Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How PagerDuty Applies DevOps Best Practices to Achieve More Reliable Data at Scale


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
PagerDuty helps over 16,800 businesses across 90 countries hit their uptime SLAs through their digital operations management platform, powering on-call management, event intelligence, analytics, and incident response.
So how does PagerDuty approach data-specific incident management within their own organization? I recently sat down with Manu Raj, Senior Director of Data Platform and Analytics (aptly named the DataDuty team), to learn more about his team’s strategy for preventing “data downtime” and achieving more reliable data pipelines at scale.
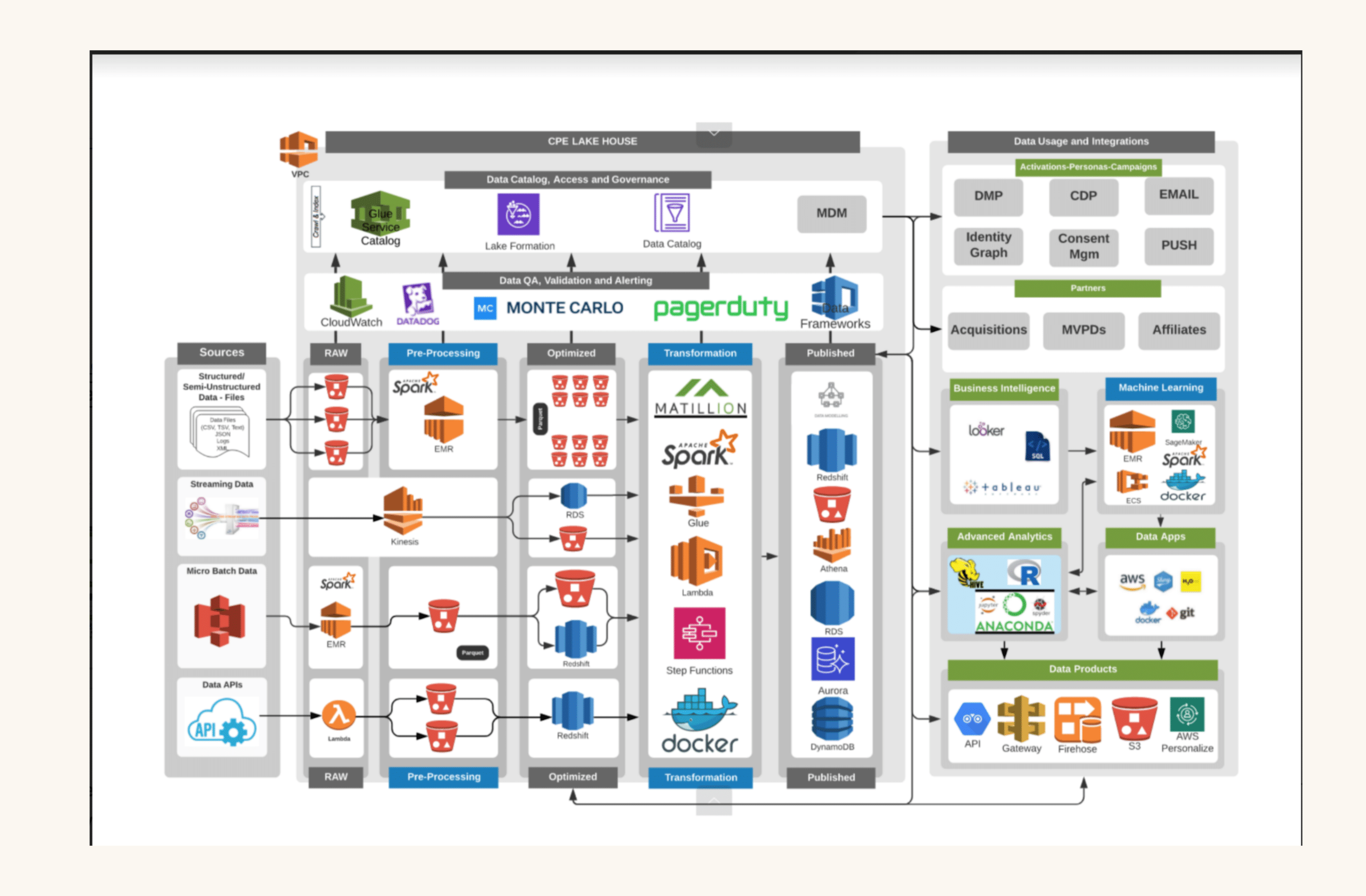
The data landscape at PagerDuty
PagerDuty’s Business data platform team has a clear mandate: to provide its customers with trusted data anytime, anywhere, that is easy to understand and enables efficient decision-making.
