 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Seasoned Optimized the Data Incident Management Process to Improve Data Quality at Scale

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Senior ops engineer Sean McAfee can recall one of the incidents that served as a catalyst for standardizing the data triage and incident management strategy for the data team at Seasoned, a job board and hiring app specifically designed for the service industry.
An alert had triggered indicating there was a massive jump in event types. He made some internal inquiries to see if the behavior was expected, and moved on to other pressing tasks. Days later a subsequent alert fired indicating a table had emptied itself, ultimately leading to the issue being revisited and fixed.
It turns out a failure to complete a recovery process for a routine event had broken a data pipeline in two different places. Even though the issue had been detected, gaps in the triage process and alert notification workflow had impeded a speedy resolution.
Table of Contents
Systemic challenges to effective data triaging
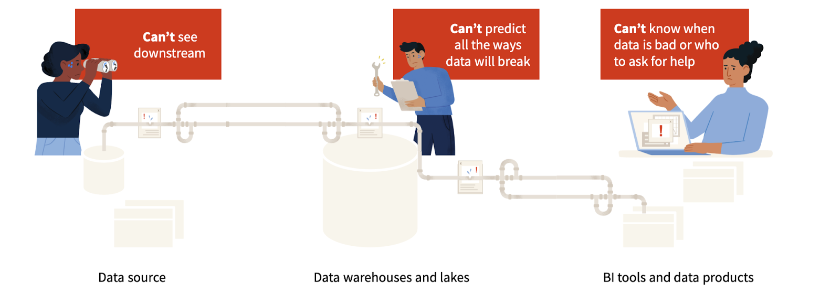
These challenges are extremely common across data organizations and result from the speed and scale of modern data operations. Different teams own different components of the infrastructure. This rarely includes data sources, which are generally under the purview of IT or third parties.
Engineers will often know the shape and model of the underlying data, but analysts are frequently the ones that best understand the larger semantic context and how it is being used by the business. All of this can create collaboration siloes while diffusing responsibility.
Sean decided this wouldn’t be the case at Seasoned and leaned into his extensive experience in business process improvement and tech operations to create a better system for managing incidents.
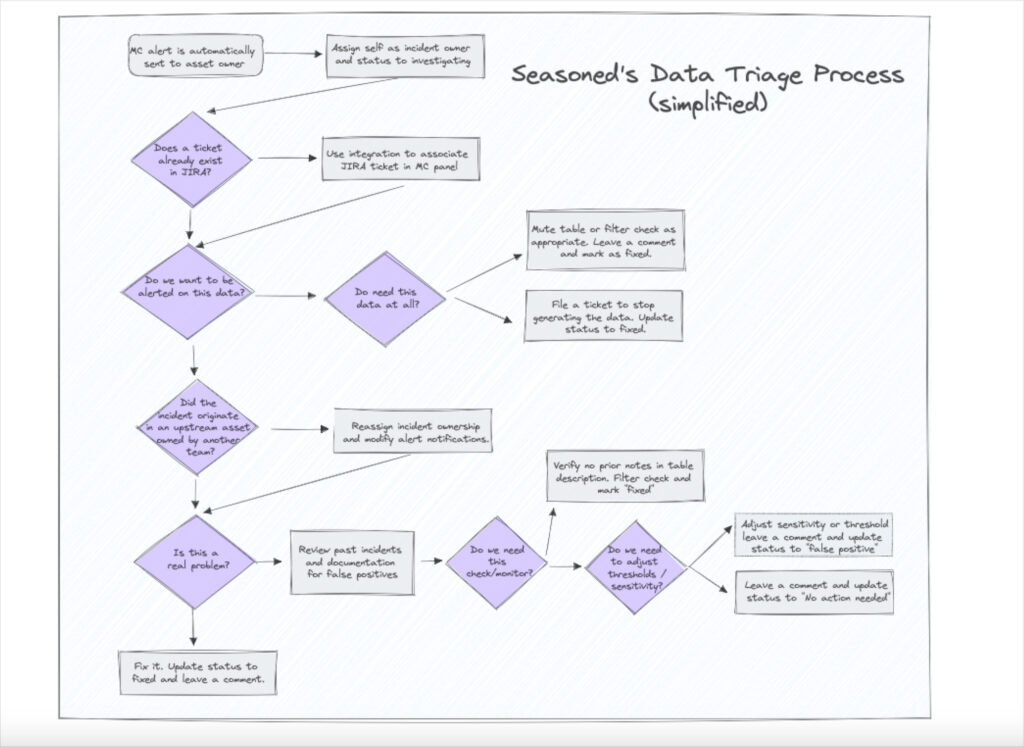
Here are the four principles and best practices that underpin it.
