Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Backcountry Increases Data Team Efficiency by 30% with Monte Carlo

Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
Online retailer Backcountry knows a thing or two about big adventures.
Across multiple specialty brands and websites, the Park City, Utah-based company sells clothing and gear for outdoor sports enthusiasts. From hiking and camping to mountain biking and ice climbing, they cater to all kinds of experiences.
But within the organization, one recent journey required some extra-special gear: the migration from a legacy platform to a modern, cloud-based data stack. No easy feat. So for Prasad Govekar, Director of Data Engineering, Data Science, and Data Analytics, sourcing the right technology to support his team was an absolute must.
We love a good reliability tale, so we recently sat down with Prasad, along with Data Engineering Manager Mauricio Soto and data engineering lead Javier Salazar, to learn about their thrilling quest for peak data performance.
The challenge: Migrating to a modern data stack left data quality blind spots
Ensuring quality data was always a top priority for Prasad and his team. Backcountry relies on data to power nearly every facet of its business, including customer acquisition, segmentation and personalization, marketing, merchandising, and customer support. But the data team was ingesting large amounts of data from an ever-increasing number of sources, and the legacy system wasn’t able to perform at scale.
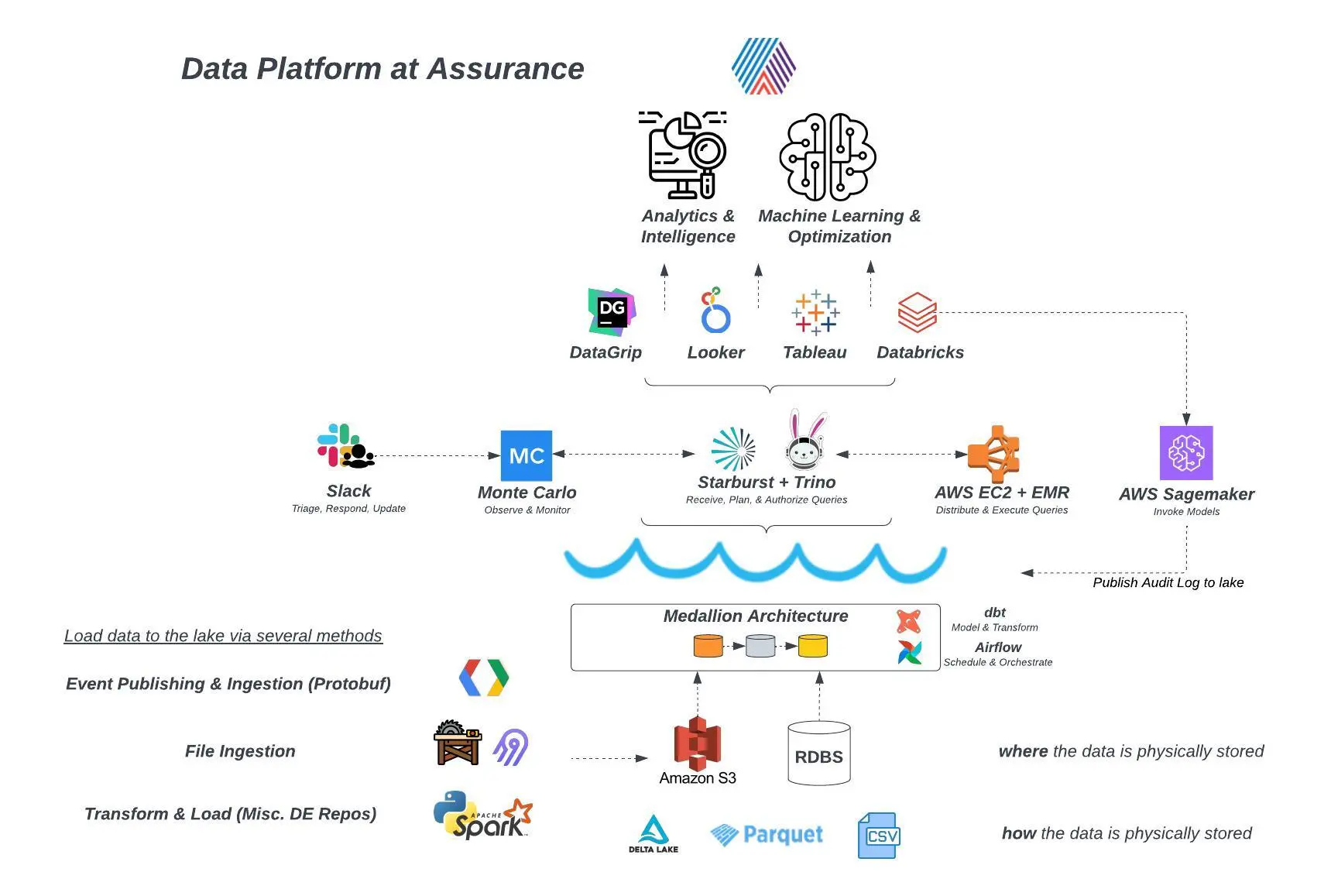
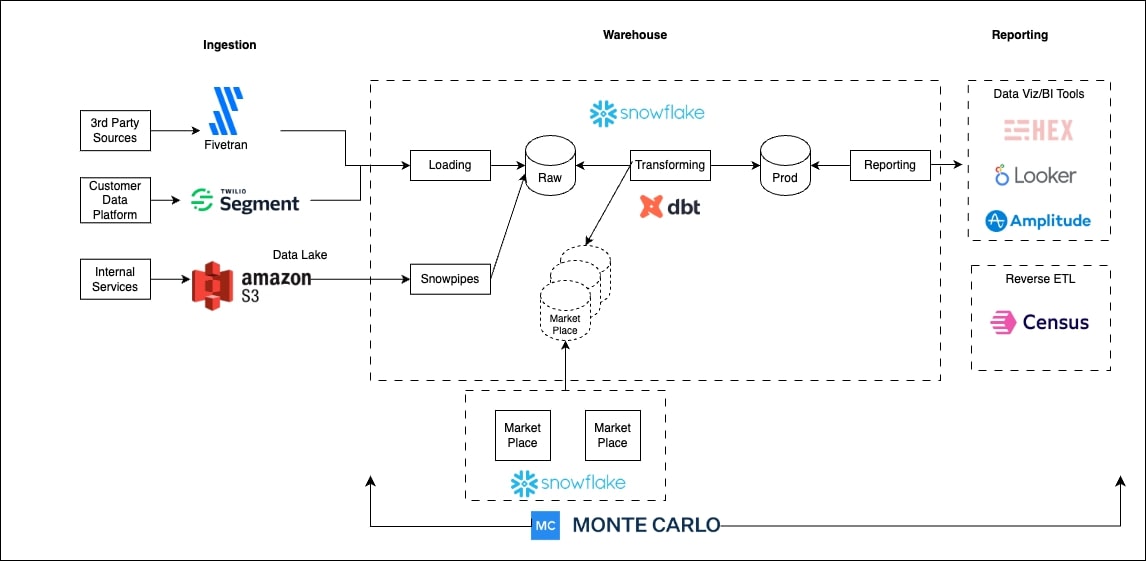
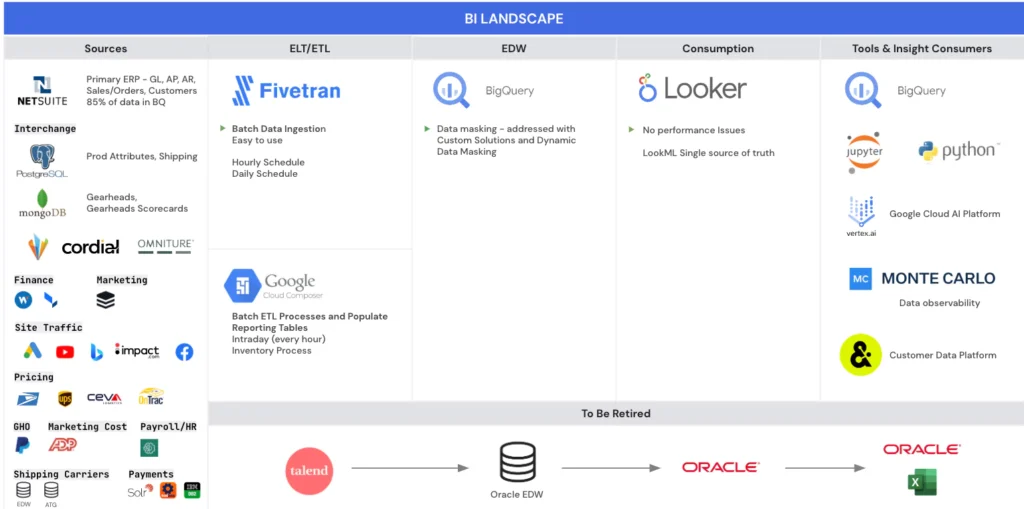
So the Backcountry team had to move quickly to migrate from a legacy stack to a modern data stack. They built their stack around the Google Cloud Platform, including BigQuery, Looker, Airflow, and Fivetran.
