.
Reverse ETL also helps data teams align applications around a single source of truth. This approach ensures that downstream stakeholders across departments can formulate a better understanding of business operations.
To deliver improved data quality and strengthen data trust, reverse ETL tools boast the following features:
- Sync alerting is important and should never be limited to failures. They should also include error messages, invalid or rejected records, and anything else that demands immediate action to fix the issue before it derails the whole operation. For example, alerts should be quickly available via email and Slack.
- Detailed logging helps to reference and understand which records failed to sync between the warehouse and the destination quickly. They also highlight successfully synced records to ensure accuracy and boost your confidence in the data you’re working with.
- Integration with data observability tools is a must. Your reverse ETL tool must let you integrate with your favorite data observability tools without much effort. It should ensure that those systems parse logs, whether through a native integration or through other levers like webhooks.
- Usage audit logs allow teams to track reverse ETL usage from the user level. This helps you understand exactly who made what changes to any particular data model or sync configurations. It will also log any potential changes made by your vendor support teams.
- Sync rollbacks allow you to leverage the reverse ETL tool to quickly roll back syncs to an early data state. This will come in handy whenever syncs fail to make remediation of errors.
Reverse ETL makes everything it does transparent, letting you know exactly what it’s doing, what data it’s accessing, and where it’s pushing that data to. This commitment to visibility and trust is the heart of operational analytics, allowing business users to make the right decision with accurate real-time insights.
If you’re thinking of adding a reverse ETL to your data stack, make sure to choose one that perfectly fits your use case. You should consider the following before making a decision:
- Data connector quality (connector breadth and depth)
- Visibility into sync performance (alerting, detailed logging, integration with your favorite monitoring tools, usage audit logs, and sync rollbacks)
- Security and regulatory compliance (because your data should not just be correct, it should also be safe)
- Sync robustness (sync reliability or Just Works™, automated sync scheduling, incremental syncs, triggering sync scheduling, data validation, and sync speed)
With reverse ETL in tow, just about everyone from business to data teams can work on exciting analytics projects without spending all their time and energy building countless custom solutions, and in the process, achieve (some semblance) of data trust.
Sounds neat, right?
Ready to give Reverse ETL a test drive? Feel free to reach out directly to me, or sign up for a demo with Census today.
Book a time to speak with Monte Carlo in the form below.
Our promise: we will show you the product.
Read more posts.