Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Using DataOps To Build Data Products and Data Mesh

Michael Segner
Michael writes about data engineering, data quality, and data teams.
At our latest IMPACT summit, Roche shared their data mesh strategy for creating reliable data products with DataOps. All the images in this post are taken from that session unless otherwise specified. Here are the session takeaways:
Roche, is one of the world’s largest biotech companies, as well as a leading provider of in-vitro diagnostics and a global supplier of transformative innovative solutions across major disease areas.
The goal of the Roche data team is to maximize the outcomes of customers and patients through data and analytics products. However, in early 2020 they were on legacy on-premises infrastructure in a classic monolithic architecture, with multiple physical and virtual servers that were hard to maintain and slow to scale.
Their average release cycle was three months, which was also about the amount of time it would take them to scale compute.
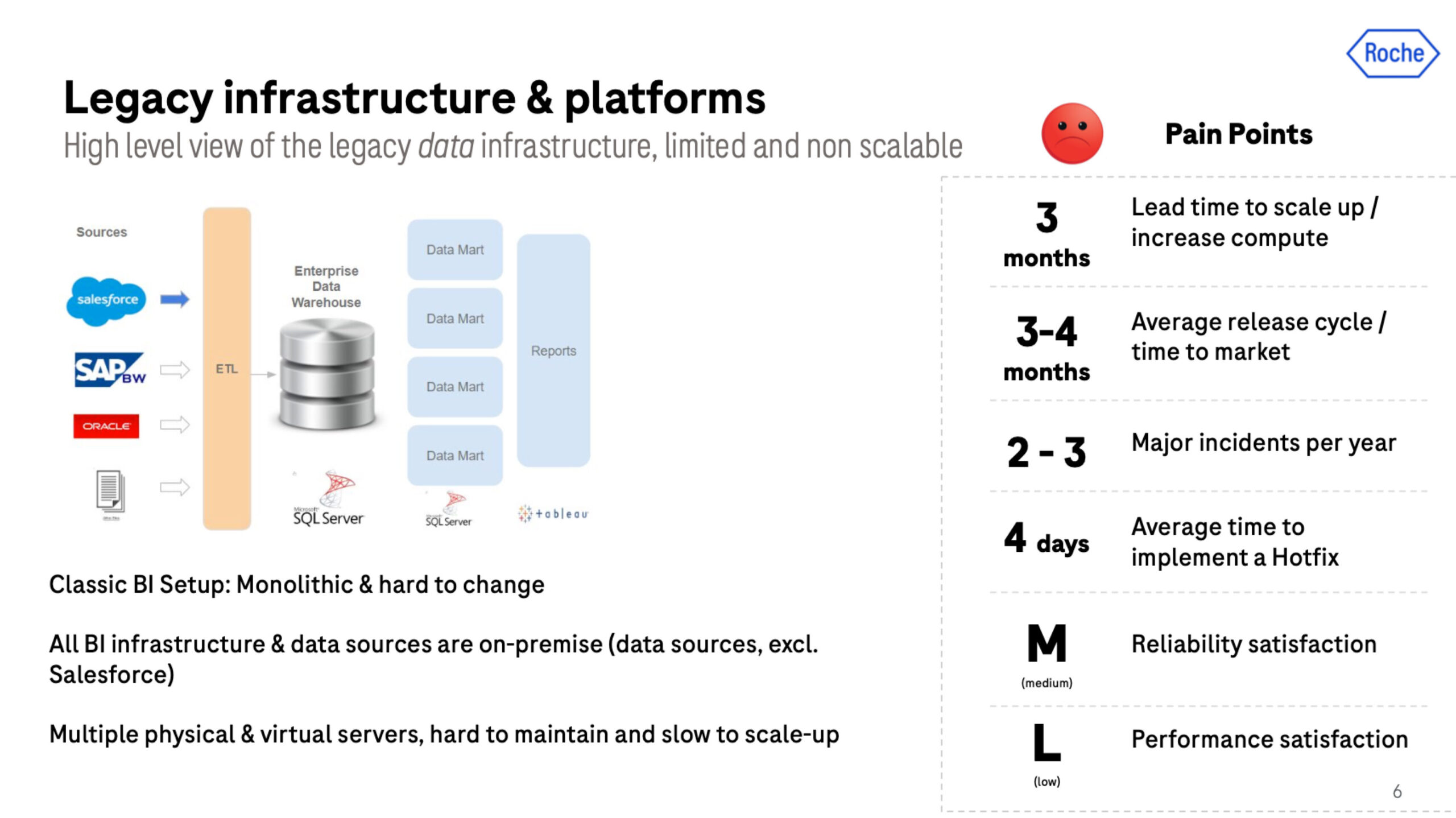
There were about 3 major data quality incidents a year and the data team was scoring medium to low on our reliability and performance satisfaction indicators. It became clear they had to shake things up.
This started a two-year journey that would involve Roche migrating to the cloud, adopting a modern data stack, and implementing data mesh. It was not just a task of shifting 1s and 0s, but a true sociotechnical journey that involved learning new lessons and shifting old mindsets.
