Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Kargo Prevents Six-Figure Data Quality Issues With Monte Carlo

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Kargo’s business has scaled tremendously from its humble beginnings as a provider of mobile phone ringtones in 2013. Today, it is a powerful omnichannel advertising company that creates innovative campaigns for more than 200 of the world’s best-known brands and now has the ability to reach 100% of smartphone users in the US.

With unprecedented hyperscale growth spurred by numerous acquisitions, data platform consolidation, automation, and reliability have been high priorities for Kargo’s vice president of analytics, Andy Owens.
“One lesson we learned was not to jump on market opportunities without focusing on the tech. Now we actively look through AWS logs and entity diagrams before we even begin to talk financials,” said Owens. “Some of the data system integration projects after an acquisition can extend for 18 to 24 months.”
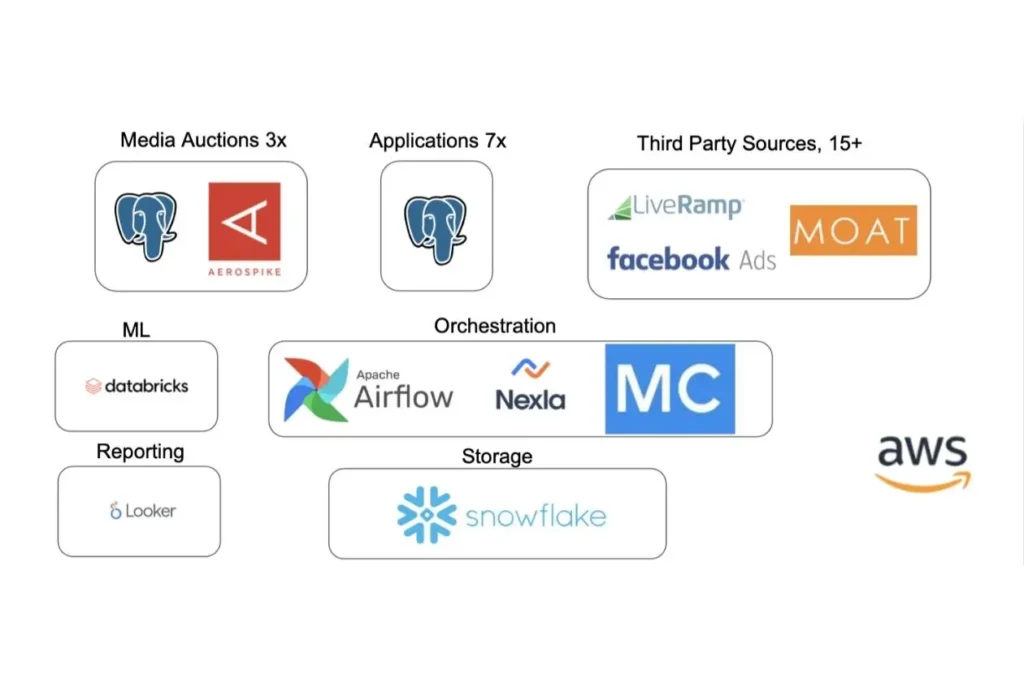
As they acquired more companies, the Kargo team made a decision to consolidate their data in Snowflake as a single source of truth with a stack consisting of Airflow, Looker, Nexla and Databricks.
“When we first started acquiring companies we saw that this app team would want to go with BigQuery or this team would want to go with Redshift. We saw quickly we had to consolidate our data warehouse and the tooling on top of that so we could scale out,” Owens explains. “Now it’s like, ‘cool you have an Athena warehouse, it’s going to be in Snowflake in 9 months.’”
The Challenges of Data Reliability at Extreme Scale
Data is crucial to Kargo’s business model. They need to report the results of the campaigns they execute for their clients with a high degree of accuracy, consistency, and reliability. They also leverage data to inform the ML models that help direct their bids to acquire advertising inventory across platforms.
The challenge? Digital auction and transaction data operates at an extreme scale.
“Media auctions– a process that consists of advertisers bidding on ads inventory to be displayed by specific users for a particular site–can consist of billions of transactions an hour. Sampling 1% of that traffic is a terabyte today, so we can’t ingest all the data we transact on,” said Owens. “Monte Carlo looks at all those operations and identifies the issues in our main tables that go into Snowflake and the upstream feeds that bind the data together for machine learning models that transact back in the auctions and client reporting.”
At this scale and velocity, data quality issues can be costly. One such issue in 2021 was the impetus for the team to adopt Monte Carlo.
“One of our main pipelines failed because an external partner didn’t feed us the right information to process the data. That was a three day issue that became a $500,000 problem. We’ve been growing at double digits every year since then so if that incident happened today [the impact] would be much larger” explains Owens.