“The most critical part of that is data governance, data quality, security, and infrastructure operations,” said Manu. The team’s customers include “pretty much all the departments in PagerDuty, including finance, executives, customer success, engineering, sales, and marketing.”
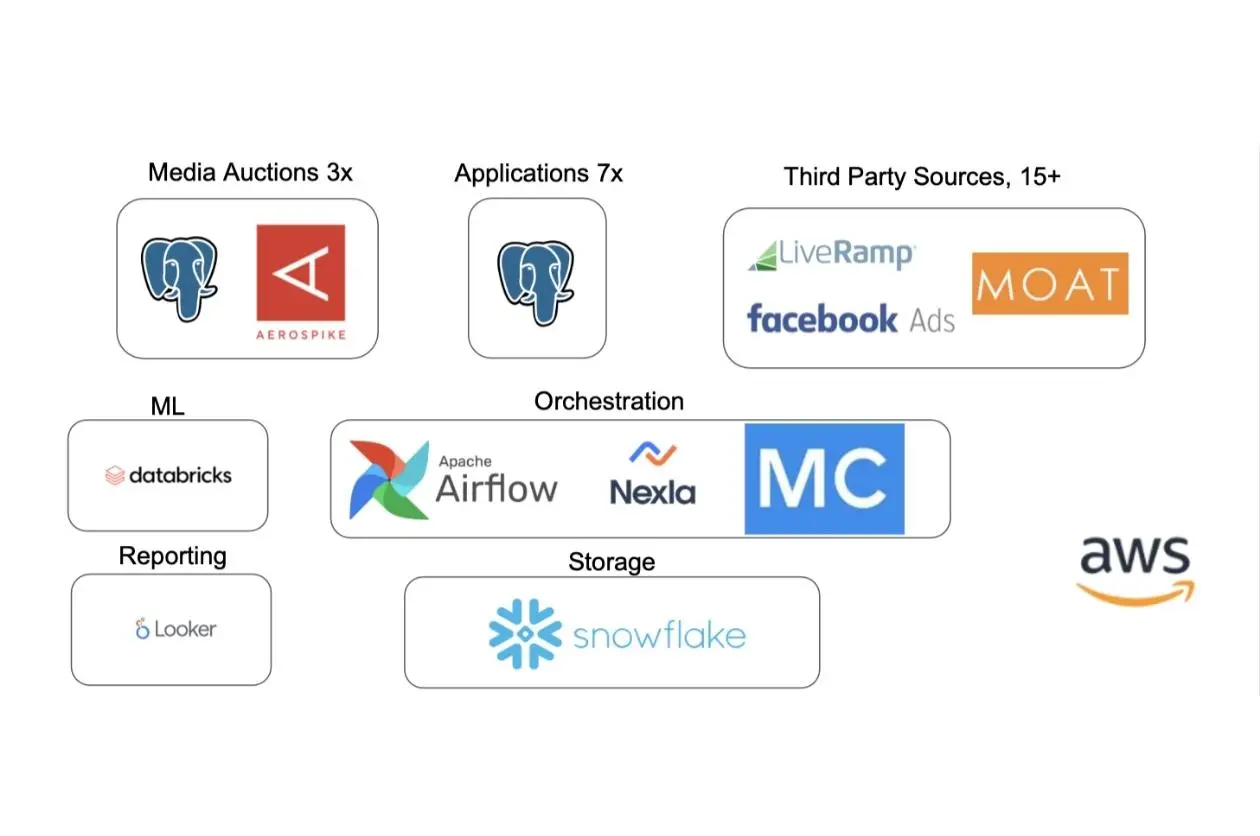
In terms of their platform itself, DataDuty team uses PagerDuty—”we absolutely have to eat our own dog food”—as well as Snowflake for data warehousing, Fivetran, Segment, Mulesoft, AWS, and Databricks for data science.
The team also recently integrated Monte Carlo for ML-powered data observability, giving them the ability to fully understand the health of data systems by monitoring, tracking, and troubleshooting data incidents at each stage of the pipeline.
Data challenges at PagerDuty
Like most SaaS companies, PagerDuty uses a lot of SaaS cloud applications (think Salesforce, Marketo, and Netsuite) and ingests a lot of internal and third-party data. Structured data, unstructured data, data coming in at different cadences, and real-time batches across different granularities are all part of the overall data ecosystem at PagerDuty.
The DataDuty team’s primary challenge is making sure the quality of the data meets end-user expectations by enabling them to make faster decisions based on accurate data.
