Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Tenable Built a Reliable Data Platform at Terabyte Scale with Monte Carlo

Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
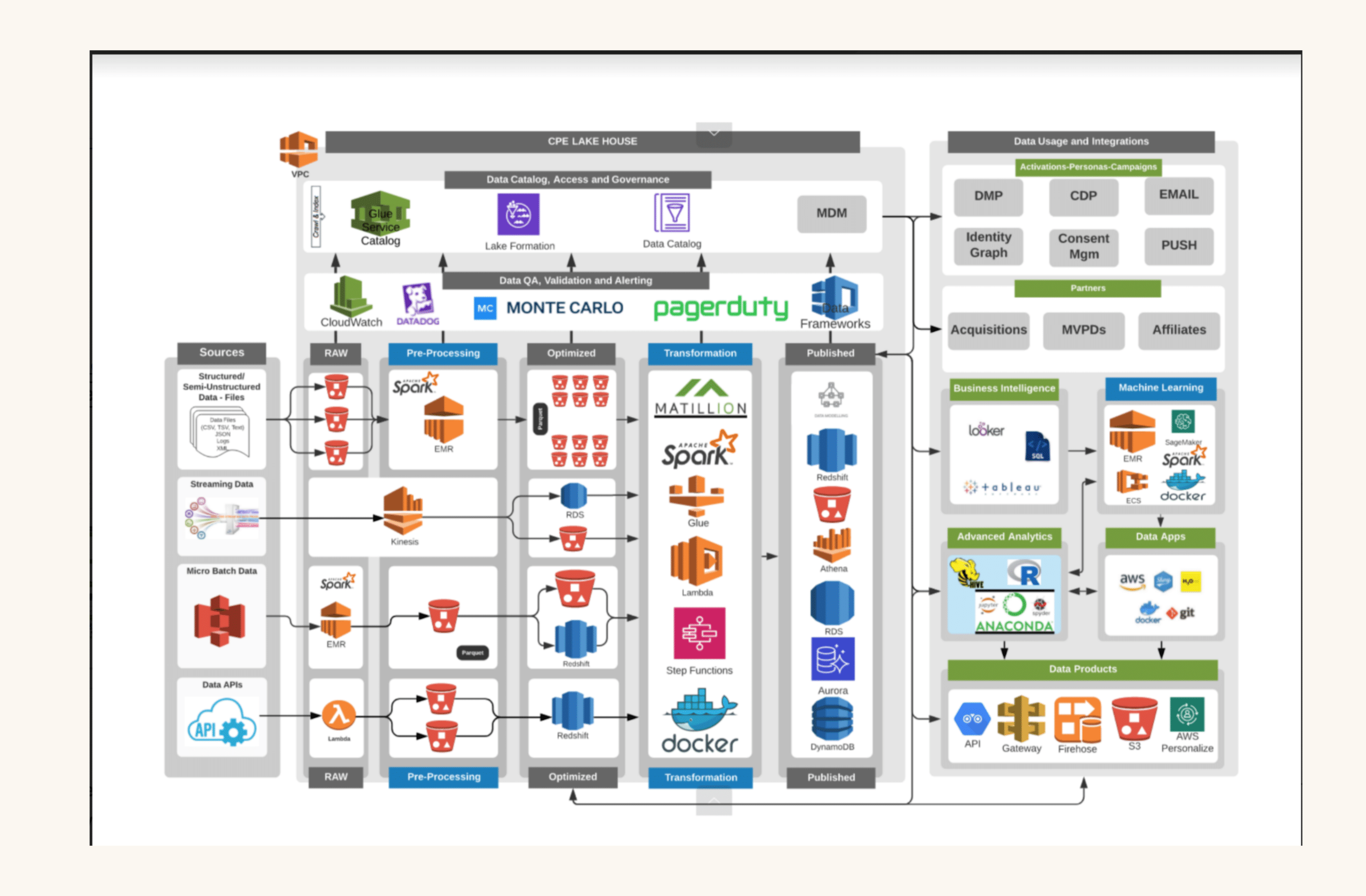
We’ve seen it time and time again — change is the only constant for data teams. New sources to ingest. New customers hungry for data. New team structures to support them. And, occasionally, an entirely new data platform to meet evolving business needs.