Here is what they learned:
First steps towards data mesh: philosophical underpinnings
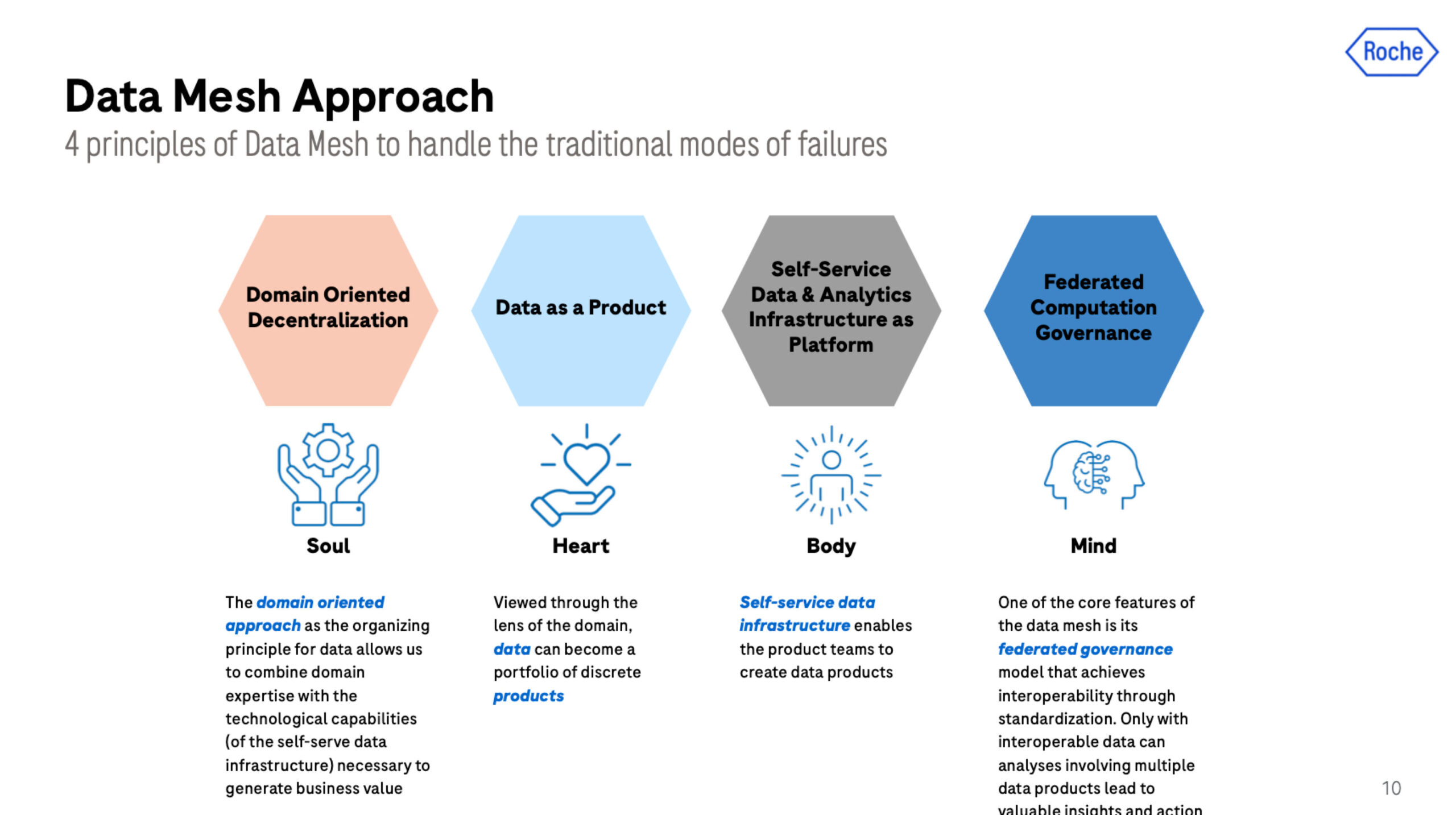
The four principles at the guideposts in any data mesh journey, which were referred to in the session as the soul, heart, body, and mind:
- Domain-oriented decentralization
- Data as a product
- Self-service data and analytics infrastructure as platform
- Federated computational governance
Roche adopted all four and strongly emphasized the data as product and self-service principles.
But that wasn’t the only framework shaping their transformation. They combined these principles with FAIR, a popular framework in the world of pharma that stands for findability, accessibility, interoperability, and reusability.
When they started this journey, the data team did not want to leave modeling and architecture behind. So they agreed to leverage Data Vault 2.0 data modeling within data products and across domains. It seems like an obvious choice in retrospect, but during the session it was described as one of the more difficult, but key, decisions that was made.
Building the platform as composable architecture
Their next step was to build the product…that would be used to build data products. In other words, the data platform.
This is a crucial step because without the proper choices there is a high likelihood that decentralized domain teams get locked into platform creation with everyone reinventing the wheel, rather than value creation by building awesome data products.