1. Clear and distributed data asset (table) ownership
Sean decided to decentralize incident management and response to remove bottlenecks and scale more effectively. While this has advantages, it can make it harder to determine who is on the hook for each incident.
Creating clear lines of ownership may sound simple, but it requires:
- Understanding system and table dependencies from the initial raw layer all the way downstream to how the data is being used.
- Selecting owners with the strongest data quality incentives for a particular dataset.
- Alerting owners only to the incidents under their purview.
- Implementing mechanisms to create visibility into and accountability for how owners handle and resolve those incidents.
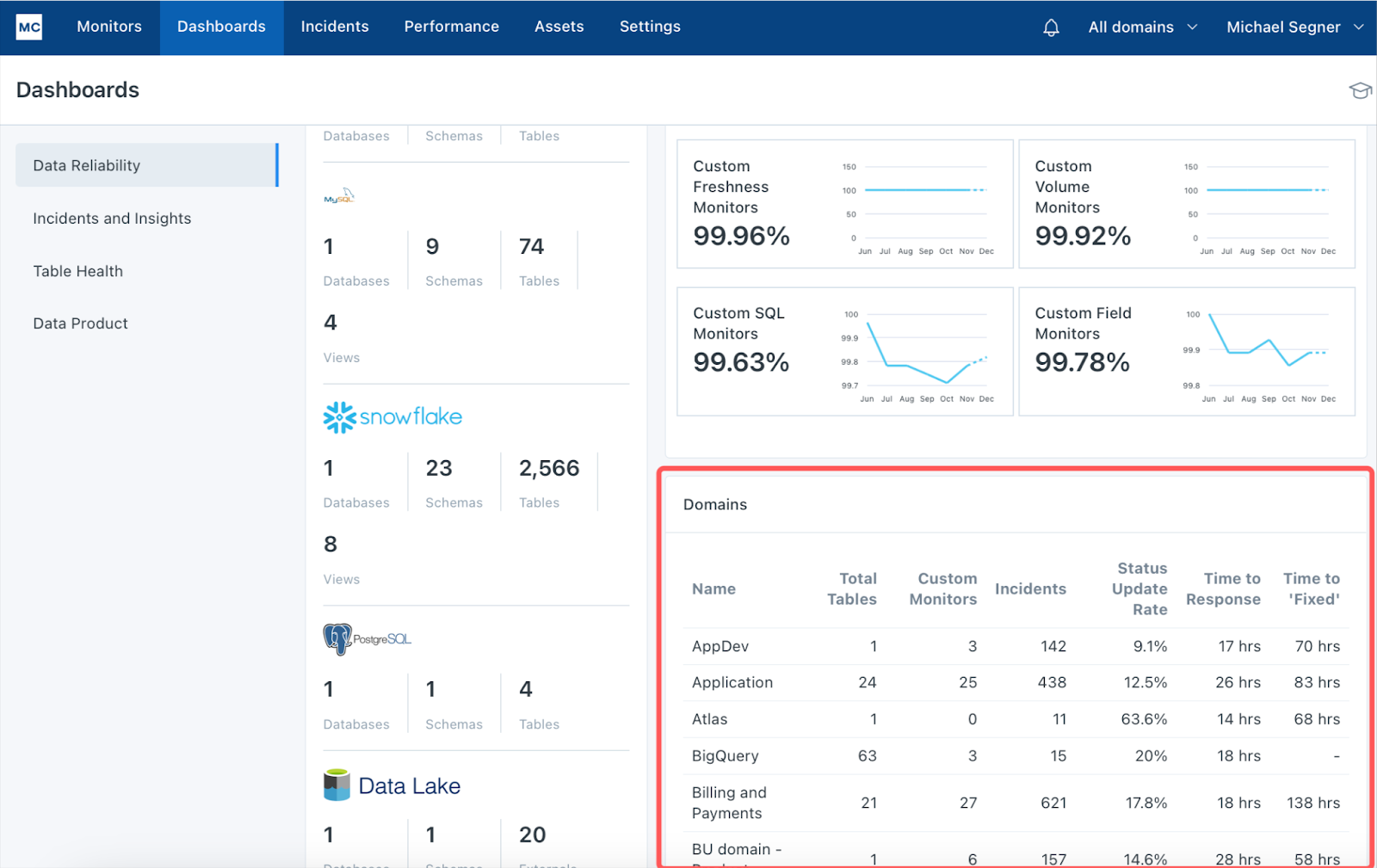
Sean chose to divide ownership based on domain, which ensures end-to-end coverage across data products. Whereas previously he had relied on a Notion document to track how each Monte Carlo custom monitor was tagged with each audience or communication channel, Notifications 2.0 has streamlined the process of ensuring the right alert gets to the right owner.
