Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Kolibri Games’ 5-Year Journey to Building a Data Mesh


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Berlin-based Kolibri Games has had a wild ride, rocketing from a student housing-based startup in 2016 to a headline-making acquisition by Ubisoft in 2020.
While a lot has changed in five years, one thing has always remained the same: the company’s commitment to building an insights-driven culture. With a new release almost every week, their mobile games are constantly changing and producing enormous amounts of data—handling 100 million events per day across 40 different event types, some with hundreds of triggers.
Along the way, the company’s data organization grew from a team of one marketing analyst to 10+ engineers, analysts, and scientists responsible for ensuring that their data operations are reliable, scalable, and self-serve. To power this explosive growth, the team is building a data mesh architecture backed by a data-driven culture that would turn thousands of more mature companies green with envy.
Recently, we sat down with the company’s Head of Data Engineering, António Fitas, to discuss the Kolibri Games data story, sharing how sharing how their data organization evolved at every step, including what tech they used, which team members they hired, and the data challenges they faced.
Their story is a fascinating one and serves as a great resource for those getting started on their data mesh journey. Let’s dive right in.
2016: First Data Needs
In 2016, the Kolibri Games founders started building a game together out of their student apartments at the Karlsuhe Institute of Technology in Germany. They achieved early success with their first mobile game, Idle Miner Tycoon, and the founders established some basic goals and objectives related to data.
Data Goals and Objectives
Establish basic business reporting to determine whether the game was working properly, and whether the company was making any money, by:
- Reporting in-app purchase revenue
- Reporting ad revenue
- Reporting game specific KPIs
- Reporting crashes and bugs
Data Team and Tech Stack
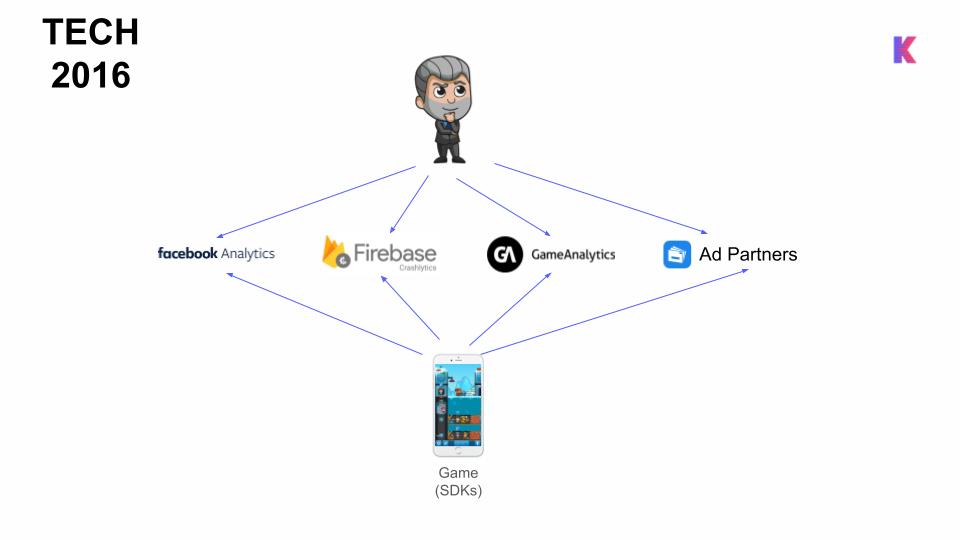
As a lean start-up, the founders relied entirely on third-party tools, including:
- Facebook Analytics
- Ad partners
- Firebase (to help fix app crashes and bugs)
- Game Analytics (for in-game KPIs, such as retention)
Data Challenges
- Scattered analytics across different tools
- No transparency about how KPIs were calculated
- Reporting inconsistencies between different tools
- Tech problems due to SDK integrations
- Tech limitations, such as digging deeper into metrics and lack of flexibility
“This approach was far from perfect, but these weren’t the first things we aimed to tackle,” said António. “We were lucky that we got a lot of players in the game coming organically, but we wanted to get more. For that, we wanted to ramp up our marketing and user acquisition operations — with data.”