Operationalizing Data Observability at Kargo
Monte Carlo’s data observability platform scales end-to-end across Kargo’s modern data stack to automatically apply data freshness, volume, and schema anomaly alerts without the need for any threshold setting.
The Kargo team also utilizes the Monte Carlo platform to set custom monitors and rules relevant to their specific use case.
“[For the custom monitors] the production apps QA engineer would look at [the data] and create a rule to say we expect the ID to be this many digits long or the cardinality to be this based on the product,” said Owens. “Our machine learning models are built on small cardinality of data and not a lot of columns. If there is a deviation the model will become biased and make poor decisions so the match rate must be tight with the data streams coming in. Pointing Monte Carlo [to monitor that] wasn’t difficult.”
Once the issue is detected, an alert goes to a Slack channel with the relevant developers and business users. The dev team can then leverage Monte Carlo’s advanced root cause analysis functionality–including features such as data lineage, query change detection, correlation analysis, and more–to pinpoint and quickly fix any issues.
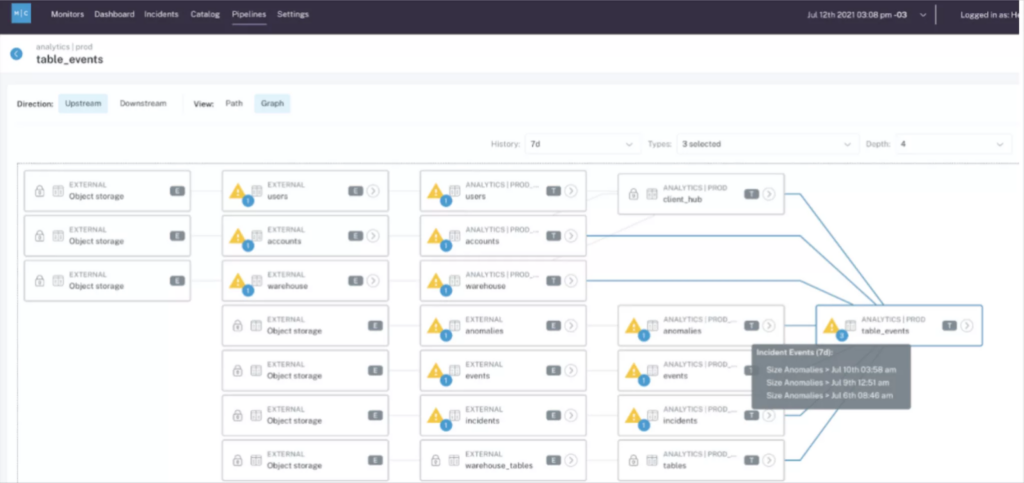
Owning Data Quality
Data observability has made an immediate and quantifiable impact at Kargo. Owens recalled a specific example where Monte Carlo provided a developer increased visibility, and thus ownership, into the impact of a code commit.
“A developer released something on a Friday afternoon and within three hours reverted the code. I asked them, ‘what happened, how did you know to turn this off?’” said Owens. “He said, ‘I saw transaction volumes tanking [from a data volume alert sent by Monte Carlo] so I turned it off.’”
Owens estimated that particular issue would have cost Kargo approximately $20,000 had the developer not been alerted and reverted the code.
“Previously, our developers didn’t have visibility or feel ownership of these business problems. They shipped and QAed,” explained Owens “They perform fixes based on alerting now.”
That recent experience was night and day compared to the 2021 data incident.
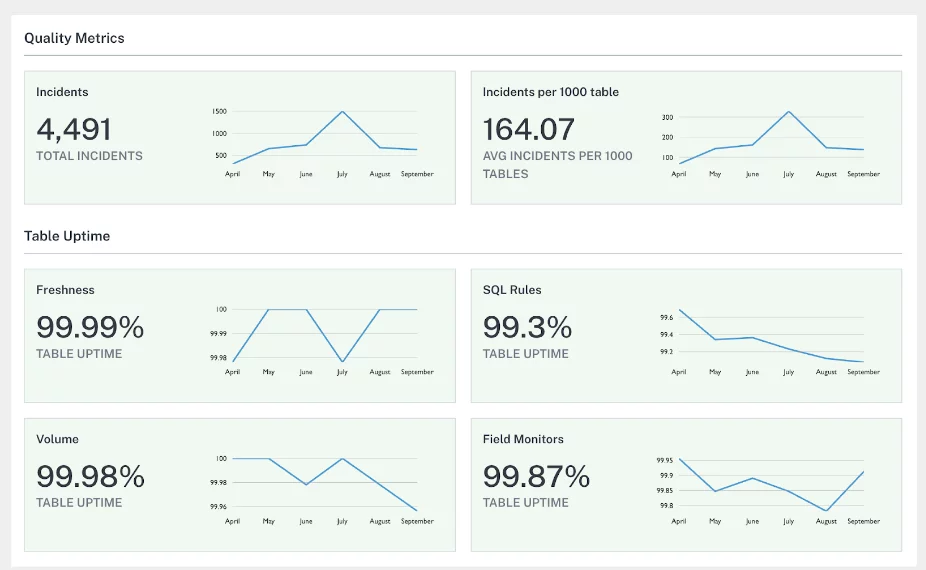
“In 2021, we were flying blind. Our developers didn’t know where to investigate and data engineering teams were trying to humpty dumpty fix dashboards. That was a huge waste of time,” said Owens. “Data quality can be death by 1,000 cuts, but with Monte Carlo we have meaningfully increased our reliability levels in a way that has a real impact on the business.”
Interested in how data observability can help your organization prevent six figure data quality issues? Talk to us!
Our promise: we will show you the product.
Read more posts.

![[VIDEO] How Resident Drives Data Observability with Monte Carlo](https://www.montecarlodata.com/wp-content/uploads/2021/03/Screen-Shot-2021-03-19-at-12.45.34-PM.png)