“The dynamic nature of the business is what drives data challenges,” said Manu. “The business data needs are changing continuously, quarter by quarter, and accurate decisions have to be made quickly. Everything is data driven, so we have to be agile.”
Using DevOps best practices to scale data incident management
To fulfill their ambitious mandate, the DataDuty team implemented a number of DevOps incident management best practices to their data pipelines.
Best practice #1: Ensure your incident management covers the entire data lifecycle.
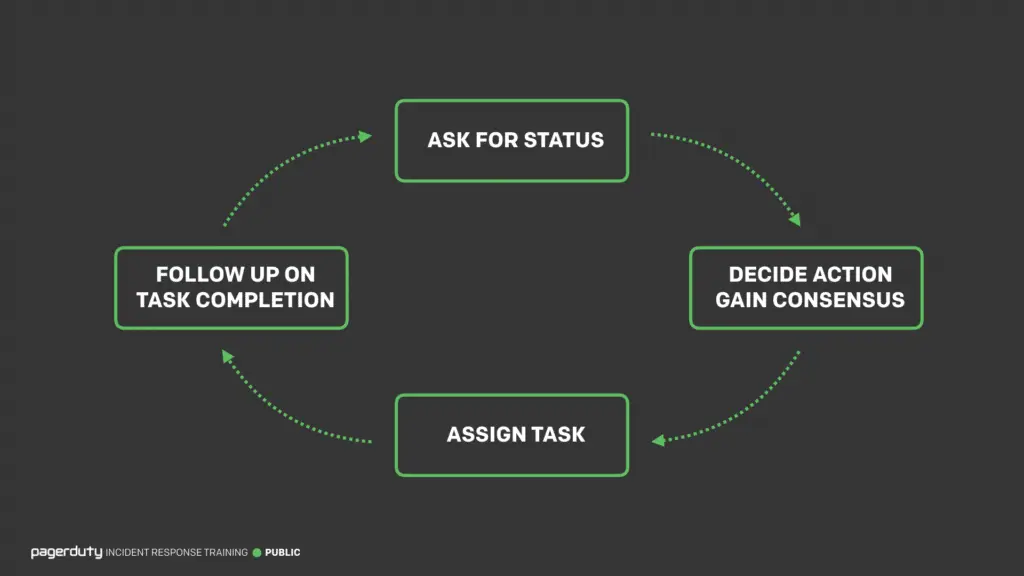
At PagerDuty, incident management for data engineers falls under what they call data operations, which is an extension of DevOps. It includes tracking, responding, and triaging for both data and pipeline issues.
Once the data is in the warehouse and all the way until it appears in customer-facing reports, there is potential for various types of data downtime, from missing data to errant models. The DataDuty team monitors for data quality issues including anomalies, freshness, schema changes, metric trends, and more.
Data observability is especially important to monitor and ensure data quality in your data warehouse. You could intervene at a data pipeline level through custom data quality checks via ETL tools, but over time the management of the logic, scripts, and other elements of your data ecosystem becomes cumbersome. Moreover, as Manu notes, issues with data trends cannot be identified by pipeline quality checks.
Best practice #2: Incident management should include noise suppression
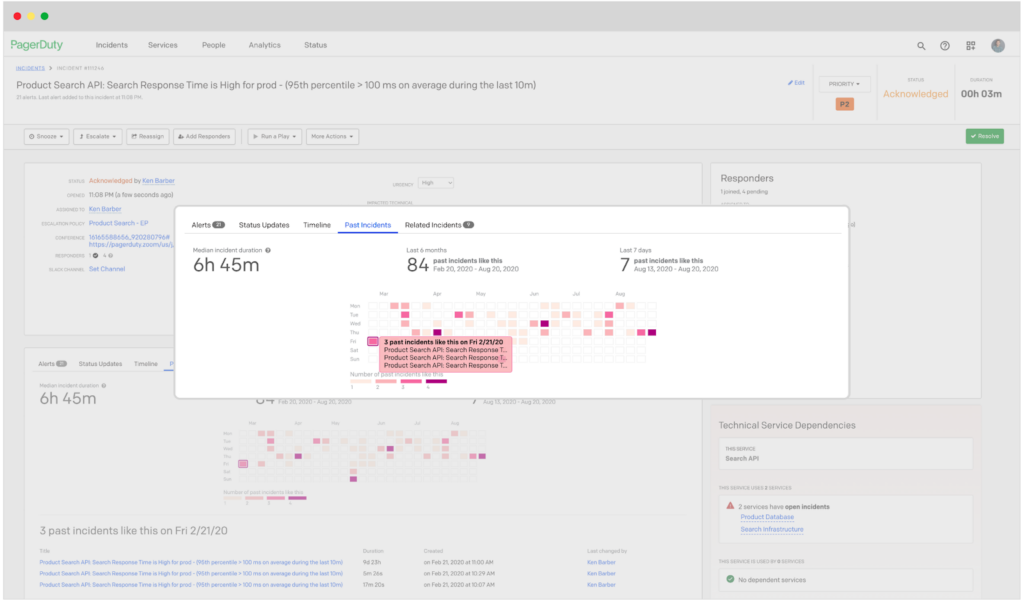
Data noise is a major issue when it comes to implementing data monitoring and anomaly detection, and at the enterprise scale, you will have a variety of “alerts” coming in on a daily basis, many of which will indicate changes in your data but not necessarily net-new “issues.” Data teams need to be able to triage between customers, business owners, and respond to these alerts in a timely fashion while delegating clear ownership over the data products themselves.