The data team’s approach can be defined as a composable architecture, which is a capability based platform model. They created a separate platform team with the mandate to not get involved in maintaining or creating data products being stood up by the domain teams.
The platform team started thinking through which services domains would need to build, maintain, and deliver high-quality, FAIR data products to their end-users. These were:
| Capability | Technology |
| Data ingestion | Talend, Qlick |
| Data modeling | Lucidchart |
| Code repository | Gitlab |
| Data visualization, data discovery, and data science | Tableau, ThoughtSpot, Dataiku, Alteryx |
| Security and access control | Immuta |
| Data quality and data observability | Monte Carlo |
| Publication and consumption | Collibra, RDM Portal (home built solution) |
| Release and orchestration | DataOps.live |
| Storage and compute | Snowflake |
Of course, a platform needs to be a combination of tooling AND process. As previously mentioned, the data product creation process is primarily done by the domain teams. However, the platform team is involved in a few key checkpoints such as:
- Data product discovery and accelerator: Roche starts with understanding how data product discovery concepts can be applied to identify what type of data product is needed to achieve business outcomes and solve business challenges.
- Lean inception workshop: They then go through a cycle of how to get the data, how to curate it, and how to ensure it’s fit for its primary purpose, but also how it might be able to be used by other domains.
- System risk assessment: They make sure the data product is safe, secure, and ready to be integrated.
- Data product team onboarding: This will be the final checkpoint to make sure the domain team is enabled to be successful.
Data mesh in three planes
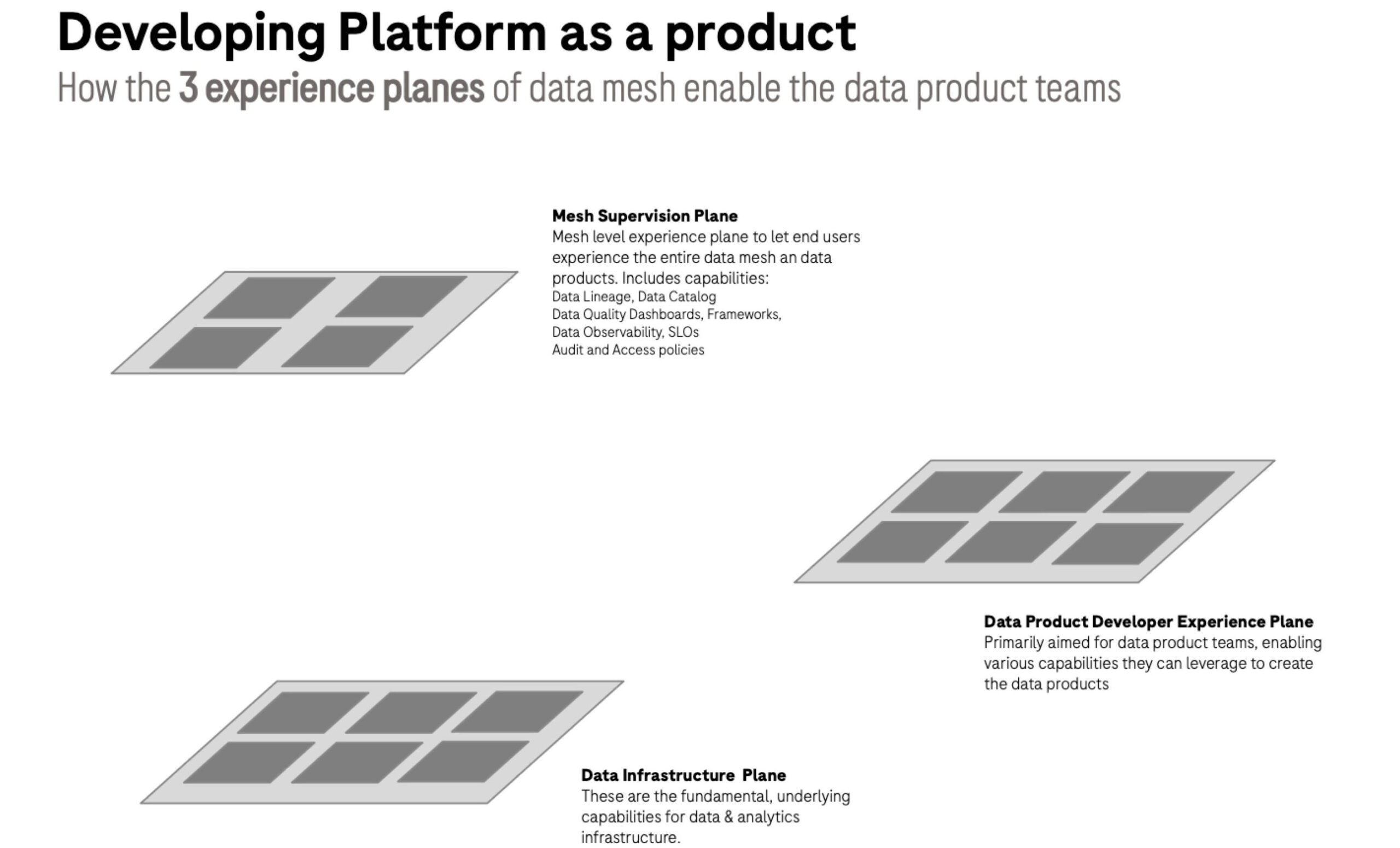
Of course, according to data mesh founder Zhamak Dehghani the platform is only one (data product developer) of three experience planes. The other two of course are the data mesh experience plane and the data infrastructure plane.