That’s precisely where Vinny Gilcreest, the Senior Director of Engineering, Data and Analytics at Tenable, found himself within the last two years. The data stack that once met Tenable’s business needs — monitoring and reporting on exposure risk and software vulnerabilities — was quickly becoming outdated as the industry evolved.
Vinny and his team needed a next-generation data platform to ingest complex streaming data, surface insights to customers, and power sensitive machine learning algorithms. All while ensuring data reliability from end-to-end.
Easy, right?
Recently, Mark Grossman, Customer Success Manager at Monte Carlo, sat down with Vinny to discuss the path Tenable took to building a reliable data platform — and the lessons he learned along the way.
Why a next-gen data stack was a necessity — not a luxury
Data is at the heart of Tenable’s platform. In its earlier years, the company provided coverage for software vulnerabilities, and made data about exposure risk available to its customers. But over the years, Tenable’s offerings had to evolve alongside the tech landscape to address cloud infrastructure, IoT devices, and all the other places businesses need to ensure security.
Today, the organization ingests terabytes of data on a daily basis via first-party sensors and third-party sources. Tenable’s platform surfaces that data to customers, delivers reporting and insights, and provides sophisticated ML-powered risk metrics to customers so they can understand their exposure at any point in time.
To meet those increasingly complex data needs, Tenable’s data team needed to build a new data stack from the ground up. And after six years with the company, Vinny says with a laugh, “I played a big part in building the first-generation platform, and a really key part in tearing it down.”
Fortunately, the team had buy-in from executives to undertake this long-term project. “It wasn’t seen as a luxury that we needed to basically build the next-generation data platform,” Vinny says. “Everyone was aware that was something we needed to do.”
As the team began their journey to architecting a next-gen data platform, they sought to always strike a healthy balance between building and buying. “We had a principle along the lines of, ‘Look, if someone else is doing this and does it really well, let’s use them rather than us building our own in-house solution’,” said Vinny.
Like many companies, Tenable’s data team structure has shifted over time, but they currently have a centralized data platform team that includes data engineering, data science, and a data ingestion team. The data engineering team is responsible for maintaining the infrastructure and making data available to internal and external customers.
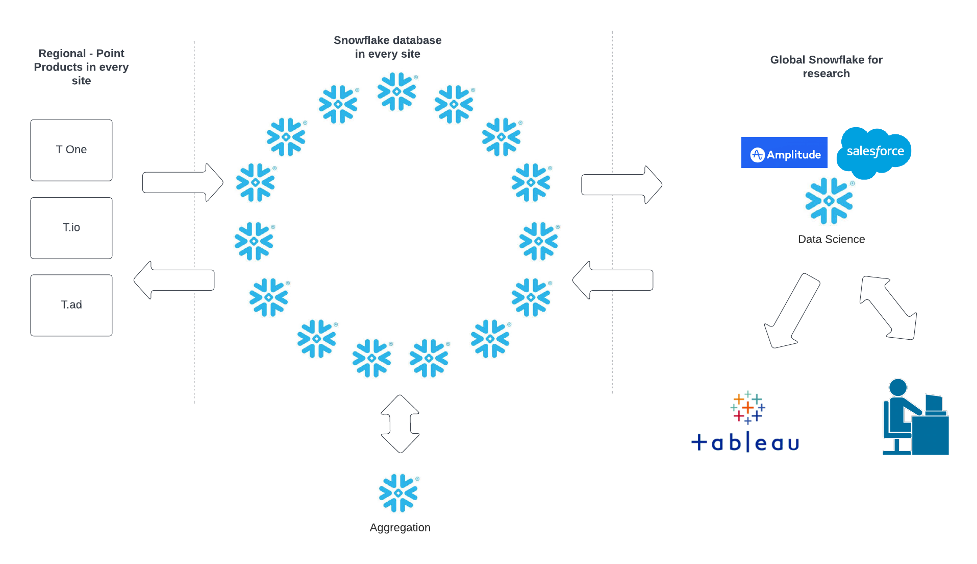
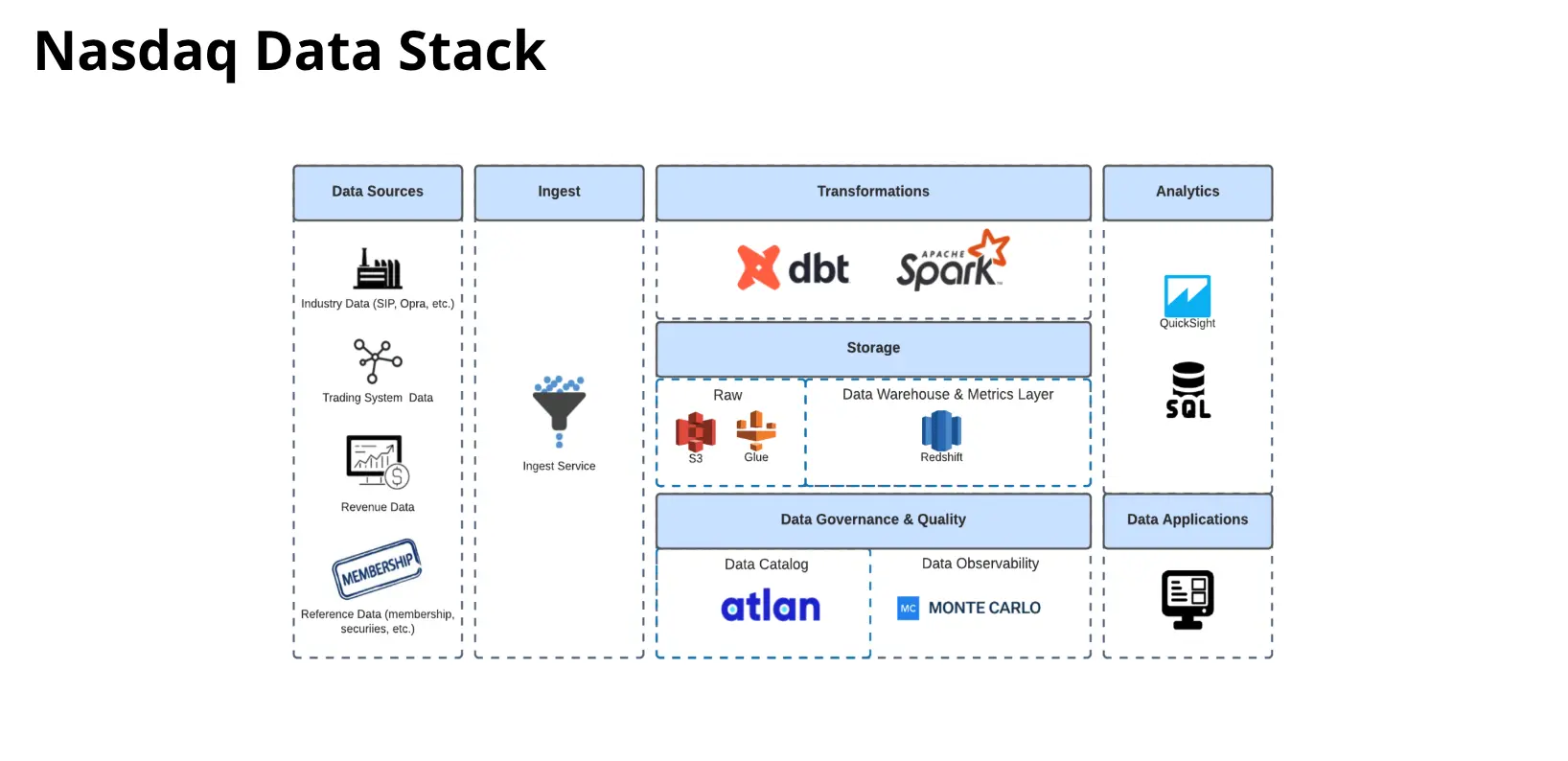
Ultimately, Tenable’s data team developed a platform built on Snowflake for storage, aggregation, and search capabilities. They chose Kafka and Kafka Stream to ingest third-party data and streaming first-party data from their proprietary sensors.
Finally, Vinny and his team needed to address data quality — an incredibly important element in their data platform.