But along the way, it became clear that there were a lot of unknown unknowns in their data. They needed to ensure the company’s data quality needs were being met.
“As we went along the journey from our legacy stack to our modern data stack, there were issues around the accuracy and efficacy of data pipelines,” said Prasad. “We needed tools and toolsets that could enable the data engineers to keep an eye on the data across every hub.”
With a lean team of just seven people, including Prasad, manual testing simply wasn’t an option. That small group of data pros encompassed data science and data visualization specialists, a production support team to handle incidents, and a few data engineers. Especially during and after the migration to the modern data stack, those hard working engineers wouldn’t have the capacity to develop manual testing to handle the ever-increasing volume of data.
The team needed an automated way to understand data health, as well as monitor and alert the relevant people when anomalies occurred.
The solution: End-to-end data observability with Monte Carlo
One of Prasad’s colleagues recommended Monte Carlo’s data observability platform, which uses automation to provide monitoring, alerting, and end-to-end lineage at scale. Knowing his team needed a data quality solution but didn’t have the time or resources to build their own, the Backcountry data team took the leap with Monte Carlo.
Javier, who directly oversees data engineering, quickly became a big fan and advocate of the platform. Automated detection, domain-driven notifications, and field-level lineage meant migrating from a legacy system to a modern data stack — without compromising data integrity — became a lot more achievable.
Automated detection

With Monte Carlo providing automated, end-to-end anomaly detection across all production tables, it was suddenly possible for the data team to be the first to know about quality concerns. This allowed the data engineers to triage and manage incidents at scale, often notifying the relevant stakeholders before any impact was felt.
For example, the team got a notification that a table that doesn’t normally see deletions suddenly had 50,000 rows deleted. Javier and his team were able to look into the issue, see that the source had changed, and validate what was happening with the owner of the data.
“We get the ability to say to the business, ‘We have an issue for the moment, please don’t make decisions based on this data that is incomplete right now’,” says Javier. “And in that way, we ensure that the business doesn’t lose trust in us and the data.”
By flagging the issue early, the data team can prevent a small error from becoming a full-fledged data incident. And often, the team can remedy the problem before unreliable data makes its way into the downstream systems.
“We’re even avoiding sending emails when something breaks and we need time to fix it,” says Javier. “The business normally doesn’t realize we have issues, because with Monte Carlo, we’re detecting them five or six hours before they would impact our platform.”
This automated detection and alerting allow Backcountry’s lean data engineering team to stay on top of freshness, volume, and schema checks at scale.
