Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage [VIDEO] How Resident Drives Data Observability with Monte Carlo


Molly Vorwerck
Molly is Head of Content & Communications @ Monte Carlo.
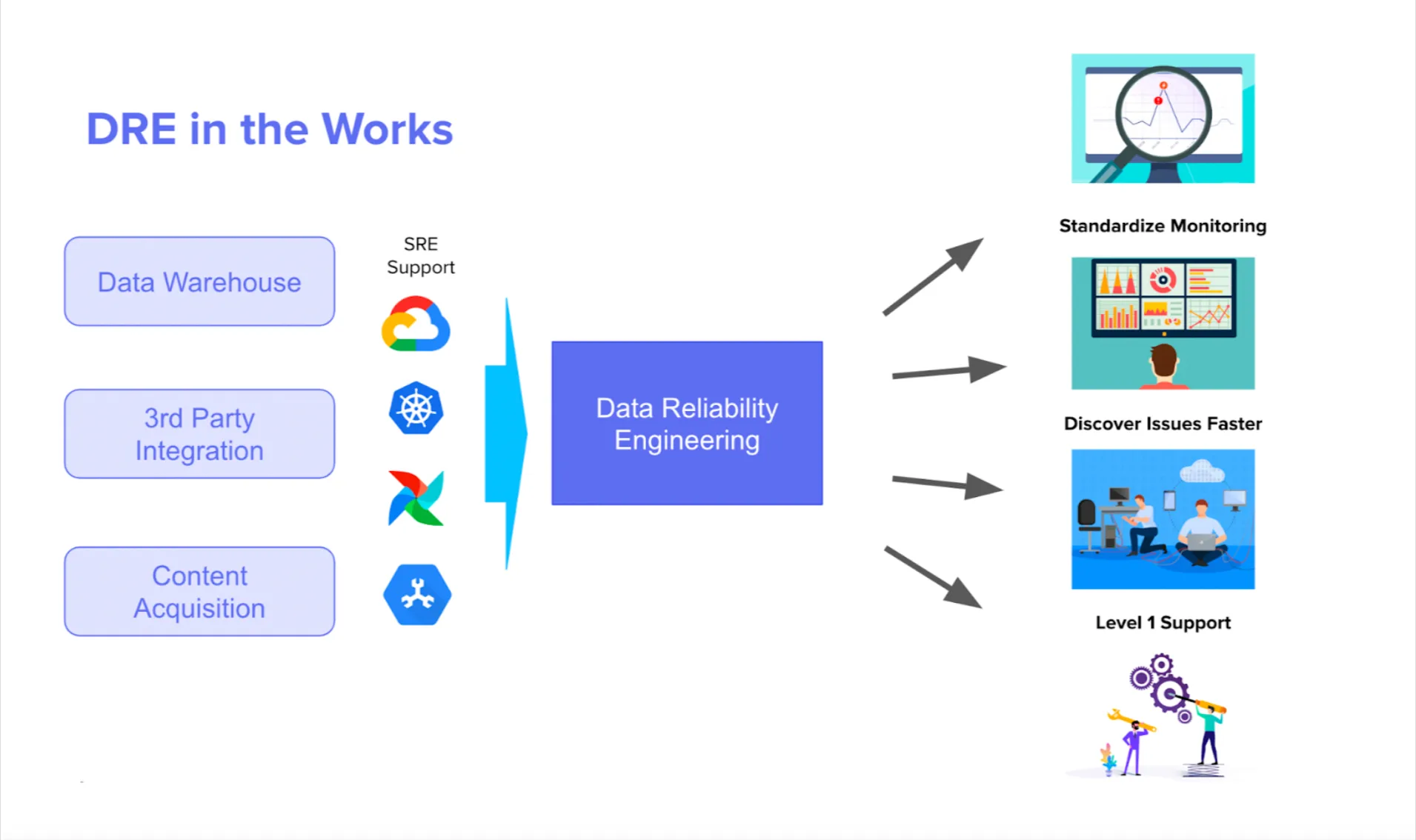
For Resident, a collection of premium direct-to-consumer brands, Data Observability has become a part of the Data Engineering team’s tech stack, helping them prevent broken data pipelines and achieve highly reliable data — at scale.
“I only use 3 tabs at work: Gmail, BigQuery, and Monte Carlo,” says Resident’s Head of Data Engineering, Daniel Rimon. “We never make a change to our data infrastructure without checking Monte Carlo first. That way, we can avoid data disasters before they even happen.”
In this webinar with Resident, you’ll to learn how modern data teams are using Monte Carlo and Data Observability to:
- Make changes to their data without causing downstream breakages
- Shorten time-to-detection when data issues arise
- Scale their data team and make collaboration easier
Curious about how Monte Carlo can help your team achieve trust in data?
Read more posts.