“The products that we provide are all built around the accuracy of our data,” Vinny says. “Tenable’s history and why they’ve been so successful is because we have the most coverage in terms of being able to identify vulnerabilities. So we’ve got the ability to do this really accurately — we then need to make sure that the integrity of that signal is not lost in the platform.”
The challenge: addressing data quality at scale
Originally, the Tenable data team attempted to handle data quality monitoring and resolution internally, as they had for years. “Data quality has always been really key,” says Vinny. “It was just challenging to do it — a never-ending battle — and it was taking up quite a bit of our time.”
The team built out manual tests to address data quality issues as they came up. And they did arise, often due to stale data or changes in distribution that would result in incidents and breakdowns of data pipelines.
“We were building up a battery of tests, then we’d miss one, and we’d add another in, and it would continue,” says Vinny. “We were just building up a monolith of testing code.”
When it came time to address data quality in their new stack, Vinny knew this in-house approach wouldn’t make sense for the long-term. And it didn’t align with their principle of buying versus building when the right solution was already out on the market.
“Solving data quality issues in-house is not our core value, or what our mission is,” says Vinny. “It’s not something that’s going to differentiate us — it’s just table stakes. So when there’s a company that does it like Monte Carlo, yeah, we went for it and adopted it.”
The solution: observability with Monte Carlo
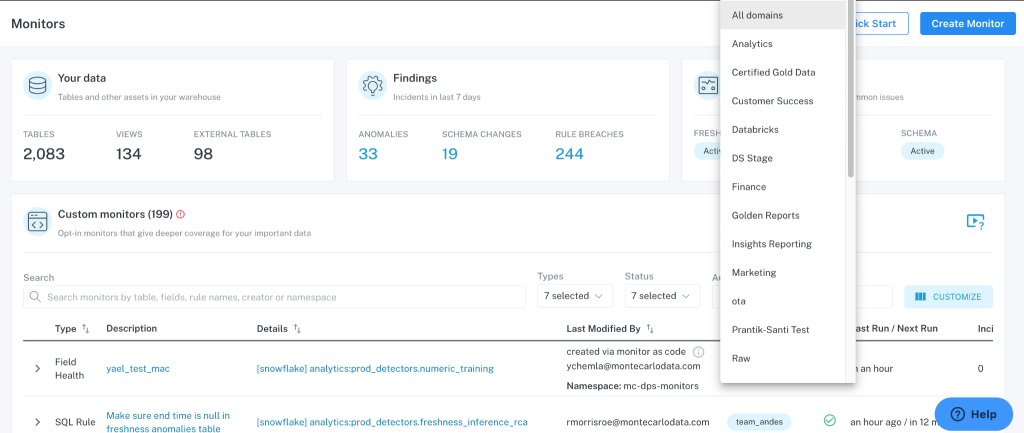
When Vinny heard about Monte Carlo’s data observability platform and saw it in action, everything clicked into place. The Tenable team implemented Monte Carlo across their data stack, quickly leveraging the AI-powered monitors that detected anomalies compared to historical patterns. Over time, the team also built out custom monitors to meet their platform’s unique requirements.
Easy, out-of-the-box coverage
Vinny and his team deployed the built-in Monte Carlo monitors for freshness, volume, and schema checks across customer tables.
“The recommended monitors are really nice,” says Vinny. “It’s not a big task to set up a new monitor, hook it into Slack, and then track alerts. It’s pretty much a frictionless setup, which is really helpful.”
Freshness, in particular, was important for Tenable to monitor and maintain for their customers, who depended on up-to-date reporting about their security risks.
“Customers need to know, accurately, what vulnerabilities they are going to need to fix,” says Vinny. “And they need to know within an expected timeframe. Having surety around the quality of the data that’s going to be delivered, on time, as expected, is really key.”