The mesh supervision plane is where you are looking at the overall experience of what domain exists and how the data exists within those domains. How are they connected together? Can you find the data products you need? Are they reliable enough for your use case? This is where solutions like Monte Carlo, Immuta, Collibra, and Data Mesh Design Studio come into play.
The underlying infrastructure plane of course involves your shared cloud infrastructure components, your AWS/GCP/Azure/Snowflake, but also your data ingestion and API management components. Also important here is your account security setup.
The three plane framework can also help your team consider your user personas. Key members typically include not just your data product team members, but also your business analysts, governance stewards, data scientists and others.
4 fundamental use cases that enable data product self-service
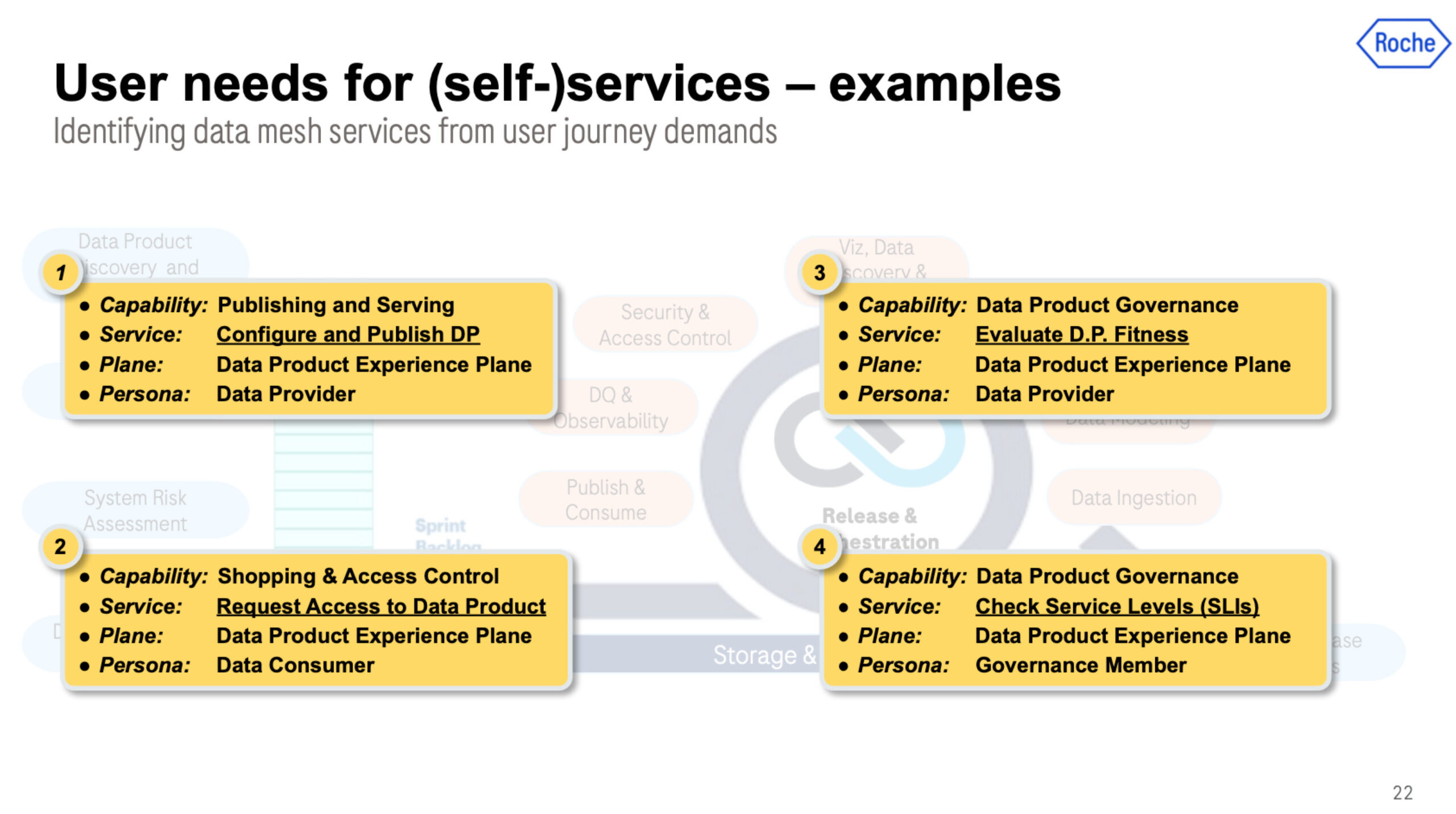
Data product self-service is tricky enough that the topic could be its own blog. As you can see in the image above, Roche identified four core capabilities to enable self-service. For each capability, they then determined what services were needed, which experience plane it comprised, and the core user persona. Let’s walk through each.
