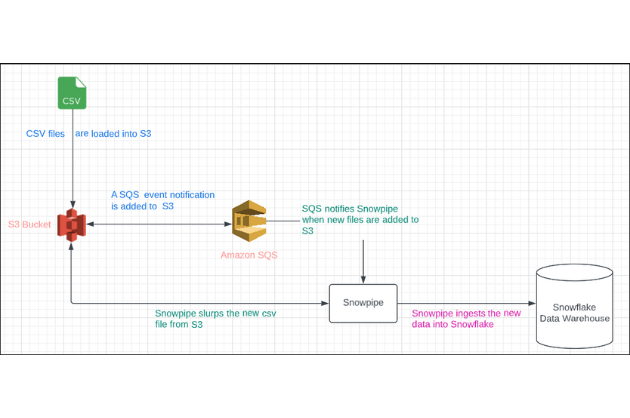
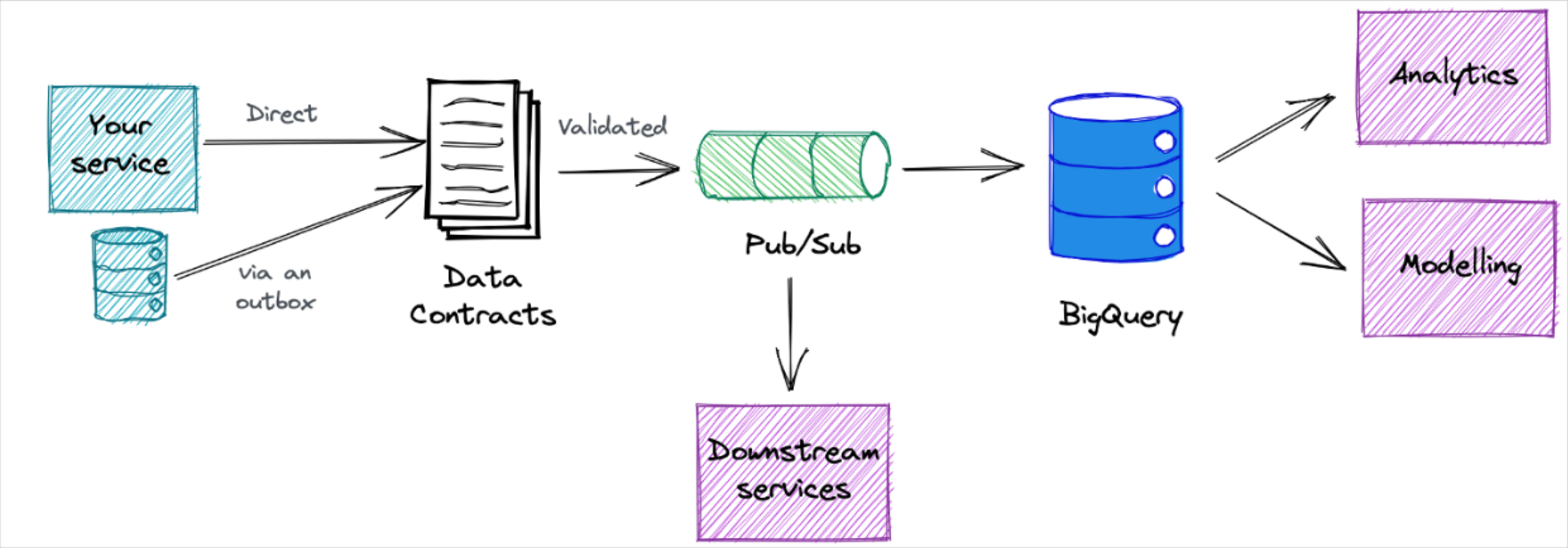
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 5 Predictions for the Future of the Data Platform


Sara Gates
Sara is a content strategist and writer at Monte Carlo.
The field of data engineering has been growing at a breakneck pace. New frameworks, new challenges, and new technologies are constantly shifting how engineers think about their work and their roles within their organizations.
Keeping up with the latest developments can feel like a full-time job—so we’re always grateful when seasoned leaders share their perspectives on which trends in data engineering actually matter.
That’s why we were excited to have Maxime Beauchemin present at IMPACT: The Data Observability Summit last October. Maxime’s experience speaks for itself: He’s the creator of the popular orchestrator Apache Airflow, followed by Apache Superset, as well as CEO and co-founder of Preset, a fast-growing data exploration tool offering AI-enabled data visualization for modern companies. Plus, he was one of the first data engineers at Facebook and Airbnb.
And at IMPACT, Maxime shared his key predictions for the future of data engineering. Watch his entire talk here, or read on for five key takeaways about the post-modern data stack.
1) Data integration will become easier (and more efficient) than ever before
In the not-too-distant past, data engineers faced a big challenge in centralizing data. Taking all the data that flowed in from the dozens—if not hundreds—of SaaS products a company uses and piping it into a warehouse, where it could be managed and queried, took a lot of time and energy.