Reducing noisy alerts
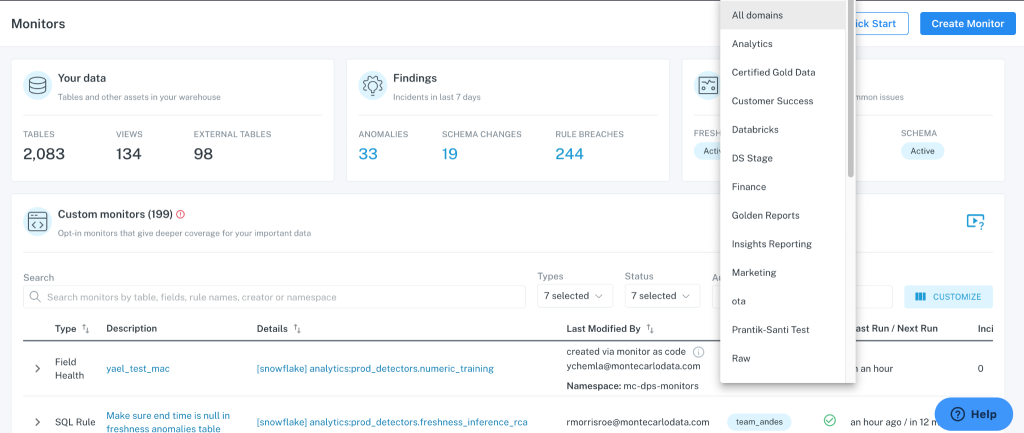
The Backcountry data team mostly relies on Monte Carlo’s out-of-the-box alerts, as well as custom monitors they developed to handle specific use cases. But since theirs is a small team, Javier wanted to be proactive about minimizing noise.
“When we implemented Monte Carlo, we had a lot of monitors running, and we received a lot of notifications,” said Javier. “So Monte Carlo gave us the option to create domains and separate them based on what we need.”
These domain use cases enable the data team to reduce notifications and white noise by segmenting alerts according to data owners, data users, and data use cases. This makes for a more efficient and scalable data quality management strategy.
Developing domains creates distinct areas of ownership and prioritization, which makes it easier for the data team to answer questions about the health of their data and run time-specific processes.
For example, the Backcountry team has one domain dedicated to all their Fivetran tables, while another “core domain” is made up of the key assets the business needs to make decisions. Processes built around the core domain run every morning, so Javier can keep a close eye on those critical pipelines.
They also segment notifications based on domain ownership within their own team. “This way, we split notifications and don’t overflow the team with a lot of work,” says Javier. “We divide and conquer, because we are a small team.”
Migrate data from legacy systems with confidence in the integrity of the data
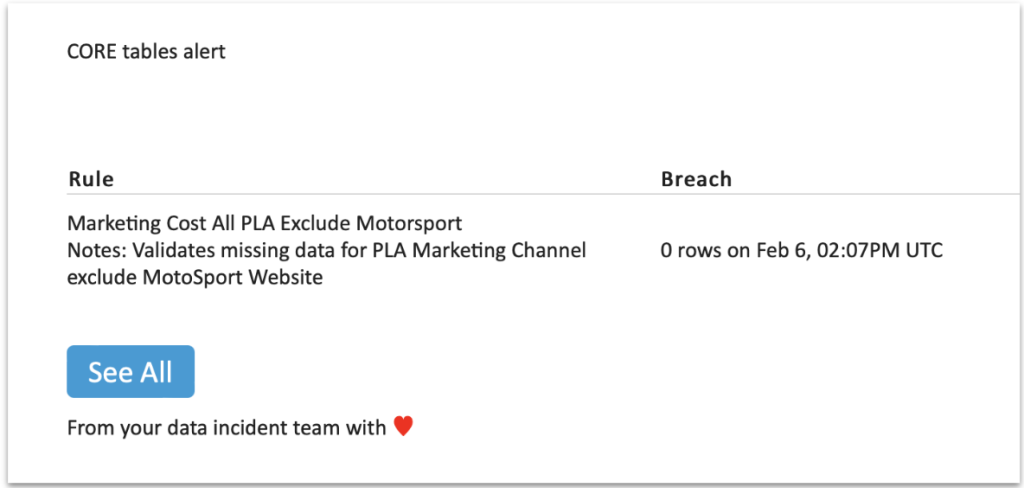
As the team adopted their modern data stack, they were able to rely on Monte Carlo to instill confidence in the integrity of all the data they needed to migrate. They were able to plan migrations with minimal impact and downtime, thanks to data lineage that made it easy to see upstream and downstream dependencies.
And if any data transfers were delayed, custom monitors could easily detect it before any business impact was felt.
