 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 4 Snowflake Data Replication Best Practices That Will Save You Time and Money

Michael Segner
Michael writes about data engineering, data quality, and data teams.
In the age of cloud computing, data is moved from production environments like AWS RDS, Google Cloud SQL, and Azure databases into analytical warehouses, machine learning clusters, and storage systems like S3 to perform various tasks. Although data replication is essential to making data-driven decisions, companies seldom invest time and strategy in making the data replication process efficient.
This blog post will shed light on some of my favorite tricks that you can use today to make your replication strategy as efficient and inexpensive as possible. Including:
- 1. Place micro batches of files into your cloud storage bucket when replicating data for streaming
- 2. Pay attention to data type guidelines
- 3. Have a disaster recovery plan
- 4. Consider data observability solutions to catch issues quickly
Let’s dive in.
1. Place micro batches of files into your cloud storage bucket when replicating data for streaming
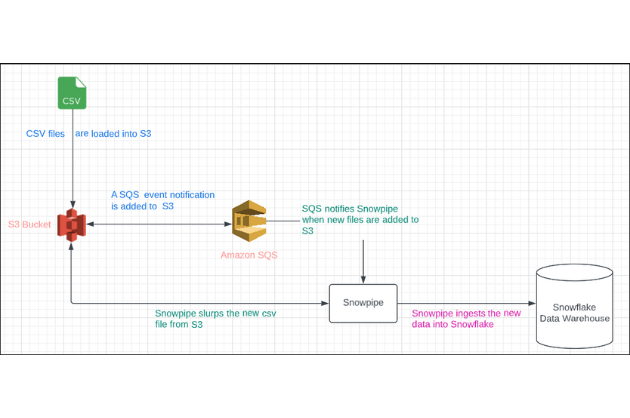
One of the most common methods to ingest data into Snowflake is via an external stage connected to a cloud storage bucket corresponding with your cloud host. The streaming architecture looks like the following (S3 used as an example):
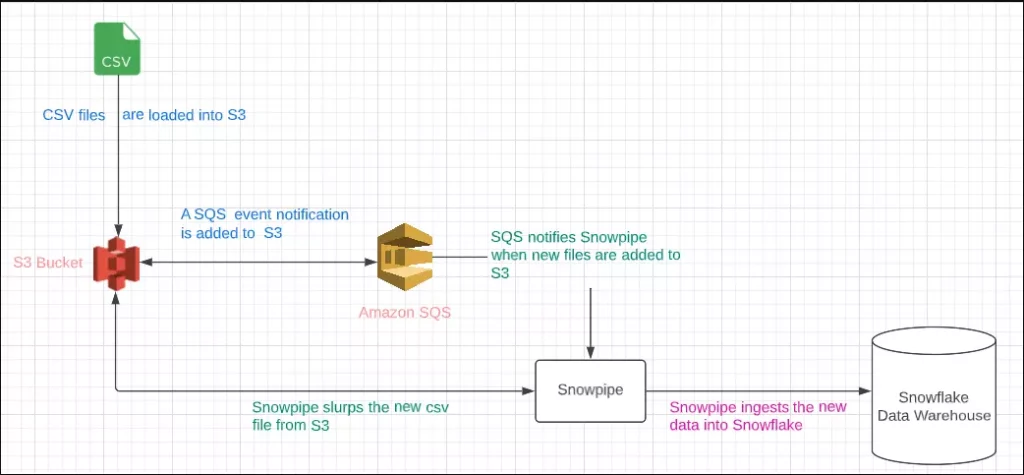
In this architecture, Snowpipe fetches CSV, JSON, Parquet, or any other file placed in the S3 bucket every 60 seconds as long as the file format is accepted by Snowflake compute engine. Unfortunately, many developers dump enormous CSV files into S3 buckets. This slows down the file processing time significantly; clogs the queue; and increases cost and latency.
Snowflake recommends placing micro batches of files, with each file sized between 100 to 250 MB. This optimal file size helps with parallel processing, reduces resource consumption, and avoids overhead.
2. Pay attention to data type guidelines
Data types vary drastically from system to system, and therefore they are a vital consideration when data is replicated. One wrong data type can stop the entire data replication procedure and cause issues downstream with using the data, such as the inability to use mathematical functions on text data types. Pay attention to default encoding standards; avoid embedded characters on number or float data types; and define default precision scales when needed.
