Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Assurance Achieves Data Trust at Scale for Financial Services with Data Observability

Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
Assurance is a direct-to-consumer financial services platform striving to transform the insurance buying experience. The company leverages advanced data science to match buyers with custom solutions for life, health, and auto insurance. As such, data reliability is absolutely critical to its operations.
After it was acquired by Prudential Financial in 2019, Assurance continued to scale rapidly. Over the past four and a half years, the associated use of data has, in the words of Analytics Manager Mitchell Posluns, “exploded.”
Assurance uses data in several ways to empower various constituencies. The data team is focused on building an “ACE,” or Analytics Center of Excellence. The ACE comprises all types of data contributors, from analytics engineers to data engineers to business intelligence analysts, who collaborate to help the business make more strategic decisions using data.
As the company scales, various teams within Assurance—including data engineering, machine learning engineering, data science, business intelligence, and analytics engineering—leverage the platform to create new data assets. The sheer volume and variety of data necessitates new levels of oversight and visibility in order to optimize data management.
Assurance’s data engineering team focuses on data loading and platform infrastructure, with specialized sub teams. The overarching goal is to move toward a data mesh structure, where domain producers are responsible for their data. In this aspirational future, domain owners would be able to see all their data assets in one place, would use a self-serve platform to produce their assets, and would be mindful of consolidating and reducing the number of data assets they make available for others to consume.
Mitchell Posluns, an early member of the data team, has watched 40+ team members, all with their own needs and priorities, onboard to the data platform. Focused on data development workflows and the data consumer experience, ensuring data reliability was a priority for him and his broader team.
As a result, Mitchell and his team were often heads-down fielding requests from multiple stakeholders who depended on data to do their jobs as effectively as possible.
There had to be a better way to scale data trust across the business.
Initial challenge: Support regulatory requirements for data audits and increase data trust for analytics use cases
As a financial services and insurance company, Assurance is subject to multiple regulatory requirements. The company is required to demonstrate to auditors and regulators that it knows the origin and location of its data—and as Assurance scaled and its data usage exploded, this became increasingly difficult to do.
“The data platform grows and grows and grows, and not having visibility into it, not having lineage, not being able to set up monitors and alerts is a constant challenge,” says Mitchell. The company needed a lineage solution that could demonstrate each data asset’s journey through the data stack in an efficient, reliable manner.
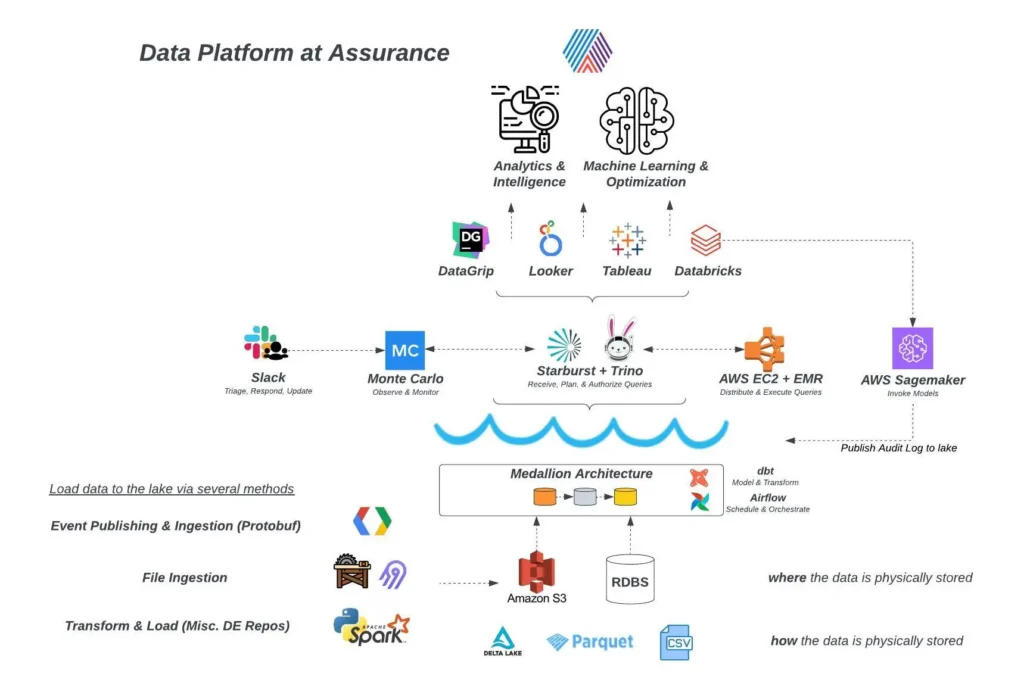
Doing this manually was a burden made more challenging by the data stack. Business data assets at Assurance are loaded into the company’s lakehouse architecture through various methods, then stored in several data stores.