But with the rise of tools such as Segment, Fivetran, Meltano, and Airbyte, it’s become relatively easy for teams to bring all of their data from external sources into a centralized place like a data warehouse.
Now, according to Maxime, a new trend is emerging that could have a similar effect on data engineering workloads: reverse ETL.
Reverse ETL tooling enables companies to easily move transformed data from their cloud warehouse out into operational business tools, like a CRM. This new approach empowers business users to access and act on their data, while reinforcing the data warehouse as the source of truth.
As Maxime describes it, “This means that something that used to take a lot of energy and time, and was very error-prone, is now a solved problem.”
2) Open-source will increasingly infiltrate the data stack
While open source isn’t a new trend, it’s definitely an accelerating one. According to Maxime, this is because of two key developments: the “inside-out” adoption of open-source tech and venture capital investment.
First, open-source is becoming more prevalent throughout the modern tech stack, as it’s continually layered within other software products. “If software was eating the world, now open-source is clearly eating software,” Maxime says. “Much of the modern data stack was born open-source, and for the things that aren’t necessarily open-source by themselves, open-source is eating it from the inside. A bigger portion of the software that is deployed today is made out of open-source components and libraries.”
And while the open-source movement dates back decades, Maxime holds that the newfound interest from venture capital is accelerating its development. “With the success of companies like Databricks, Confluent, and Elastic, we’ve proven that the model works very well, and then we see an influx of venture capital.”
3) Data roles will become more specialized as data literacy rises
As more organizations recognize data’s value in driving important business decisions and invest more heavily in data, more employees are learning to interact with and leverage data. Overall, data literacy is on the rise—and new specializations are starting to emerge.
Compared to software engineering, Maxime says, “I think the on-ramp for people to become more sophisticated with data is just easier and more accessible to more people.”
And over the last five years, many data analysts have broadened their knowledge to include traditional engineering skills like Git and SQL. This has led to one emerging role that Maxime believes is here to stay: the analytics engineer.
“The analytics engineer is a subset of the skills that a data analyst and a data engineer would have, and creates a new persona who can have one foot on each side of the Venn diagram,” says Maxime. This new role can bridge the gap between the immediate business needs that analysts traditionally prioritize and the longer-term focus on infrastructure that engineers keep top-of-mind. “I think we should celebrate the rise of the analytics engineer, because it’s a role that’s here to stay.”
Along with analytics engineers, Maxime predicts specializations in areas like data integration, data orchestration, and data streaming will become the norm as teams and technology continue to evolve. And he points to the rapid rise of a new specialized framework: data operations and data observability.
Modeled after the principles of DevOps, data operations and data observability applies principles of software application observability and reliability to data. Monitoring, alerting, and incident management help teams prevent data downtime and ensure the end-to-end health of their data pipelines and products.
4) The [BI] semantic layer will erode
Historically, organizations have stored a semantic layer—a business abstraction that describes and defines how data should be used—within their BI tools. This information helps consumers self-serve and easily use their data. But when organizations have multiple BI tools, as many do, re-implementing the semantic layer across platforms can become cumbersome.
So Maxime predicts that more organizations will do away with the BI-specific semantics altogether, in favor of containing this metadata within the transform layer.
“There’s an incentive to move semantics, business rules, and nomenclature into the transform layer of the data stack,” says Maxime. “Then, it can be used across tools, it can maintain source control, and it can be managed in the same location and place where transformations are defined.”
5) Data governance will move towards decentralization
When data literacy rises and access to data becomes more readily available, the need for data governance rises as well—without adding bottlenecks. Maxime points to the decentralization of data governance as a possible solution.
“As organizations grow and are investing in data across the board, and as every team is becoming a data team over time, there’s a push to also decentralize data governance,” Maxime says.
While there are parallels to how software engineers have faced similar challenges (and resolved them with solutions such as microservices), decentralization in the data world is a bit more complex.
“It’s more of a challenge in the data world because data has such a strong gravitational pull to it—data wants to be together,” says Maxime. “It’s hard to say who owns any combination of metrics and dimensions. It’s an area where we’ve seen a lot of challenges being expressed, and we’ve seen some emerging ideas around how to that best. And we’re going to see some progress in this area over the next few years.”
Bottom line: the future of data engineering is bright
Maxime acknowledges that everything he’s predicting is in high flux and far from settled. He continues to share his takes on the Preset blog, and is excited to see what happens in the years to come.
“There’s a lot of opportunity for all of us to go and build this future!” Maxime says.
Want to learn more about how forward-thinking data leaders like Maxime are staying ahead of the curve? RSVP for this year’s IMPACT: The Data Observability Summit, featuring data leaders like Nate Silver (founder of FiveThirtyEight), Daniel Kahneman (Nobel Prize-winning economist), Zhamak Dehghani (creator of the Data Mesh), and Tristan Handy (creator of dbt).
Read more posts.