2017: Pursuing Performance Marketing
As Idle Miner Tycoon grew in popularity, so did the team required to run the company—moving out of the student apartments into a proper office in Karlsruhe. And as the organization focused on acquiring new customers, the team set up data capabilities to measure and improve performance marketing.
Data Goals and Objectives
Ramp up performance marketing to get more users into the game while identifying which campaigns were profitable by:
- Calculating return on ad spend (ROAS) for campaigns
- Creating simple user lifetime value (LTV) prediction
- Building up paid ad bidding script to optimize campaign performance
Data Team

No data hires yet—a marketing manager was in charge of performance marketing.
Data Tech Stack
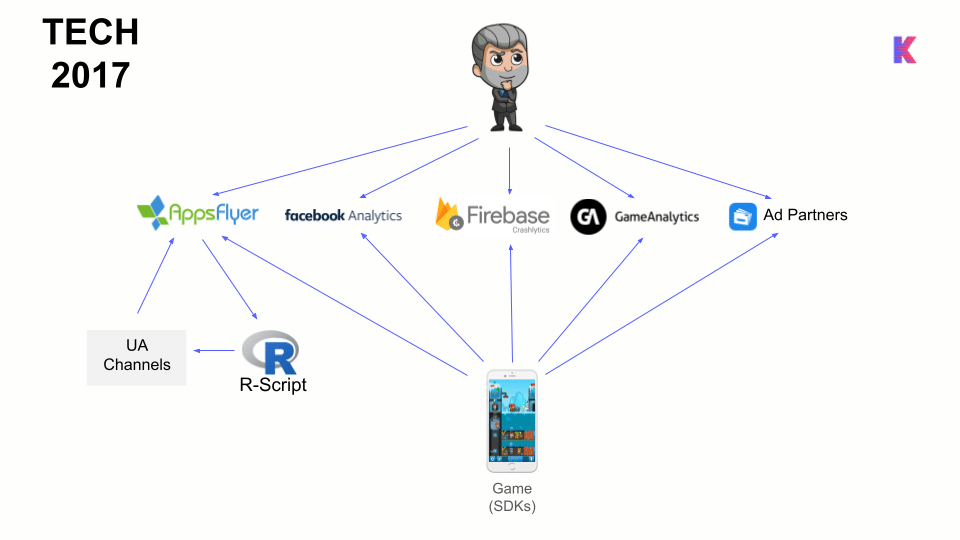
To gain insight into ROAS and LTV, the team added a third-party mobile measurement partner (MMP) tool, AppsFlyer, to their arsenal. This tool helped the marketing manager know which user acquisition campaigns were performing well and how much they cost, as well as how much revenue the newly acquired players were generating. AppsFlyer also informed the scripts that were running locally to optimize bid management operations.
Data Challenges
- Lack of transparency
- Error-prone
- No version control
- Data even more scattered
“We were basically blindfolded around those operations,” said António. “We didn’t have any version control or engineering best practices around the code that we were running for setting our bids.”
Still, Kolibri Games ended its second year with over $10M Euros in annual revenue. To get to the next level, it was time to invest in some improvements.
2018: Professionalize and Centralize
In its third year, the young company moved to Berlin, hired more developers and designers—and António, who joined just in time for a splashy celebration of 50 million downloads. Together with another data engineer and the marketing team, a professional data organization began to take shape.