#1 Configure and the publish data product
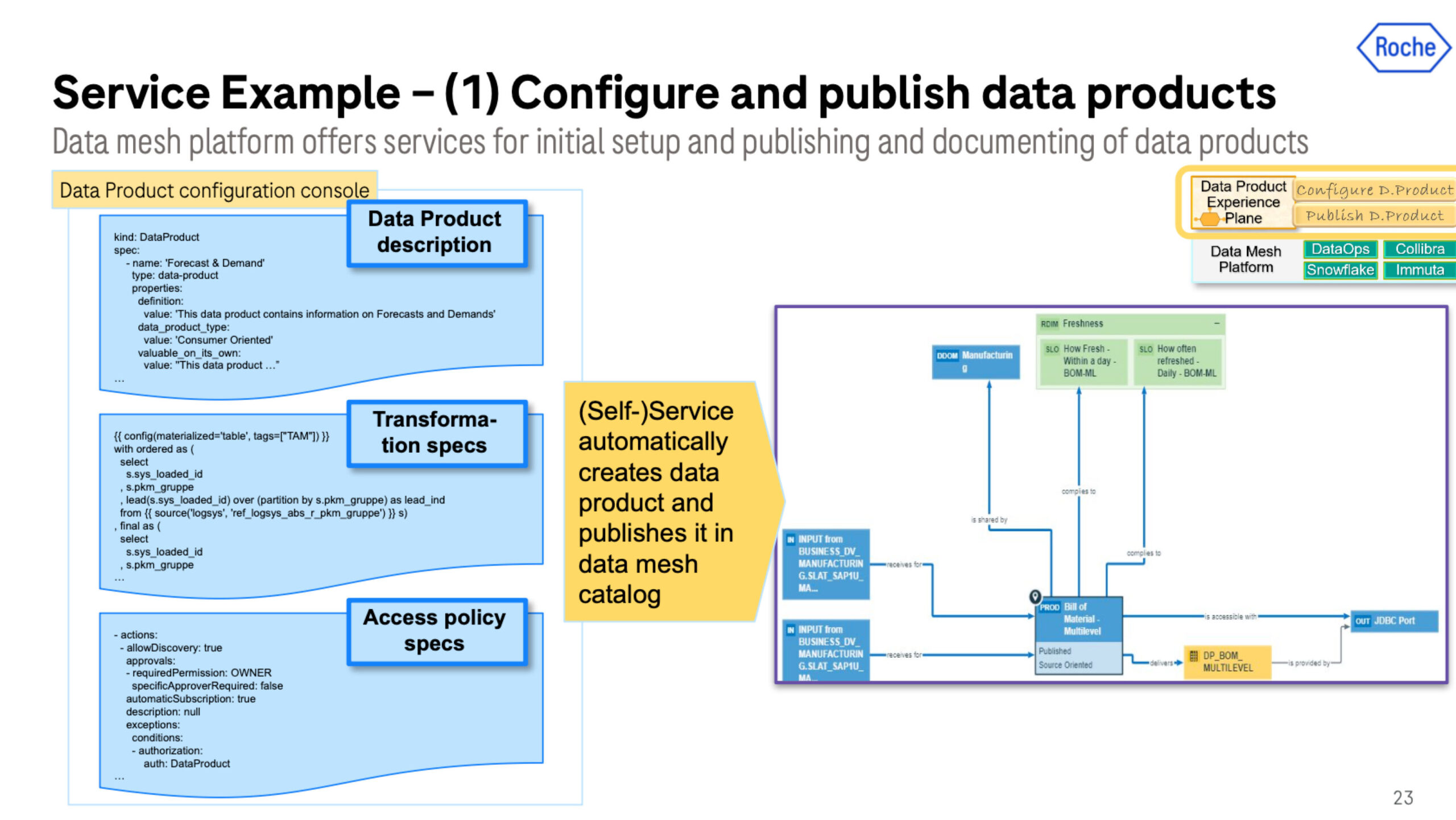
Each data product needs to be produced with a description, transformation script/code, and access policy. This looks and operates similar to data contracts with the goal of defining and enforcing the meaning and structure of a data product.
This information is added automatically using our orchestration engine and micro-pipelines to the data catalog when the product is published. There is a custom front end portal with user-friendly UI to enable searchability and findability.
The catalog entry has service levels and service-level indicators specific along with the policies, tags and data sources that were previously defined and fed into their access management tool. Having these SLI indicators surfaced in this manner is important for accessing the data product which is the next use case.