“Before Notifications 2.0 you had to know how different teams wanted to be alerted and tagging structures could get complex,” said Sean. “Now it’s a much easier process to create an Audience and have those users evolve how and to what they want to be alerted on over time.”
Monte Carlo’s data lineage automatically visualizes dependencies and the asset page lists the owner so there is never any confusion. The Data Reliability Dashboard also helps Sean track time to response and fixed for each domain.
In this system, data analysts serve as the first responders. Part of that decision is related to the unique aspects of Seasoned’s data stack, but it’s also because Sean believes analysts are best equipped to answer the first key question, “is this expected?” They also are directly visible and responsible for errors in the reporting process.
Analysts are entrusted and equipped to handle the data triage and resolution process, but are also able to escalate to data engineering for particularly challenging incidents. This has an ancillary benefit of, “letting them stretch their legs” and build skills that can help in a transition to an engineering career.
2. Make data producers part of the data triage team
Understanding and documenting data asset ownership is not enough for Seasoned. Data quality can be negatively impacted from the minute it’s generated at the source. This could involve anything from a wonky application to a schema change that breaks a data pipeline downstream.
Sean recalls a specific incident where a US phone number had 28 digits. This kicked off an important conversation amongst the team that, “…we’re getting worn out by [these types of incidents]. We have to either change the destination schema or fix the validation.”
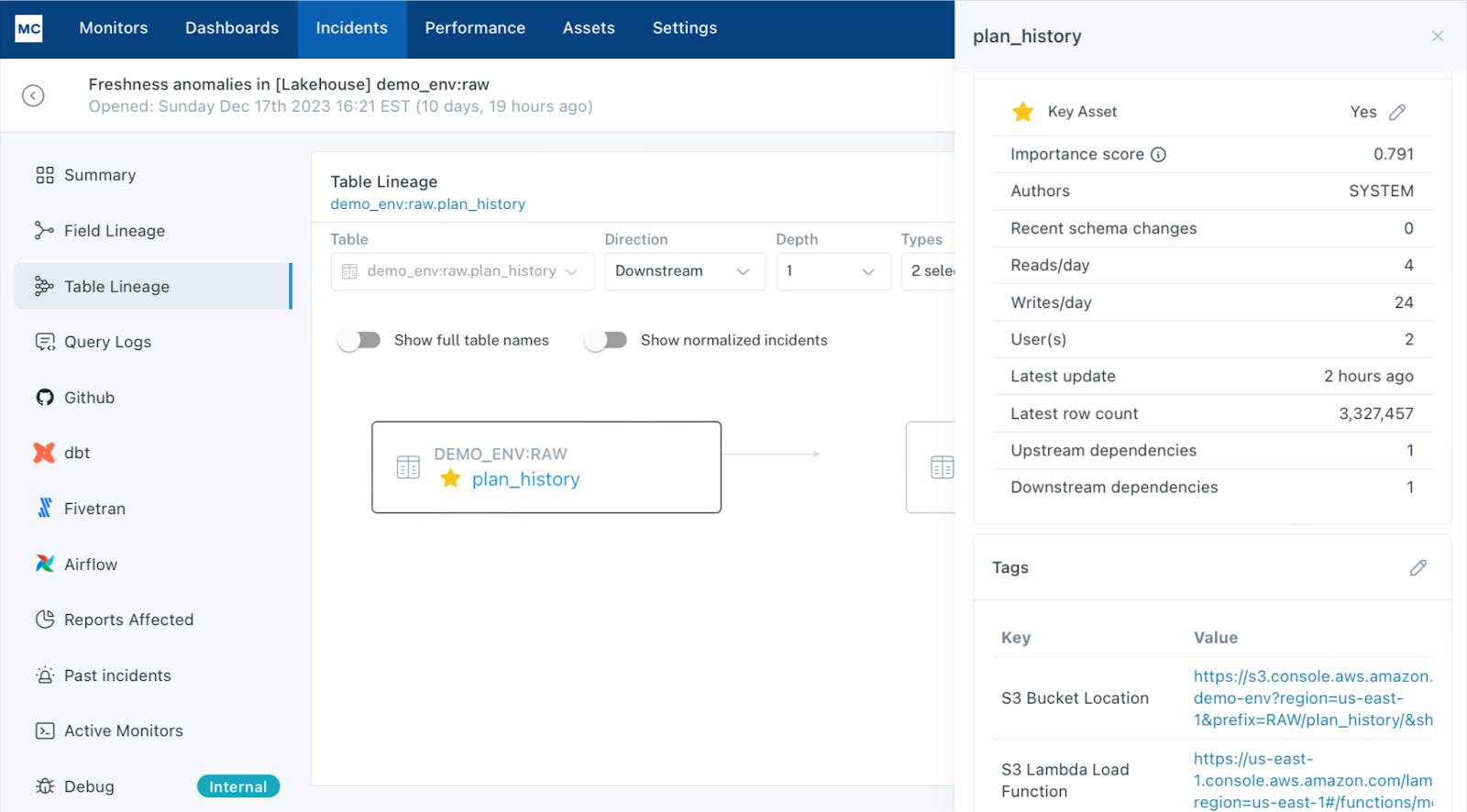
Seasoned’s data lineage and documentation notes the data sources and owners for each dataset and specific producers are added to relevant alert notification channels.