Data Goals and Objectives
Centralize data and professionalize performance marketing by creating one tool to gather all information, provide transparency, and enable deeper dives into the data by:
- Investing in a proprietary own solution to centralize data
- Collecting raw data
- Building up a central data warehouse
- Setting up dashboards
Data Team
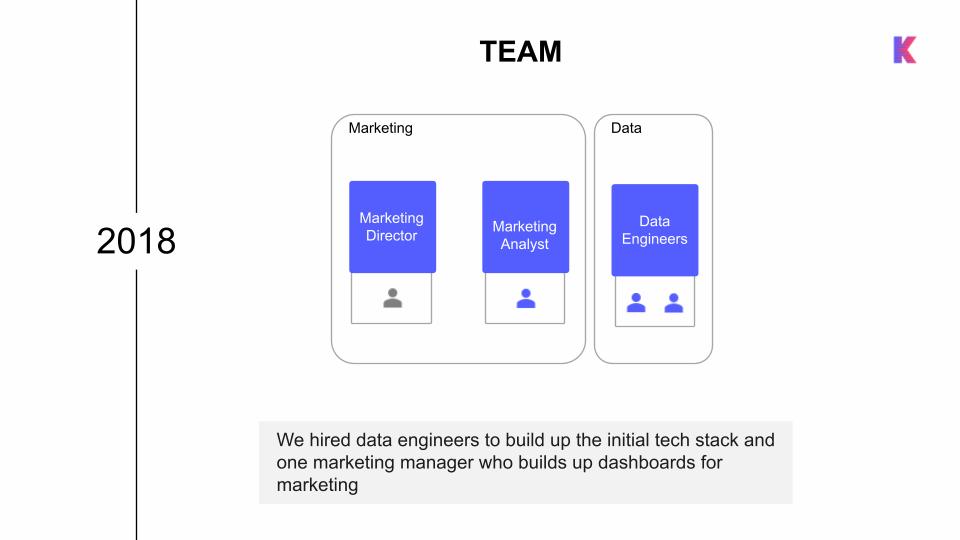
António and one additional data engineer worked to build up the initial tech stack, while a marketing analyst focused on building dashboards to enable performance marketing.
Data Tech Stack
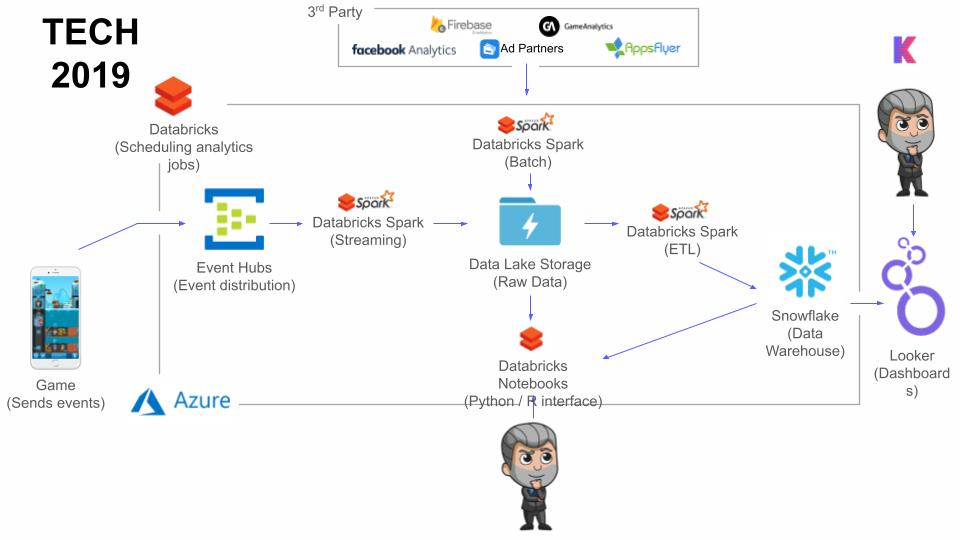
As António and his team built the first iteration of their data platform, they used Azure for nearly all of their services. They built event telemetry that generated data points for specific events or actions in a game, set up batch jobs to integrate data from APIs into their data lake, and made their first tech switch: migrating from Power BI to Looker to gain another layer of data manipulation and out-of-the-box features like version control.
