 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Fight for Controlled Freedom of the Data Warehouse


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
A silent alarm rings in my head whenever I hear someone utter the phrase, “data is everyone’s responsibility.”
You can just as easily translate this to mean that “data is no one’s responsibility,” too. This, readers, is what I call the “data tragedy of the commons.”
Here’s why.
The term tragedy of the commons comes from economic science and refers to situations where a common set of resources is accessed without any strong regulations or guardrails to curtail abuse.
As companies ingest more data and expand access to it, your beautifully curated warehouse (or lakehouse, we don’t need to discriminate) can slowly turn into a data swamp as a result of this unfortunate reality of human behavior.
To use another adage… having too many cooks in the kitchen spoils the broth. Having too many admins in the Looker instance leads to deletions, duplications, and a whole host of other issues.
So, how can we fix this data tragedy of the commons?
In my opinion, the answer is to give data consumers, and even members of the data team when appropriate, guardrails or “controlled freedom.” And in order to do this, teams should consider four key strategies.
Remove the gatekeeper but keep the gate
Don’t get me wrong: everyone should care about data quality, security, governance, and usability. And I believe, on a fundamental level, they do. But I also believe they have a different set of incentives.
So the documentation they are supposed to add, the catalog they need to update, the unit test they should code, the naming convention they should use–those things all go out the window. They aren’t being malicious, they just have a deadline.
Still, the tradeoff of faster data access is often a poorly maintained data ecosystem. We never, of course, want to disincentivize the use of data. Data democratization and literacy are important. But the consequences of sprawl are painful, even if not immediately felt.
All too often, data teams attempt to solve the “data democratization problem” by throwing technology at it. This rarely works. However, while technology can’t always prevent the diffusion of responsibility, it can help align incentives. And the end user or data consumer is most incentivized when they need access to the resource.
We don’t want to impede access or slow organizational velocity down with centralized IT ticket systems or human gatekeepers, but it’s reasonable to request they eat some vegetables before moving to dessert.
For example, data contracts add a little bit of friction early in the process by asking the data consumer to define what they need before any new data gets piped into the warehouse (sometimes in collaboration with the data producer).
Once this has been defined, the infrastructure and resources can be automatically provisioned as Andrew Jones with GoCardless has laid out in one of our previous articles. Convoy uses a similar process as their Head of Data Platform, Chad Sanderson, has detailed.
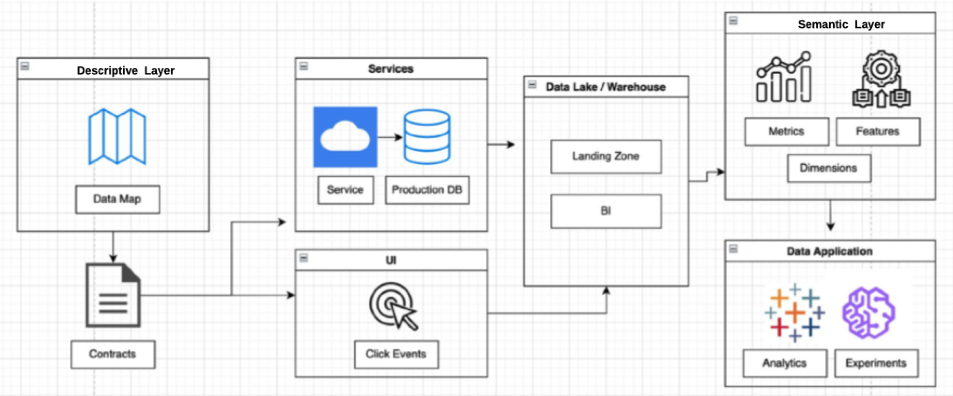
The next challenge for these data contract systems will be with change management and expiration. Once the data consumer already has the resources, what is the incentive to deprovision them when they are no longer needed?
Make it easy to do the right thing
The semantic layer, the component of the modern data stack that defines and locks down aggregated metrics, is another type of gate that makes it easier for people to do the right thing than to do the wrong thing.
For example, it’s likely easier for an analytics engineer to leverage a pre-built model in the dbt Semantic Layer as part of their workflow instead of having to (re)build a similar model that inevitably takes a slightly different perspective toward the same metric. The same thing is true for analysts and LookML. Making the most efficient path the correct path takes advantage of human nature rather than trying to fight it.
