Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is Data Validity?

Michael Segner
Michael writes about data engineering, data quality, and data teams.
The annoying red notices you get when you sign up for something online saying things like “your password must contain at least one letter, one number, and one special character” are examples of data validity rules in action. They ensure compliance to expected conditions; in this case to make sure your password is hard to guess.
Data validity simply means how well does data meet certain criteria, often evolving from analysis of prior data as relationships and issues are revealed. Validity is one of the six dimensions of data quality.
Since the quality of insights you derive from data depends on the validity of that data, deep thought should go into your validation rules. This blog post will cover the most common quality and business rules, give examples of how to set them up, and you’ll learn how to automatically check for data validity with Monte Carlo.
Table of Contents
Data Validity Quality Rules
These rules are often developed after profiling the data and seeing where it breaks.
Valid values in a column
This is useful when you only want known values, such as two-letter country codes.
One way to check if a value is valid is to create a lookup table that contains a list of all valid country codes. You can then compare the country code in your column to the list of valid codes in the lookup table. Here’s an example:
SELECT COUNT(*) as num_invalid_codesFROM table_nameWHERE column_name IS NOT NULL AND column_name NOT IN ( SELECT code FROM iso_3166_1_alpha_2)If the count is 0, then all of the country codes in the column are valid according to ISO 3166-1 alpha-2. If the count is greater than 0, then there are one or more invalid codes in the column.
Column conforms to a specific format
When you have specific format requirements like telephone numbers or social security numbers, write a rule to check whether the data in that column conforms to or violates that format.
For example, to make sure all the data conforms to the phone number format (XXX) XXX-XXXX you can use this rule:
SELECT COUNT(*) as num_invalid_numbers
FROM table_name
WHERE column_name IS NOT NULL AND column_name NOT LIKE '([0-9]{3}) [0-9]{3}-[0-9]{4}'Note that the regular expression used in this query is just an example and you may need to modify it to match the format of phone numbers in your data.
Primary key integrity
You can also write a validity rule to test the integrity of the primary key column. Integrity just means the primary key has no duplicate data values.
SELECT COUNT(*)
FROM table_name
GROUP BY primary_key_column
HAVING COUNT(*) > 1;If this query returns 0, then there are no duplicate values in the primary key column and the primary key integrity is preserved.
Nulls in a column
You can use the COUNT function in combination with the IS NULL operator.
SELECT COUNT(*) as num_nulls
FROM table_name
WHERE column_name IS NULL;Besides nullability, other column property values that would be good to check are data type, length, precision, and scale.
Data Validity Business Rules
Business rules are another important aspect to consider when checking data validity. Sometimes, there might already be rules in place that apply, or new ones might be developed as you analyze prior data. Examples of validity rules created from business rules include:
Valid value combination
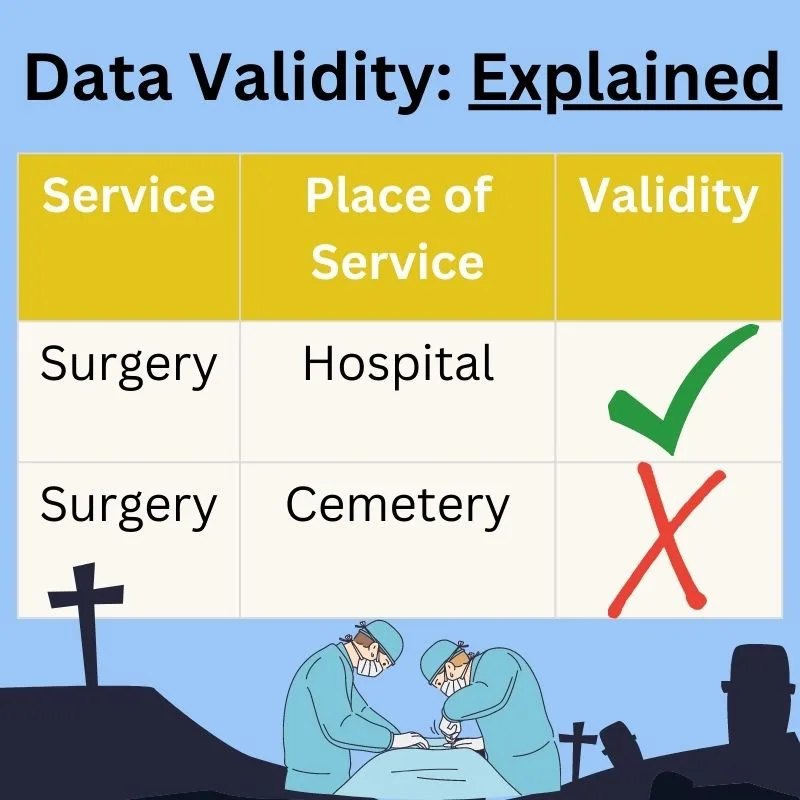
Valid value combinations are rules that specify which combinations of values are allowed or disallowed. For example, there could be a business rule that surgery is always performed in a hospital and if the data shows otherwise, the data is invalid.
| Type of Service | Place Of Service | Validity |
| Surgery | Hospital | Valid |
| Surgery | Ambulance | Invalid |
| Surgery | Hospital | Valid |
| Surgery | Morgue | Invalid |
Computational
This rule uses math to check whether multiple numerical columns are related to each other in the right way. This can be expressed as an equation (e.g., hourly pay rate multiplied by the number of hours worked must equal the gross pay amount) or a set (e.g., the total of all individual order amounts must equal the total order amount).
| Hourly Rate | Hours Worked | Gross Pay | Validity |
| $35.00 | 152 | $5,320 | Valid |
| $40.00 | 144 | $6,336 | Invalid |
| $42.00 | 150 | $6,300 | Valid |
Chronological
These rules validate time and duration relationships. A quick example is a flight seat change request can only be done prior to the flight departure time.
Here’s another example: the date/time of a newborn hearing screening should only be after the date/time of birth.
| Date of Birth | Date of Hearing Test | Validity |
| May 5 | Jun 2 | Valid |
| Jun 5 | Jul 1 | Valid |
| Aug 5 | Sep 4 | Valid |
| Sep 5 | Sep 1 | Invalid |
Conditional
These rules contain complex if…then…else logic that might include valid values combinations, computational and chronological conditions.
For example, a customer should not be charged a flight seat change fee if today’s date is after the flight departure date, if the customer’s fare class states seat changes are free, or if the reward status of the customer permits free seat changes.
Data validity is just one piece of a larger data quality picture
Validity rules test whether or not data meets known criteria, but what about testing for validity issues you can’t even anticipate?
To automatically monitor issues without thresholding or configuration, use a data observability platform like Monte Carlo that uses machine learning to determine what to monitor and the thresholds to set. It covers not just data validity, but many more data quality dimensions, too.
Learn more in our blog post Data Observability Tools: Data Engineering’s Next Frontier.
Interested in learning more about data observability? Set up a time to talk to us using the form below.
Our promise: we will show you the product.
Read more posts.