Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is Data Observability – and Do You Need It?

Molly Vorwerck
Molly is Head of Content & Communications @ Monte Carlo.
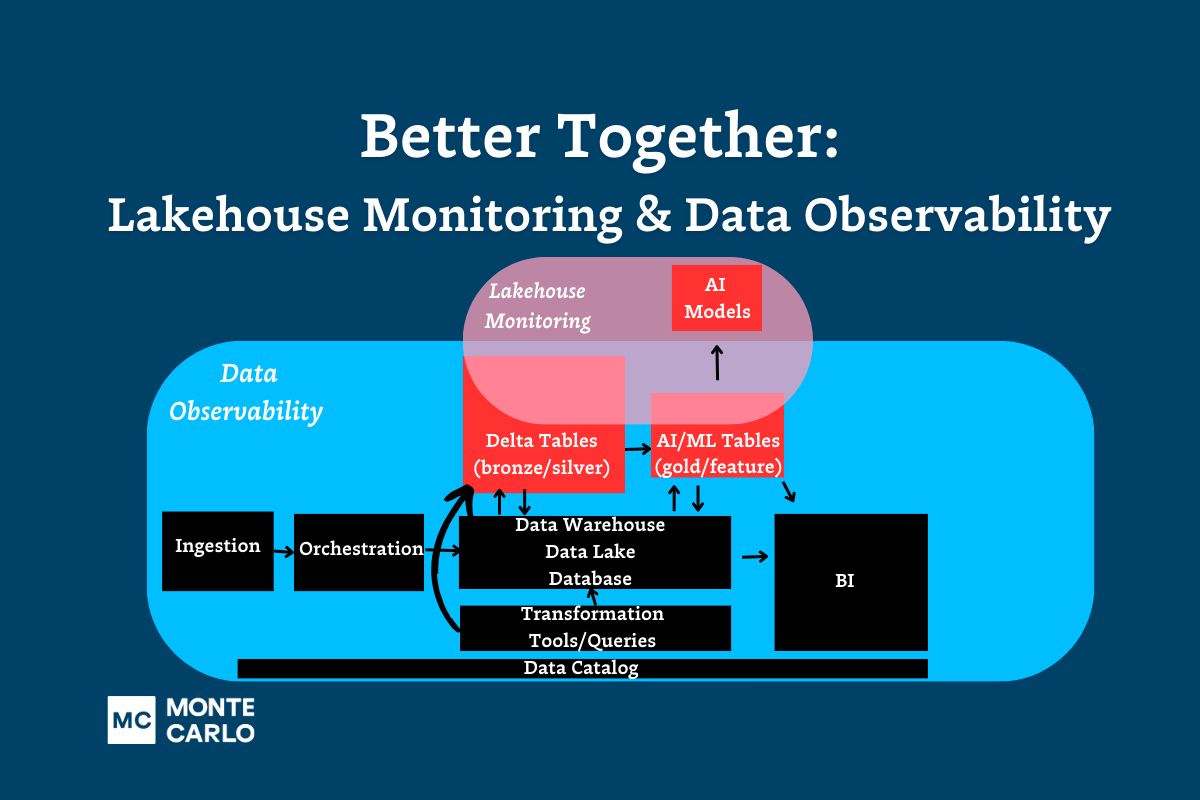
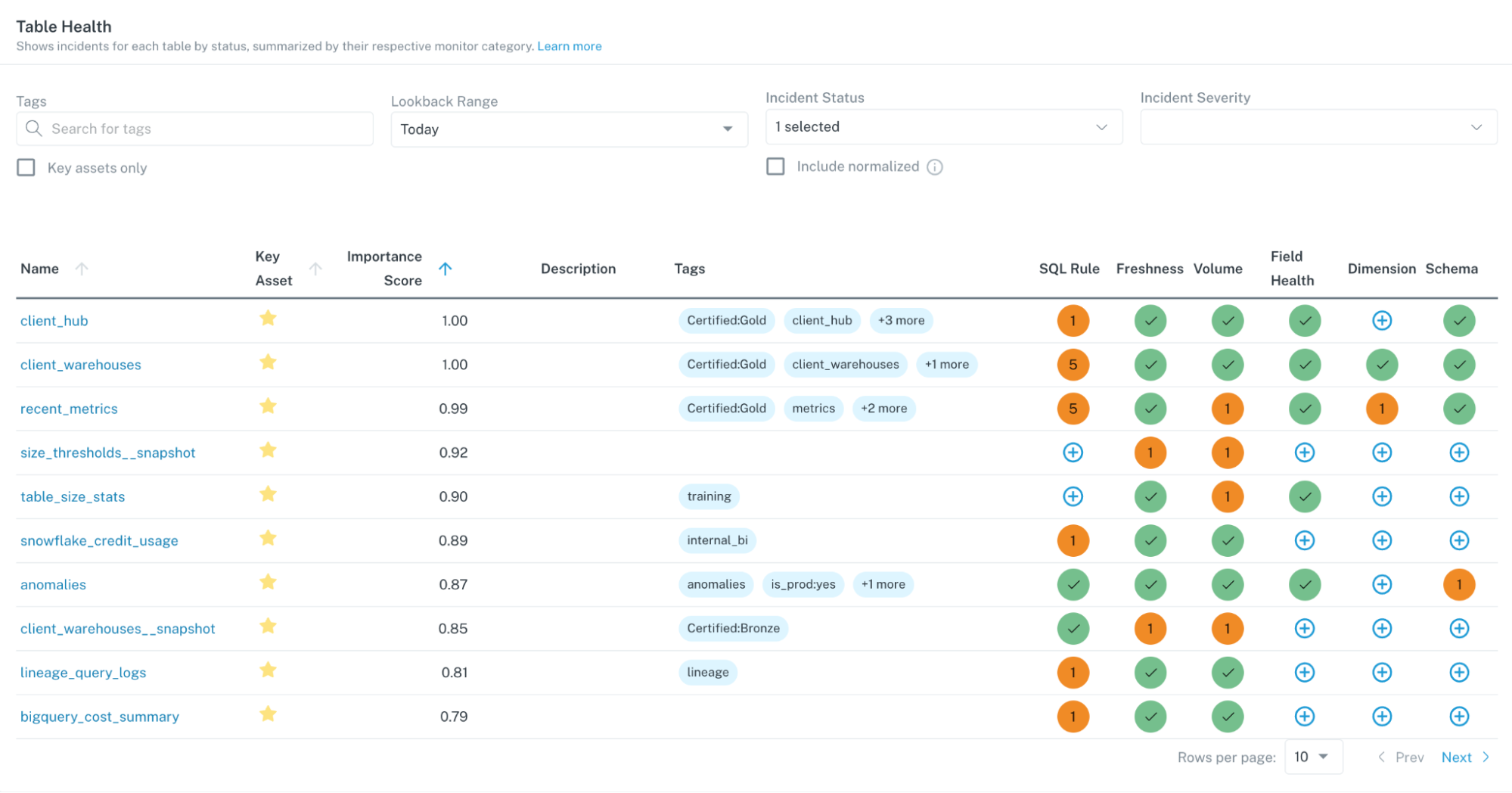
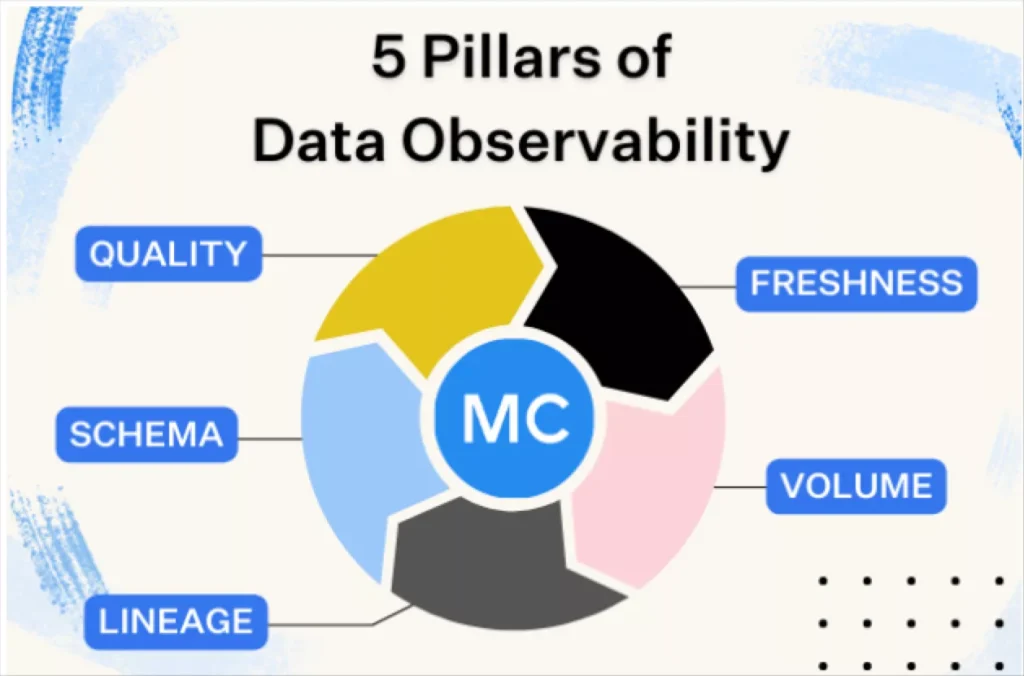
Emerging as a layer in the modern data stack just over a year ago, data observability refers to an organization’s ability to fully understand the health and reliability of the data in their system. Traditionally, data teams have relied on data testing alone to ensure that pipelines are resilient; in 2023, as companies ingest ever-increasing volumes of data and pipelines become more complex (LLMs, any one?), this approach is no longer sufficient.
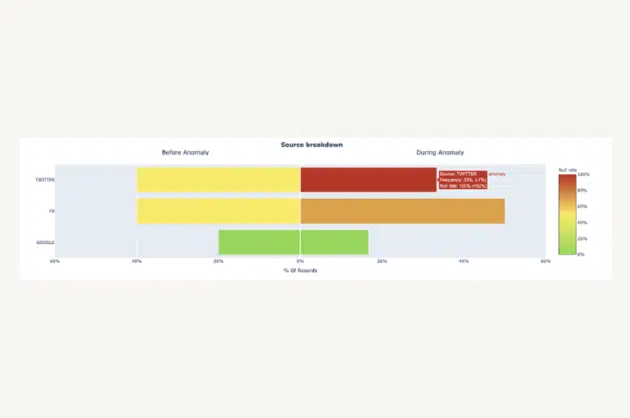
If you’re in data, dealing with broken pipelines, missing rows, and duplicate data (as well as the complications and frustrations that come with data downtime) is probably a familiar experience, even with testing.
Fortunately, new approaches have emerged over the past few years to supplement testing, most notable, automated data observability.
In this video, we highlight the TL;DR of data observability and discuss when it makes sense to implement this critical piece of software for your modern data stack.
Read more posts.