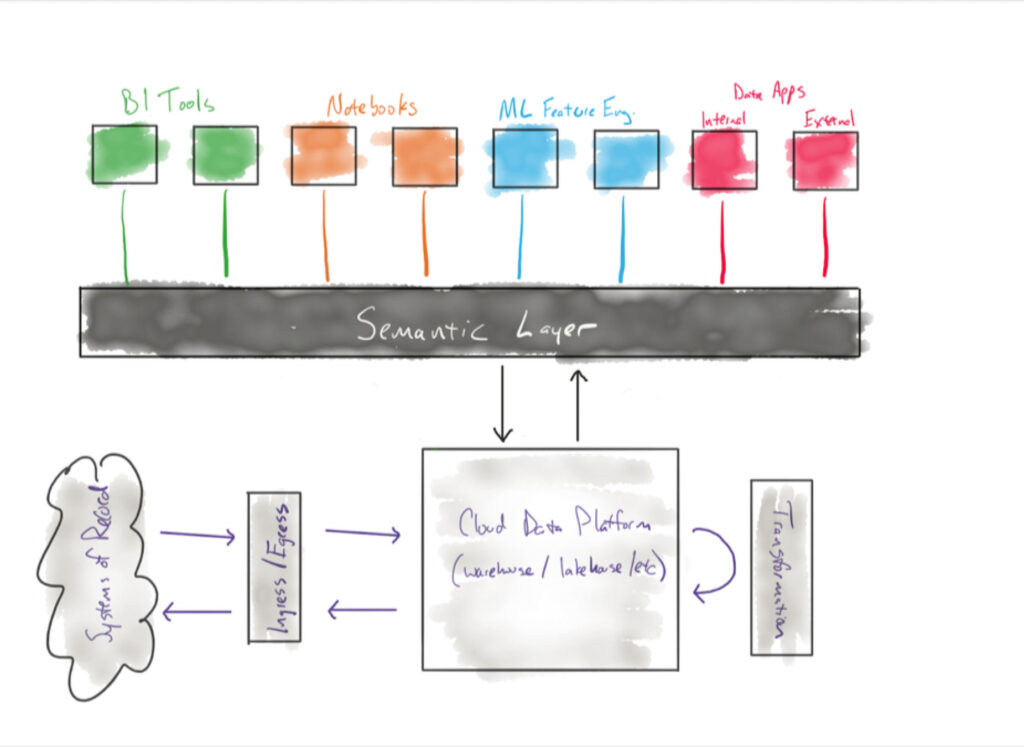
Another great way to do this? Integrating with established workflows.
Data catalogs, whose adoption challenges I’ve covered in the past, are classic examples of what happens when the responsibility to keep documentation up-to-date is spread thin across the team. Most of these solutions are just too far out of people’s daily workflows and require too much manual effort.
More modern data catalog solutions are wisely trying to integrate their use cases with DataOps workflows (which Forrester has recently pointed out) to better establish clear ownership and accountability.
To use a different example from the world of data, the human aversion to logging into yet another tool that marginally adds value to their task is one of the reasons reverse ETL solutions have been so wildly successful. Data moves from systems that intimidate users, such as marketers, to systems they are already leveraging like Marketo or Salesforce.
“Privatize” the commons
The most successful data governance programs I’ve come across have domain-driven processes with clear lines of ownership and manageable scopes.
For example, Clearcover Senior Data Engineering Manager Braun Reyes described how his organization has been successful deploying this type of strategy.
“We originally tried to make data governance more of a centralized function, but unfortunately this approach was not set up for success. We were unable to deliver value because each team within the wider data and analytics organization was responsible for different components and data assets with varying levels of complexity. A one-size-fits-all, centralized governance approach did not work and was not going to scale.
We have had much more momentum with a federated approach as detailed in the data mesh principles. Each data domain has a data steward that contributes to the data governance journey.
Now, the proper incentives are in place. It all boils down to ownership….Governance works best when each service that generates data is a domain with people who own the data and contract.”
Sometimes, just let the machine do it
Data quality has also traditionally suffered from the tragedy of the commons.
Data engineering leads will kick off their weekly meetings and talk about the importance of adding unit and end-to-end tests within all production pipelines until they are blue in the face. Everyone on the Zoom call nods and tells themselves they will rededicate themselves to this effort.
One of two things happen at this point. In most cases nothing happens for all the reasons we’ve iterated thus far.
But some teams create tight enough processes that they successfully create and maintain hundreds even thousands of tests. Which creates the problem of…creating and maintaining hundreds even thousands of tests. This consumes nearly half of your team’s engineering hours.
This is why the best solution to a tragedy of the commons problem, when it’s possible, is to automate the solution. Machine learning, for example, is better suited for catching data incidents at scale than human written tests (and of course they are best used in concert).
The key for any automation is to have it take action by default wherever possible rather than requiring a human to kickstart the process (and thus bring you back to your original challenge of inaction through the diffusion of responsibility).
Data commons can be beautiful…with guardrails
The modern data stack has enabled teams to move faster and provide more value than ever before.
As teams continue their path toward decentralization, self-service, and the removal of data gatekeepers, data leaders need to understand how the diffusion of responsibility may impact their team’s ability to execute.
Teams that align incentives, integrate with workflows, focus scope, automate, and operational ownership – in other words, achieve controlled freedom – will be much more successful than the teams that create bulky processes, rely on weekly admonishment, or succumb to the tragedy of the commons.
Interested in learning how to better tackle your data quality issues and the tragedy of the commons? Schedule a time to talk with us using the form below!
Our promise: we will show you the product.
Read more posts.