The data team then uses tools like dbt and Airflow to refine, model and transform raw data into usable, query-able assets through Trino and Starburst. These tools connect with Assurance’s visualization tools, so business users can make sense of the data and put it to immediate use.
The data team struggled with a pervasive lack of visibility into data dependencies, which resulted in difficulties maintaining high quality data operations.
The team needed a tool that could ensure data’s reliability and enable comprehensive monitoring and visibility at every point in the data pipeline. Requirements for such a tool included:
1. Quick time to value
2. Speed and ease of deployment
3. Seamless integration with existing data stack
In June 2021, Senior Engineering Manager Shen Wang and his team partnered with Monte Carlo to help solve the multiple data and cultural challenges that accompanied the company’s hypergrowth.
The solution? Data observability.
Solution: End-to-end visibility into data quality with field-level lineage and automatic anomaly detection
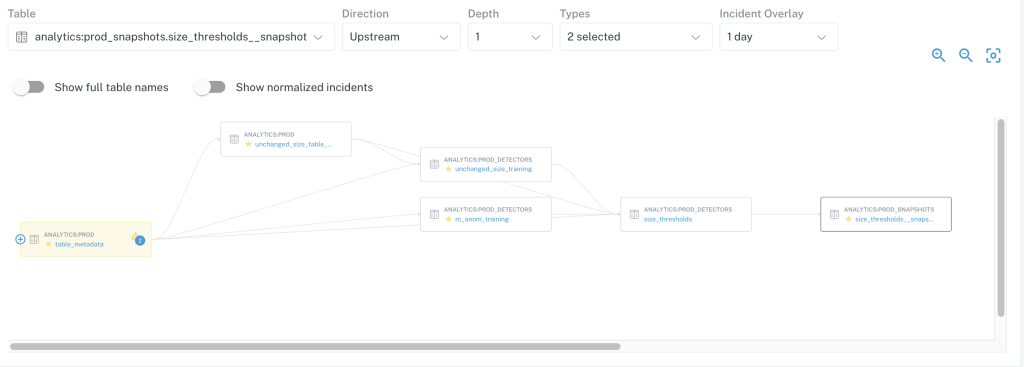
Right away, deploying Monte Carlo gave Assurance better understanding into the health of their data through automatic, field-level lineage.
“Monte Carlo’s lineage is my favorite feature, by far,” says Mitchell. “We benefited, I think immediately, from the lineage solution. It’s something that I use very, very frequently, almost daily.” The ability Monte Carlo provided to gain visibility over data with automated monitors and alerts was a game-changer for the data teams.
“Frankly, I can’t really imagine a world without it,” Analytics Engineer Rushika Verma says. “I can’t imagine going back to what things were like when you just didn’t have visibility into how data moves through the system.”
Monte Carlo offered immediate, out-of-the-box coverage for data freshness, volume, and schema. The Assurance team was quickly able to set custom data quality checks for distribution and field health on critical assets and manage alerts with triaging and root cause analysis. Monte Carlo integrates so seamlessly into Assurance’s tech stack that alerts are part of the daily fabric of corporate conversation.
“We are starting to integrate Monte Carlo into the actual communication flow, too,” explains Mitchell. Its integration with Slack enables multiple constituents on multiple teams to comment on, interact with, and view the history of alerts, which expedites root cause analysis. “That is all super critical for us in managing our data platform and really moving us along our data mesh strategy,” says Mitchell.
Monte Carlo also integrates easily with Trino and Starburst: core parts of Assurance’s data stack.
“In terms of it working with Monte Carlo, I’ve found it has been very, very solid,” says Mitchell. The Monte Carlo platform reads all query logs that go through Trino and Starburst, then can quickly build lineage graphs as a result. “In terms of the level of difficulty of integrating Monte Carlo across all these platforms, it’s been very easy,” says Mitchell.
Solution: Scaling more reliable ML with data and model monitoring for data scientists
Assurance doesn’t just use Monte Carlo to support regulatory requirements or quickly diagnose a data pipeline. The platform has introduced a host of other data-related possibilities.