- Data Factory (Azure)
- Event Hubs (Azure)
- Stream Analytics (Azure)
- Data Lake Analytics (Azure)
- Power BI, then Looker
- SQL database
Data Challenges
- Query performance
- Stability and reliability
- Keeping the system alive
“Our SQL database was becoming a limitation,” said António. “The jobs that were integrating the data were writing the data at the same time that our dashboards were running, or that an analyst was doing an ad hoc query—and basically, the whole service started to become very unpredictable and very slow. And we started seeing that some of our jobs were failing a lot, and we had limited alerting or monitoring. We decided we wanted to get data-oriented and start addressing some of the problems that we had.”
2019: Getting Data Oriented
With another successful game launch, a rebrand, and global recognition under its belt, Kolibri Games entered 2019 poised for even greater growth. The company hit the twin milestones of 100 million downloads and 100 employees in July. With more users and more products came more raw data, and António and his team knew they were just scratching the surface of how data could drive the company forward.
Data Goals and Objectives
Creating insights for games by understanding player behaviors, conducting experiments backed by data, and maturing the data tech stack by:
- Building a monetization dashboard to show how much the company was earning with offers, shops, and ads
- Building progression and engagement dashboards to understand how players were interacting with the games (such as when they were dropping off and how they interacted with certain features)
- Running A/B tests
- Increasing performance of warehouse and maintainability of data pipelines
Data Team
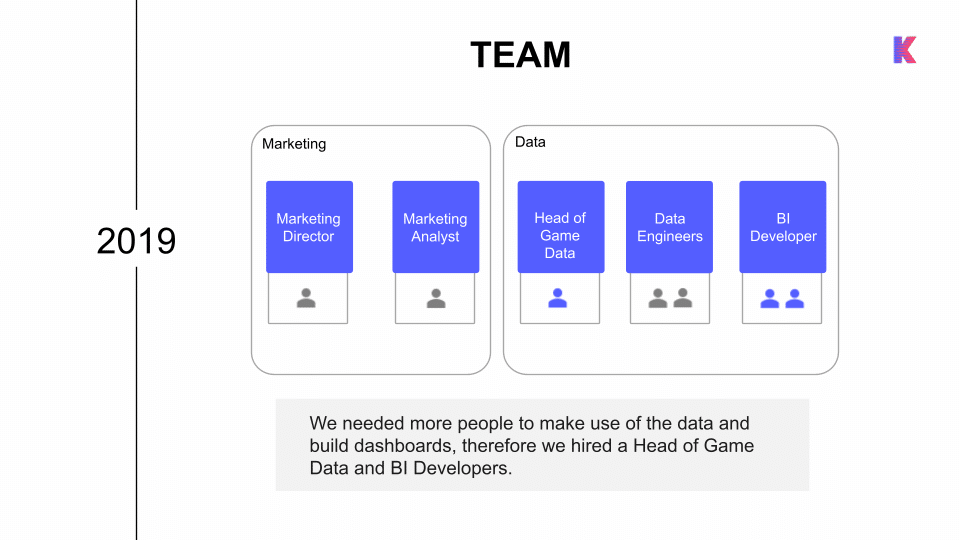
António knew they needed more people to make their massive amounts of data useful. They added a Head of Game Data and two BI developers to the data platform team. The data engineers worked closely with infrastructure—maintaining systems, integrating new tools, and maintaining streaming use cases—while building frameworks for BI developers to work with data integration, data modeling, and database visualization.