Follow international date and timestamp standards. When building your data replication pipeline, promote subtypes into a parent type when possible for casting in the data warehouse, and make sure to align with analytics stakeholders to ensure that you’re properly typecasting.
3. Have a disaster recovery plan
In the event of a data replication error, such as when merging updated data into existing datasets, have a back up plan in place to revert your data so that operations can continue unimpeded while repairing the data replication process. Cloud data warehouses and data lakehouses will typically have features that support reverting data when this occurs.
For example, Snowflake has Time Travel, Databricks has Delta time Travel, and BigQuery also has a Time Travel feature. All of these solutions have their own windows for how long snapshots of data will be retained in these systems, which gives your teams time to revert to the last known steady state of your data, before pushing your changes into production.
In the event that you’re not using one of those tools or haven’t set up the features on your account yet, consider using the established method of setting up periodic snapshots of your data for this DR situation as well. These can be anywhere from monthly to daily dependent on how often your dataset is updated, and the criticality of the data.
4. Consider data observability solutions to catch issues quickly
No data engineer wants to be chatting with Snowflake support, no matter how lovely they may be. It usually means something has gone horribly awry. At this point, you are breaking out in a cold sweat wondering if you will regain access to this critical data or if you should start polishing your resume.
Data observability, the process of using machine learning to quickly identify and resolve data anomalies across the modern data stack, can dramatically reduce the chances of this scenario playing out.
These solutions monitor and alert across four main-types of anomalies:
- Freshness of data – How up-to-date is your data?
- Distribution – Is your data within an acceptable range?
- Volume – Are all your tables complete?
- Schema – Were there any changes made to the foundational organization of your data?
For situations where you are replicating data into Snowflake, or another data warehouse/lake/lakehouse, data observability can reduce your time to detection to near real-time–which of course is well within your Time Travel window.
Let’s use some of the scenarios mentioned above to illustrate how data observability can help with data replication. For example, if you had a large dump of CSV files clogging the queue, a data freshness alert may trigger to alert your team that a batch of data was abnormally delayed.
If the wrong data type was used creating the replication to completely fail between the production and analytical databases, freshness and schema alerts would trigger. Monte Carlo’s data incident resolution features such as data lineage, query change detection, and anomalous row distribution could help pinpoint the exact issue to make for an accelerated recovery process.
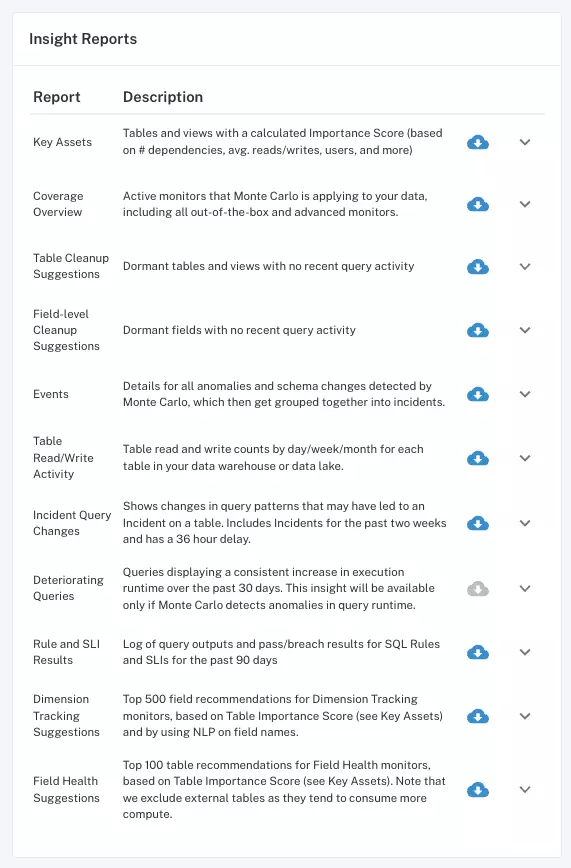
Data Insights from Monte Carlo can help determine if you have deteriorating queries.
Finally, while data observability monitoring can help detect abnormal changes in the way your data behaves, these alerts might not trigger if you have always had poor data replication processes in place. This is where features like Data Insights can help surface items like heavy or deteriorating queries that can surface these types of issues.
Interested in learning more about how data observability can help with your data replication processes and overall data quality? Schedule time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.