3. Be specific on ticket, status, and documentation expectations
A general data triage rule of thumb is that there are generally too many tickets, but never enough documentation for incidents.
Duplicate ticketing occurs when a multi-faceted data incident surfaces in different alerts in different systems handled by different teams. Each logs a ticket creating inefficiencies and unreliable operational metrics. To avoid this, Sean very clearly lays out when the responder needs to do their due diligence to see if there is a ticket in JIRA that should have new appended to it.
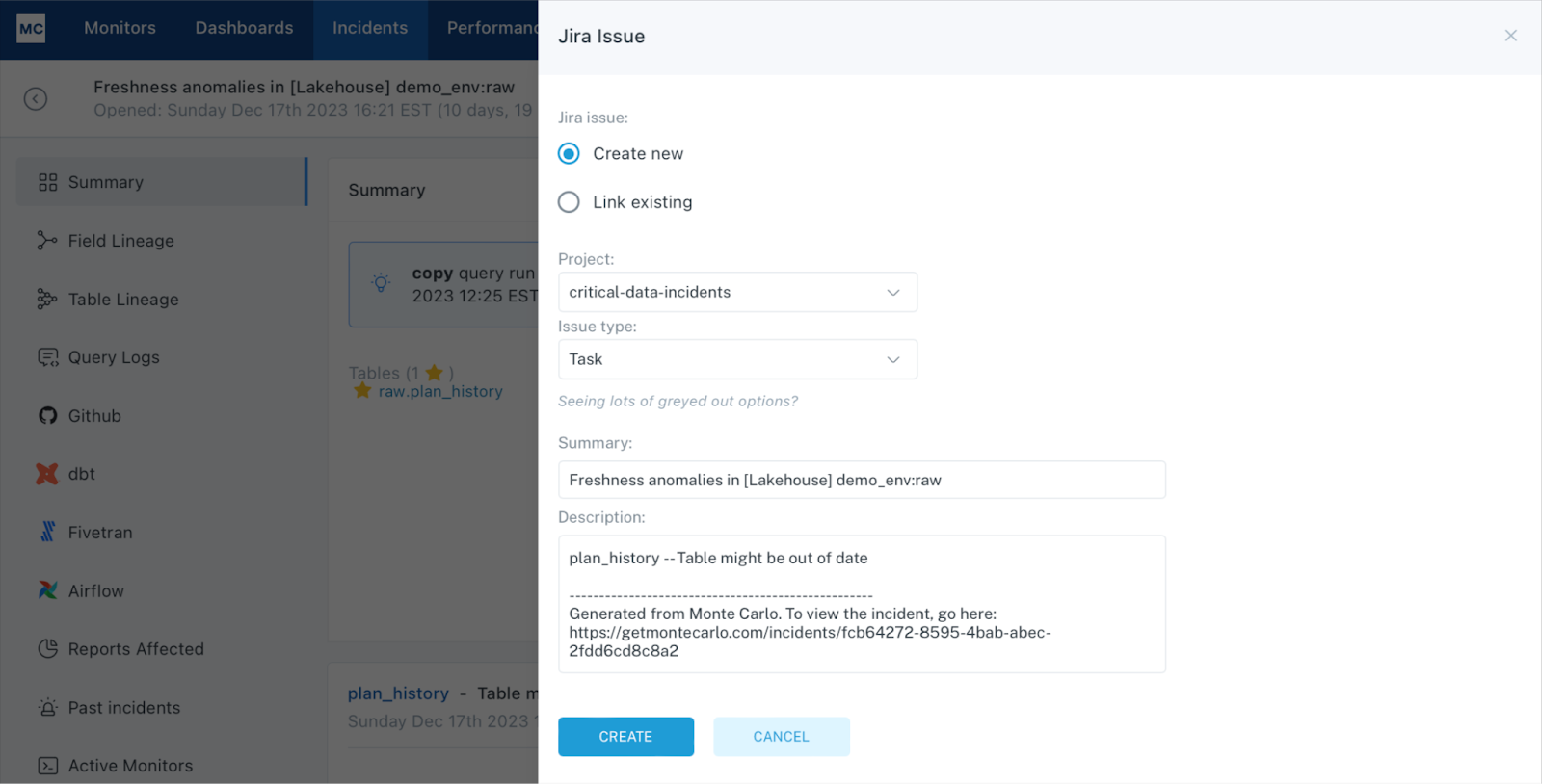
This is part of a decision tree and standard operating procedure that also details when and how incident status should change to “investigating,” “expected,” “fixed,” or other status. This helps the team ensure no incident falls through the cracks and all loose ends are tied off.
“We are aggressively ensuring that all incidents receive a disposition,” said Sean. “Today that involves setting Slack reminders to check the incident list, but in the near future it will be an active check leveraging the Monte Carlo API.”
Sean has also specifically identified when and where documentation should be reviewed or added within the Monte Carlo platform as an incident’s root cause is being investigated (in the table’s general information “description” section). Importantly, members of the Seasoned data team don’t just create documentation describing the incident, but also the context for the current status or any adjustments to the monitoring configuration.
4. Every alert is an opportunity to re-evaluate your data triage process
“Every single alert should force us to ask questions,” says Sean. “We want to cultivate a living-and-evolving data observability deployment that uses continuous improvement techniques to provide a consistent experience, improve notification accuracy, create distributed accountability, and increase engagement across each group within the data team.”