#2 Request access to the data product
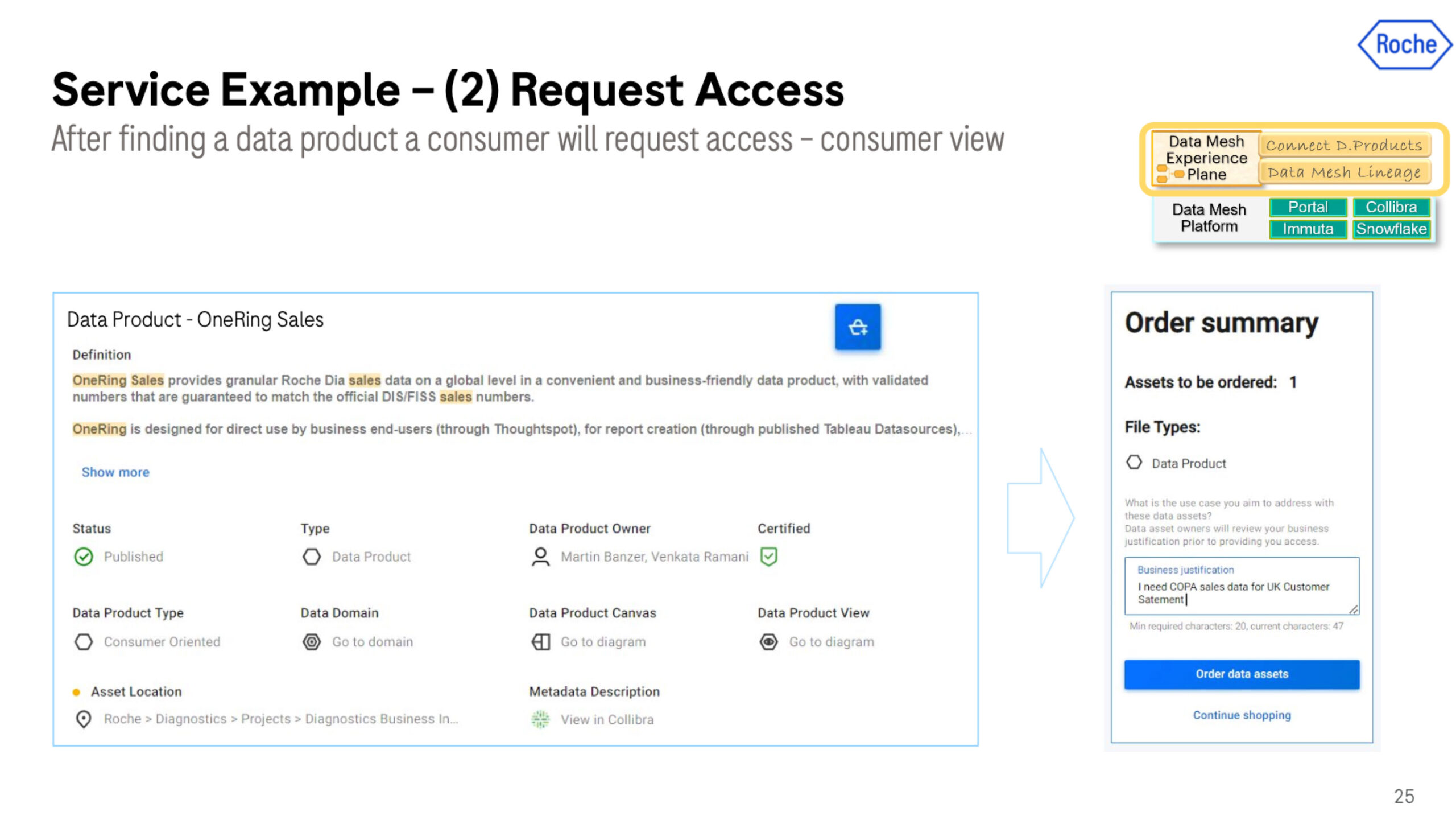
Once the data product has been published and found within the data catalog, there will be data consumers who will want access. It could be another data product team, an analyst, or a data scientist.
From here, they can look at the whole data lineage and have this shopping experience that lets them know this is exactly what they need.
From the user side of things, it’s very simple. They “place an order” for the product with a click of a button and a sentence of business justification. On the backend, it’s a much more complex process involving a combination of ServiceNow, Immuta, Snowflake and other solutions.