Data Tech Stack
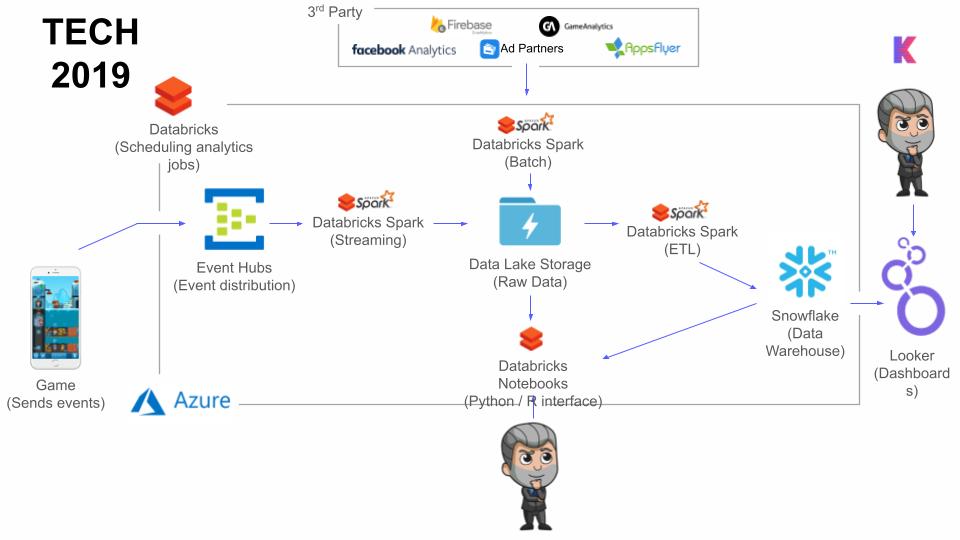
The growing data team needed more flexibility and easier collaboration, so António replaced some Azure services with Databricks. They tried using Spark to leverage their data lake as their data warehouse (understand the key differences between the technologies in our article on data lake vs data warehouse), but found the people working on the platform preferred Python and SQL—and they didn’t see the performance they expected in Looker while using Spark. So, António and his team ended up replacing their SQL database with Snowflake, which became the main computation engine for all of their analytics.
Data Challenges
- A/B tests were difficult to set up, missing transparency, and had no way to dashboard or present
- No data-driven decisions were showing up in games
“Most of the decisions were still made out of intuition and community feedback,” said António. “We continued to generate even more data, but we knew that we could utilize it even more and build more use-cases around it.”
2020: Getting Data-Driven
In early 2020, Kolibri Games was acquired by French gaming giant Ubisoft. With more resources, António’s team continued to grow, layered machine learning capabilities into their platform, and became inspired by conversations about data mesh architecture and domain-specific data ownership. To start building a data-driven culture, they introduced data-specific service-level-agreements (SLAs) and focused on increasing self-serve access to data.
Data Goals, SLAs, and Objectives
Make decisions fully data-driven to unlock the full potential of the company’s games, specifically by including product managers to help track that:
- 90% of all decisions on Idle Miner Tycoon needed to be backed by data
- Time-to-insight needed to be less than 1 hour for 90% of questions
- 90% of all changes needed to be validated with analytics
To get there, the data platform team would:
- Improve A/B testing process to help make informed decisions about features and changes to be implemented
- Improve personalization by creating game configurations for segments of players
- Use predictive analytics to predict LTV and churn to adjust the game accordingly