Formalized data contracts
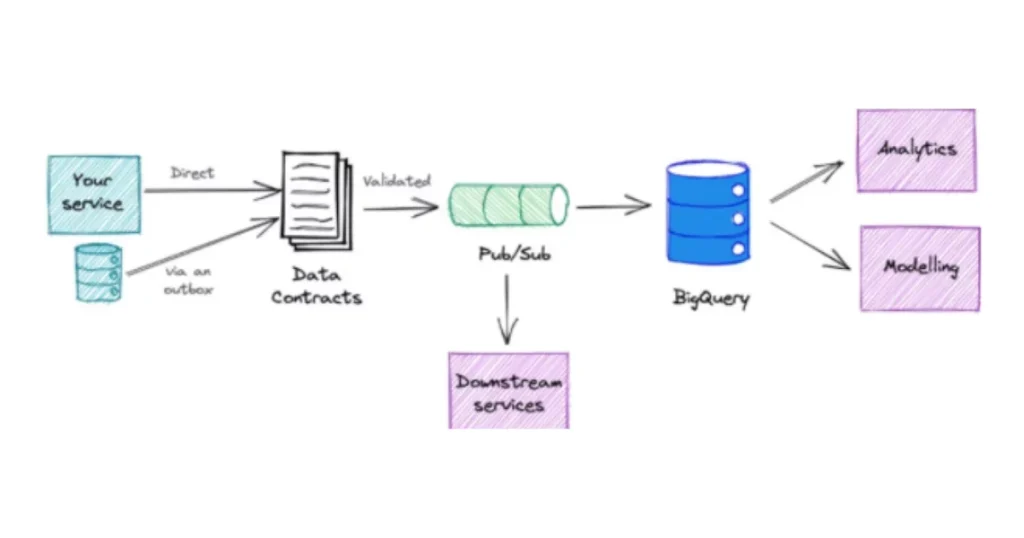
The Tenable data team was also able to introduce and manage data contracts within Monte Carlo, helping align stakeholders and data engineers on quality standards. Together, data producers and consumers agreed upon what high-quality data looked like, and formalized those standards into contracts that are managed within Monte Carlo.
Monitors as code for custom thresholds
Finally, Vinny and his team found the ability to create custom monitors as code incredibly useful for scaling anomaly detection across domains. Within hours, they could set up custom thresholds for specific use cases, ensuring the data that powered their ML algorithms was reliable.
The outcome: Fewer issues and faster detection
With data observability in place, Vinny and his team are now able to reduce the number of issues that occur, and be the first to know when data pipelines do break.
“We inject a lot of third-party data into our platform,” says Vinny, “That brings an additional layer of unpredictability. Something can happen within that data that can impact our algorithms. And we found Monte Carlo really effective at being able to identify those types of scenarios quicker than we would’ve been able to do.”
By heading off data issues proactively, rather than being informed by executives or customers, Vinny and his team are able to build trust in data and deliver on their vision of a reliable platform — no monolith of testing code required.
Tips for others building modern data platforms
As a seasoned data leader, Vinny has a few tips for other teams planning to rebuild a modern data platform:
Focus on early wins
“Having a clear business outcome that you can deliver on early is really key. I think a huge amount of these longer-term projects fail because they go on too long, people get tired of it, and never really see the value. Delivering customer value early is key, and it helps you focus on what you absolutely need to do rather than things you would like to do.”
Understand your use cases upfront
“Spend a bit longer looking at all the potential use cases at the start, and try to get your requirements in place. In some cases, we could have prioritized things more effectively if we had taken into account some of the use cases. For example, we ran into an early challenge around the responsiveness of the platform — because we were powering applications directly from our data platform, but didn’t focus on that use case from the start. So we had to do a lot of fine-tuning to get the performance we needed at that interface, between the application and our data platform.”
Gain alignment and buy-in
“Business alignment buy-in from a really good executive sponsor is really critical. In our case, the CPO and the CTO were really heavily bought in and they were able to give us cover, because it’s a long project. That alignment and bringing everyone along internally is important. We’re building a data platform for the whole company. Making sure every stakeholder is involved is always key.”
Find your build vs buy balance
“Find the balance between buying and building. We could have built something that maybe could have done a kind of similar job to Monte Carlo for a little while, but when it’s a problem that someone else has solved for us, we shouldn’t invest our engineers’ time. The opportunity cost is a fundamental principle I’ve got. That’s how we’re doing it with our platform — integrating really mature components together.”
Discover the difference of data observability
Ready to learn how your next-gen data platform can guarantee fresh, reliable data through end-to-end observability? Contact the Monte Carlo team to see our platform in action.
Our promise: we will show you the product.
Read more posts.