#3 Evaluate and show data product fitness
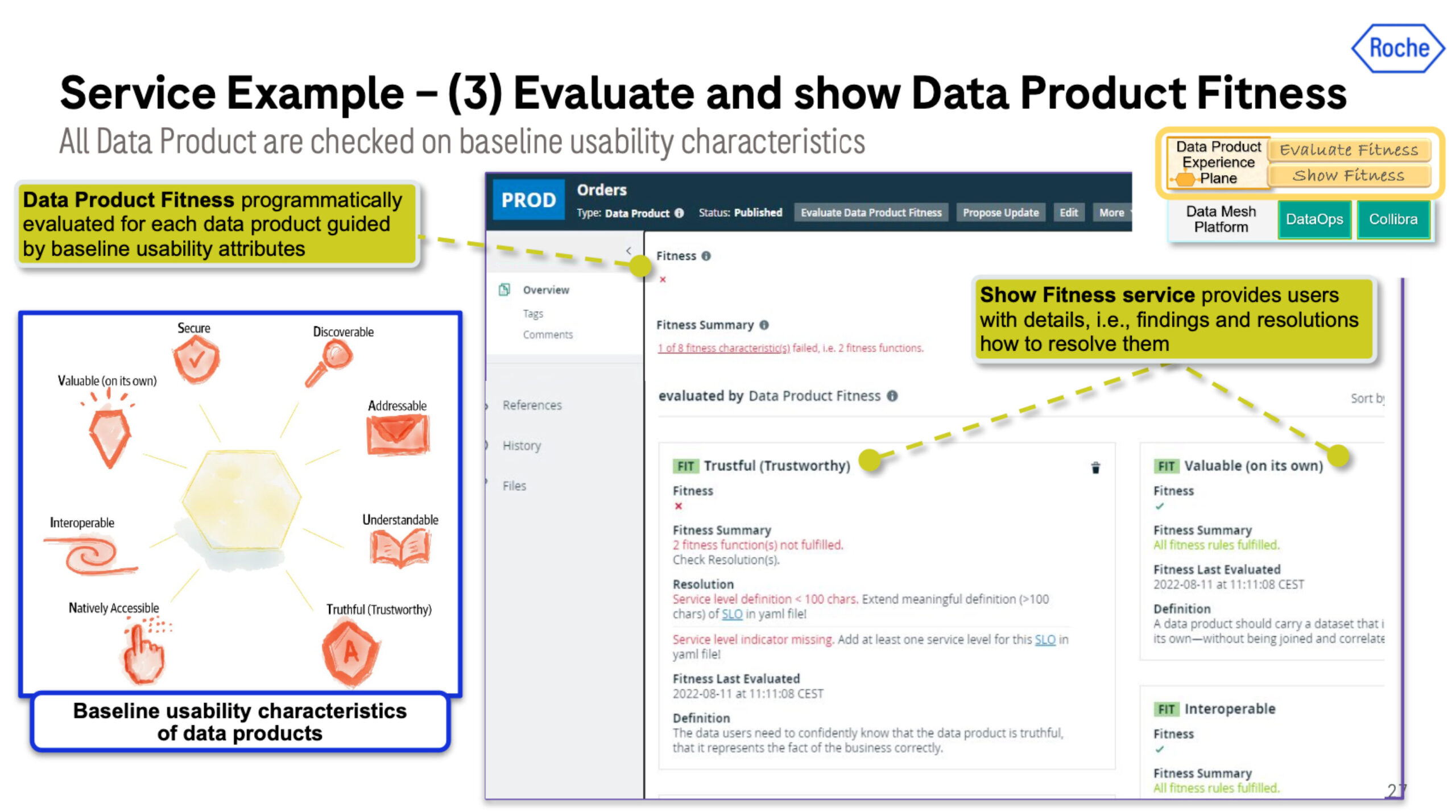
The next use case to enable self-service is to evaluate the data product’s fitness for the task at hand. Is it valuable, reliable, and interoperable? The fitness functions are defined and pushed down to a catalog to be surfaced.
To do this the Roche data team needed tools that can programmatically evaluate each data product guided by baseline usability attributes. This is critical to encouraging reusability and unlocking the ability to scale. They didn’t want teams reinventing the wheel each time.
#4 Check service level indicates (SLIs)
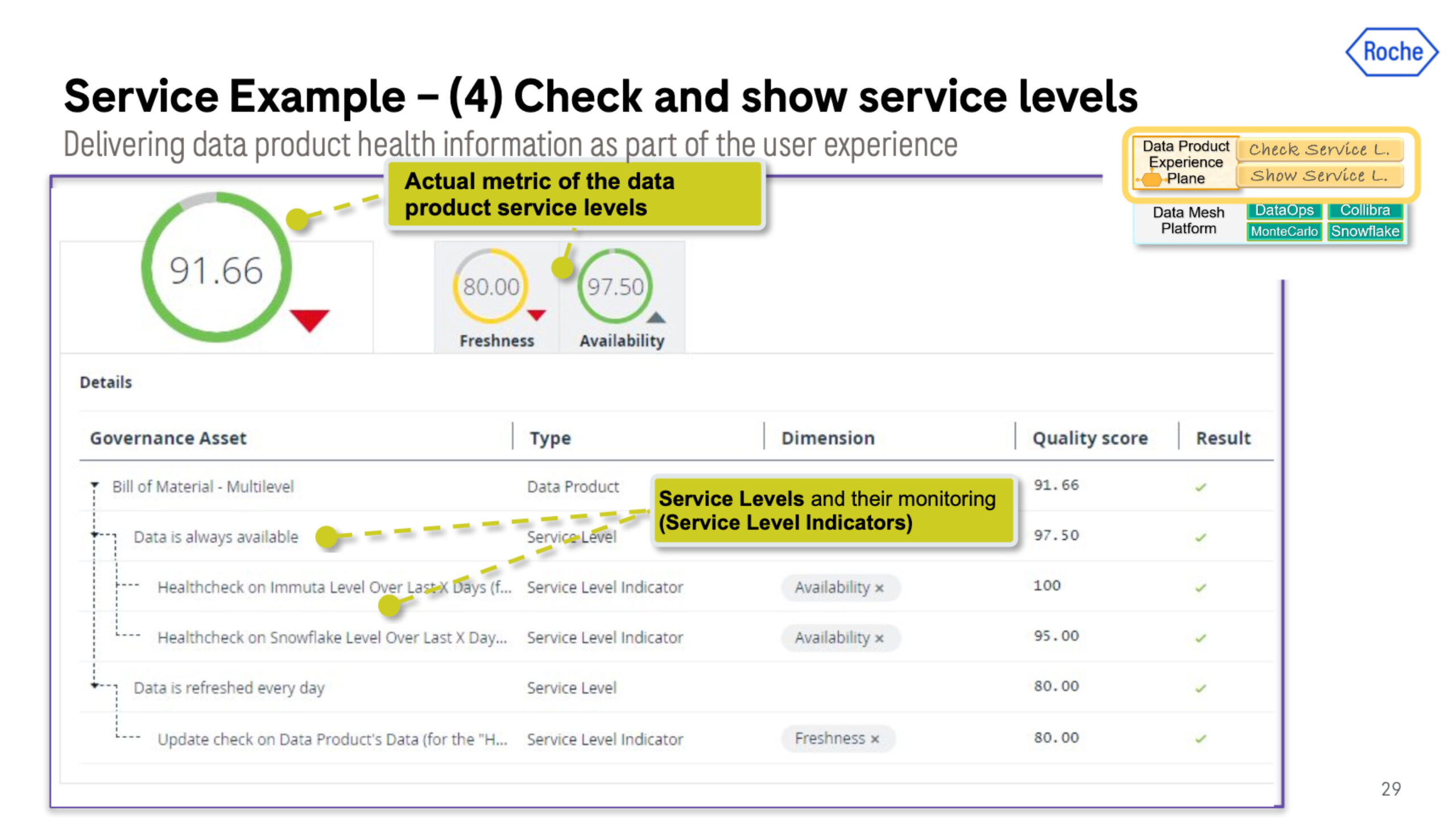
The fourth use case to enable data product self-service is evaluating and publishing the service level adherence of the data product. For example, a data product may have a SLI that the data will be refreshed every day, or every hour. Another example would be how many data incidents does the data product experience.