- Enable people to answer data-related questions without having to consult a data analyst
Data Team
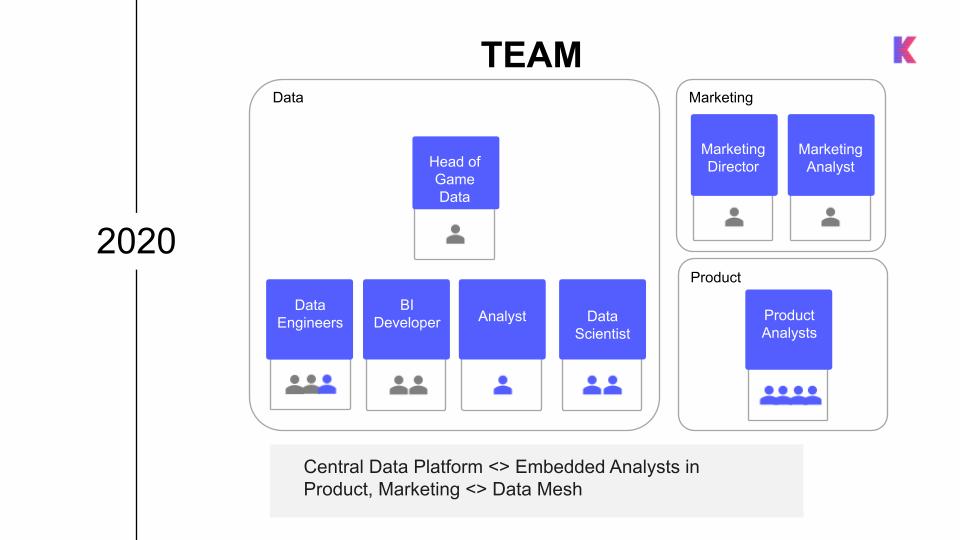
As the data organization focused on domain-specific data ownership, it made sense to have new analyst hires embedded directly into the Product team, working closely with product managers to understand needs and align priorities to reflect what the product actually needed. A third data engineer and two data scientists also joined the data platform team, working specifically on ML algorithms and A/B test data pipelines.
Data Tech Stack
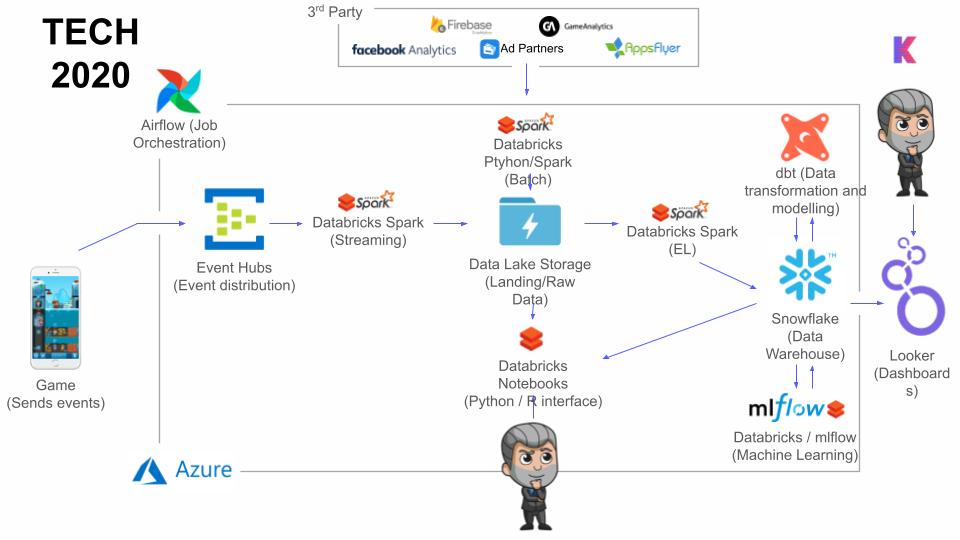
António’s team added data warehouse architecture into Snowflake, better defining where they were applying business logic. They also moved from doing ETL to ELT, doing cleaning and transformation directly in Snowflake. They combined that with dbt, a data transformation tool, to collaborate between everyone working on the platform, increasing transparency and visibility. The data engineering team also focused on abstracting data pipelines so product analysts could essentially own the design and definition of new data events together with a game development team. By following the defined guidelines set out by data engineers, they could now get that data into the warehouse and model the data without requiring a data engineer. António and his team also introduced Airflow as the main orchestration for data integrations, all dbt models, and data validations.
Data Challenges
- Data trust
- Software stability
- Scaling personalization
“I think it was really good work when we tried to measure, ‘Are we actually using data for our product development’?” said António. “Getting those KPIs around our questions and measuring those kinds of things really helped people to think more about it and push more for it. I think the exercise by itself proved to be really fruitful in terms of getting more people to think about data….But what happened at this point was that we were getting much more data, and many more new use-cases around data, and a lot of new models—but it was becoming difficult to monitor all of these and to make sure that things were correct.”