For example, the company can now scale more reliable machine learning using Monte Carlo monitors. The Monte Carlo platform routinely and repeatedly learns how data assets are generated, monitors models and model features, and tracks SLAs for these features—all of which improve the quality and reliability of the machine learning data.
“We started shifting into using Monte Carlo for monitoring machine learning models—what kind of data they’re using as features in production,” explains Mitchell. “In any model that’s in production, all the predictions that are being generated are written into the data lake within partitioned files. These data files record every single prediction, the exact time it is made, what model endpoint it is, what features are being used, what is the state of the features at that exact point in time—this is analytical data you can use with Monte Carlo monitors just like any other data asset.” This allows the data scientists who own the model endpoints to ensure their models are performing as expected.
Using Monte Carlo expedites time to detection, which can yield material cost-savings. In one instance, the team used Monte Carlo to identify and fix issues derived from an introduced bug.
“Had this been implemented ahead of time, this would have seen savings in the 6-figure range,” says Mitchel. “There is real business impact in using this tool and embedding it into all of our operations and data mesh principles.”
Solution: Delivering data reliability for business analytics across functions
Deploying Monte Carlo helped rectify a persistent challenge for the Assurance data team: the deterioration of data trust across the business.
By establishing clear domains that align with the data team’s overarching goal of moving toward a data mesh architecture, providing granular visibility into data quality for critical assets, and clearly delineating what reports are impacted when things break, Monte Carlo has shifted Assurance’s culture from one of data skepticism to one of data trust.
According to Mitchell, the data scientists and business intelligence analysts interacting most frequently with key stakeholders have benefited most quickly and comprehensively from the Monte Carlo platform. When stakeholders ask data-related questions or spot data quality issues, these team members are now empowered to understand how a data asset was generated and learn its upstream dependencies.
Monte Carlo’s out-of-the-box and custom monitoring capabilities make data trust easy. Developers can now manage data quality and uphold a high degree of accountability for data assets produced by their domains. For example, the data engineering team recently deployed 30 new custom monitors, via code, to track data quality along a variety of dimensions. Those monitors help the data team maintain high levels of data quality while also managing internal team capacity and remaining realistic when communicating with internal and external stakeholders who rely on the data assets they produce. “It is the quality of these day-to-day operations that will take our Data Platform brand to new heights,” says Mitchell. “All of this helps Assurance operate as a more efficient business and be a preferred partner to work with in the industry.”
Outcome: Reduction in time to detection and resolution for data incidents; greater data trust
Since deploying Monte Carlo, Assurance’s data engineering team has gained greater visibility into its data, which has enabled compliance with important regulatory requirements. It has also reduced time to detection and resolution of data incidents—a critical step in building data trust.
For example, a data leader recently came to the data platform team with a query-related issue. While data platform engineers could identify part of the issue using the cluster monitoring tool provided by Assurance’s query engine, parsing through all of the query steps to find the issue in question was too high a burden to complete manually.
“At this point, we fired up Monte Carlo’s lineage and pipeline features and looked up the view in question,” says Mitchell. “Within just a few clicks, we saw all of the distinct nodes flowing into the view we were querying, and it became immediately apparent what the problem was.”
By using Monte Carlo, the team could quickly identify the problem and solve it in order to meet a time-sensitive business request. What’s more, Monte Carlo makes it easier to ensure similar problems don’t arise again in the future.
“Monte Carlo provides that extra layer of visibility that makes these changes much harder to slip through the cracks and persist,” says Mitchell. “Having this granularity enables our data platform and engineering teams to be realistic about the work that needs to be done and how/when it can be completed. We can better manage our capacity, roadmaps, and technical debt accordingly, which allows us to better plan migrations and proactively communicate clearly with our internal and external partners where we may be the dependency.”
What’s next for the data team?
Armed with a plan and process for ensuring reliable data, the Assurance data team has much excitement in its future. The team is ready to employ more integrated data observability with Looker and is preparing to move data reliability even further upstream with Monte Carlo’s GitHub integration. The team is planning to expand its monitoring and testing frameworks to improve its proactive approach to managing data quality at scale—and Monte Carlo is a key partner in that endeavor.
If you’re looking to add data observability to help your financial services company deliver faster, more trustworthy insights, reach out to the Monte Carlo team today!
Our promise: we will show you the product.
Read more posts.


![[VIDEO] How Resident Drives Data Observability with Monte Carlo](https://www.montecarlodata.com/wp-content/uploads/2021/03/Screen-Shot-2021-03-19-at-12.45.34-PM.png)