The mechanism they use to measure these SLIs is the Monte Carlo data observability platform which checks the 4 pillars of data health including: freshness, volume, schema, and quality (range, %uniques, etc.). The aggregate monitoring results from Monte Carlo are collected by our orchestrator, DataOps, and published in Collibra, their data catalog.
Automation by design
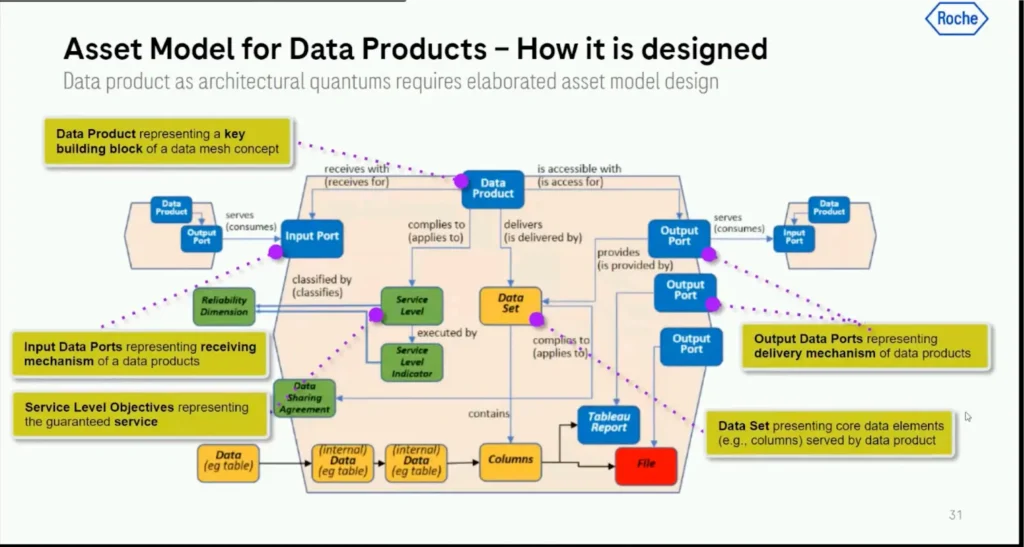
In order to make all of this possible, the team needed to build an asset model that fully defined and incorporated all the functionality expected in a Roche data product.
This ranged from what kind of data sets would be included, the structure, service level indicators, input ports, output ports, and more. Without an agreement on these standards, it would have been difficult to scale the data product process.
Interested in how to build a data platform like Roche? Schedule a time to talk to us by filling out the form below!
Our promise: we will show you the product.
Read more posts.