2021: Building a Data Mesh
As the current year unfolds, António and his team are focused on building data trust and reliability—which is crucial to their mission of achieving a data mesh architecture with domain-specific data ownership.
Data Goals and Objectives
Help the company scale with reliable data while building a data mesh architecture, increasing the speed of development and mitigation of incidents, decreasing the number of incidents, and increasing player personalization with further advanced analytics. António and his team plan to accomplish this by:
- Increasing testing capabilities
- Building common release and development process
- Implementing more monitoring and alerting
- Focusing on advanced analytics
- Collaborating to extend data platform capabilities around data monitoring and engineering best practices
- Building domain cross-functional teams
Data Team
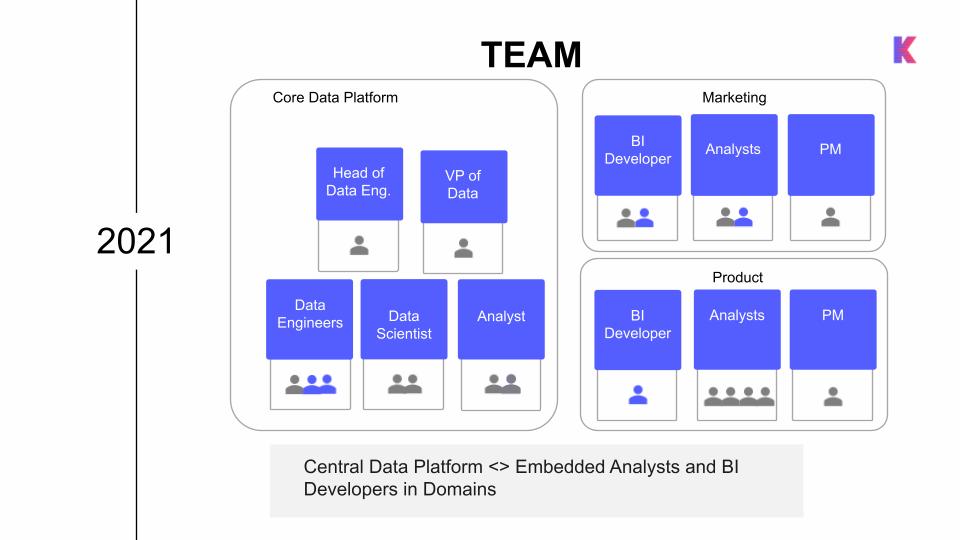
Inspired by the data mesh concept, the company plans to expand the domain teams embedded with product and marketing by adding project managers who will help define the work for their team and BI developers to help integrate new and maintain existing data sources. The central data platform team will continue to focus on building solutions, frameworks, maintaining infrastructure, and advanced analytics.
Data Tech Stack
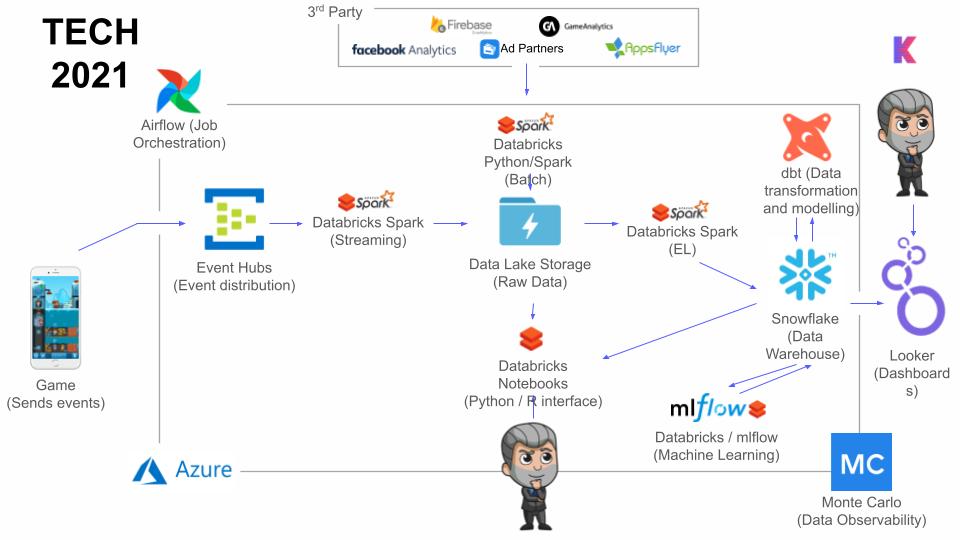
This year, the data team is striving to centralize development and release processes so that the data platform, marketing, and product teams all follow the same merge request and release into production processes.