For example, when an alert is sent the responder has a list of questions to ask and subsequent actions to take such as:
- Is this monitor on this table helpful? If not, filter out the check.
- Do we care about the data within this table at all? If not, stop generating the data.
- Is this table helpful to have within lineage but doesn’t need monitoring? If so, mute the table.
- Did the incident come from an asset upstream owned by another team? If so, reassign ownership and modify alert routing as needed.
- Is this a false positive? Is there a history of false positives on this table? If so, adjust the thresholds.
“We see asking questions on every alert as an integral part of our data team’s culture,” said Sean. “For every incident, we are going to fix the problem or fix the alert.”
Putting it all together (in a chart)
One of the advantages of data observability compared to other data quality approaches like data testing is how easy and quick it is to set up.
Monitors automatically span across your environment as tables are added to your selected schemas and there is no need for manually set thresholds (although you can supplement with specific checks).
And while the overall time spent on data quality will drop, optimizing incident management often does require some thought and new operational muscles. That doesn’t mean it needs to be complicated.

In fact, Sean has visualized Seasoned’s process into a chart similar to the one above. “In a way, this is my entire career distilled into one chart,” he said.
To learn more about how Monte Carlo can help your team leverage data observability to optimize data incident management like Seasoned, chat with us.
Our promise: we will show you the product.
Read more posts.

![[VIDEO] How Yotpo Drives Data Observability with Monte Carlo](https://www.montecarlodata.com/wp-content/uploads/2021/01/Screen-Shot-2021-01-29-at-9.35.32-AM.png)