Field-level lineage extending beyond what BigQuery offers
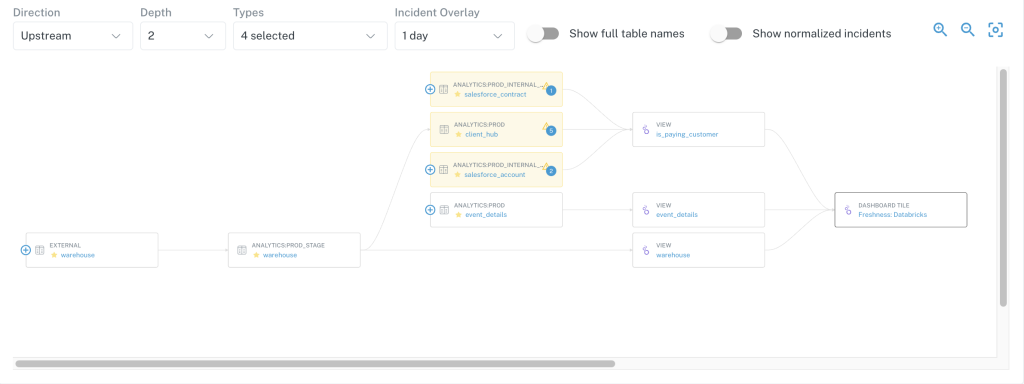
The Backcountry team was already using lineage provided within BigQuery, but found that Monte Carlo’s end-to-end lineage was more granular, comprehensive, and helpful.
That’s because BigQuery lineage provides information about data within BigQuery: where tables are, where tables end, and which SQL queries are applying to specific tables. But, according to Javier, “No one is using the tables within the data warehouse as their principal data source. They use Looker to consume the data.”
With Monte Carlo, the team gets end-to-end lineage, from the data source to the final report. As a lean team, that efficiency makes a significant impact on productivity. Rather than taking up other team members’ time to understand dependencies, everyone on the data team can get their own answers using Monte Carlo’s lineage.
“Using the lineage we can see, for example, how modifying a certain table will impact the business and where we need to be careful,” says Javier. “Now a developer can sit down, review a table, review a requirement, and check where data is coming from and where it goes without having to call other members of the team.”
The eventual impact of this end-to-end lineage is a better product for the customer.
“At the end of the day, what dashboard or notification that faces the customer are we impacting?” says Javier. “We don’t know until we get to the Monte Carlo lineage. For us, that is super important.”
The outcome: reduced time-to-detection by 30% or more
Ultimately, Monte Carlo delivered double-digit reductions in both time-to-detection (30-35%) and time-to-resolution (20%) for the Backcountry team.
By using a proactive approach to scaling data trust with observability, the data team learns about outages and fixes them sooner — often before the potential impact is felt by any stakeholders. That leads to more trust across the organization.
“Trust takes years to build, seconds to break, and forever to repair,” said Prasad. “It’s very important that we have that adherence of trust for our stakeholders, for our customers, in terms of the work that we do.”
The small-but-mighty Backcountry data team also reports seeing 30% higher efficiency levels across their team, and Prasad estimates they’ve saved the equivalent of one full-time data engineer’s time thanks to Monte Carlo.
“This team has done a lot of hard work in getting off the legacy stack, building those data pipelines, and having a very performant data structure set up as a part of the modern data stack process,” said Prasad. “So we wanted to do everything within ourselves to ensure that our consumers are guaranteed a high level of data accuracy, and that we provision quality data for our data consumers.”
The future of data at Backcountry
Looking ahead, Prasad predicts that 2023 will be an “interesting year” for his team. They’re planning to explore new ways to use data to elevate the customer experience, operationalize efficiency, and support business partners across the organization.
Additionally, they plan to further scale data observability and hone in on the predictive analytics capabilities within the GCP stack. While Prasad believes his team is already doing a lot of awesome work, he knows they could do even more by taking advantage of the newest features and expanding capabilities around AI.
The data team’s ever-present goal is to enable their business partners to understand what’s happening with their data, and how they can use it to make better decisions and create better experiences. Monte Carlo makes that possible.
“We gain the ability to communicate to the users correctly to avoid confusion and trust issues,” said Javier. “The people trust our data and ensure that the decision they’re making based on data is correct.”
Ready to increase trust in data across your organization?
Reach out to the Monte Carlo team to learn how observability can lead to fewer incidents, faster resolutions, and more data-driven decisions.
Read more posts.