Manu’s DataDuty team uses PagerDuty Event Intelligence tod identify similar data incident alerts, suppressing multiple alerts for one incident that contains multiple data issues. This way, his team members aren’t overwhelmed with alerts and can focus on fixing the root cause(s) of the data issue at hand.
Best practice #3: Group data assets and incidents to intelligently route alerts
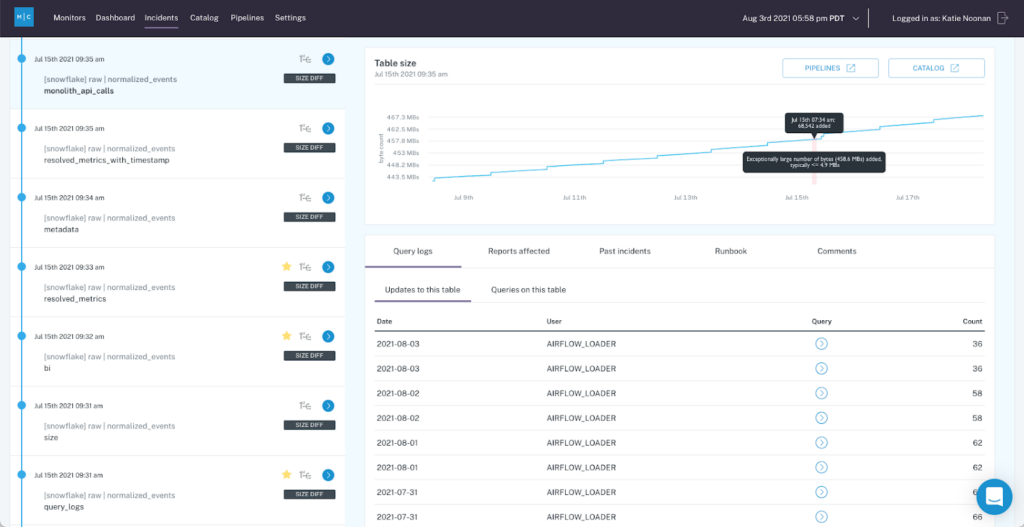
According to Manu, data observability is the first step before any data incident management steps, including incident response and escalation, can happen. After all, “my data is not refreshed” is an entirely different issue compared to an abnormal trend or metric. Teams need to be able to identify that this data issue exists over time.
When the DataDuty team began to integrate Monte Carlo with PagerDuty across their own data platform, they followed best practices from DataOps, including grouping together data issues to enable easier routing and alerting based on that 360-degree view, including:
- Grouping similar data pipeline issues together with data observability and implementing PagerDuty on top of this workflow, ensuring that these alerts were properly routed to DataDuty team. Since they use Airflow for scheduling, the team receives Airflow alerts via PagerDuty, too.
- Identifying the company’s most critical data assets, including executive-level reporting and financial reporting-level data, through Monte Carlo. Now, alerts related to those assets come via PagerDuty with an escalation policy and automatically go to additional stakeholders and the Business Intelligence team.
- Leveraging both PagerDuty and Monte Carlo to monitor the health of BI metrics, such as the number of customers, customer churn rate, the number of accounts, and the number of data incidents. These alerts are then routed to the business intelligence team so they can monitor and take action as needed.
With these best practices, PagerDuty’s platform team lives up to their mandate by approaching data incident management from a DevOps perspective—which aligns perfectly with the principles of data observability.
As integration partners, our platforms work together to help businesses identify and resolve data incidents, empowering leaders to make data-driven decisions quickly and confidently.
Curious about integrating Monte Carlo with PagerDuty for your data team? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.