Kolibri Games also added a new tool, Monte Carlo, for end-to-end, fully automated data observability and lineage. After trying to build their own custom solution for data monitoring, they realized it would require a full-time person to build a framework to extend it to different use cases and monitor all data assets. Monte Carlo helped solve this issue by monitoring the quality of all of the data in the data warehouse, and providing extra capabilities about understanding the end-to-end lineage of data to speed up troubleshooting and incident resolution.
5 Key Takeaways from a 5-Year Data Evolution
Building a data-driven company is a marathon—not a sprint.
For António, implementing a data mesh and achieving end-to-end data trust was a culmination of his team’s journey. Here are his key takeaways when it comes to setting up your data team (no matter its shape or size) up for success at each phase of its evolution.
- “Building your own data stack pays off, as it gives you all of these capabilities and enables you to be data-driven on your product development or working on your team.”
- “We’ve been through a lot of iterations over our data platform, so you have to choose and be able to understand when it’s the right time to change technology, for which right amount of data, for which process that you’re running.”
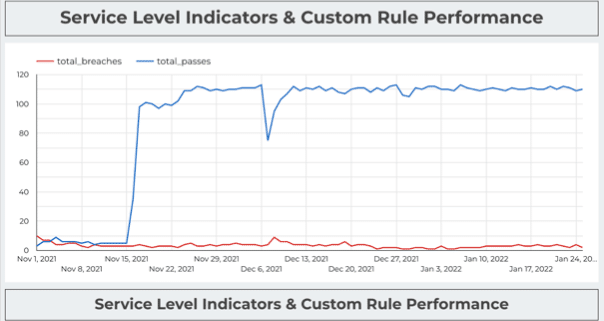
- “It’s very important to have a higher degree of data observability if you want to establish trust in your data. It’s important that you are able to understand when there is a problem, and that you’re able to indicate that easily.”
- “It’s important to get the basics right before advancing to more advanced data applications. In our case, we should have hired analysts earlier to make more use of the data.”
- “Establishing a data-driven culture is quite important and sometimes even more important than building the right tech stack.”
As more and more organizations adopt the data mesh and distributed architectures, the opportunity for innovation, efficiency, and scalability has never been greater. Still, it’s important to acknowledge that technology and process only get you so far when it comes to implementing a data mesh and building out a distributed data team. At the end of the day, becoming data-driven always starts— and ends— with culture.
Interested in learning how data observability facilitates a data mesh architecture? Reach out to Barr and the rest of the Monte Carlo team to learn more. And don’t forget to RSVP for IMPACT: The Data Observability Summit on November 3, 2021 to hear from Zhamak Dehghani, the founder of the data mesh, and other leading minds in data!
Special thanks to António and his team for sharing their story!
Implementing a data mesh? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.
![[VIDEO] How Resident Drives Data Observability with Monte Carlo](https://www.montecarlodata.com/wp-content/uploads/2021/03/Screen-Shot-2021-03-19-at-12.45.34-PM.png)