Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Data Engineer’s Guide to Backfilling Data


Michael Segner
Michael writes about data engineering, data quality, and data teams.
Every data engineer needs to have a data backfilling standard operating procedure (SOP) at the ready for the times when data needs to be updated en masse. Backfilling data is the process of filling in missing data from the past on a new system that didn’t exist before, or replacing old records with new records on an update.
Data backfilling typically occurs after a data anomaly or data quality incident has resulted in bad data entering the data warehouse. It’s a tedious process. The only thing worse than backfilling data is having to do it a second time after making a mistake.
To help you avoid this mess, we put together a SOP for backfilling data in data warehouses and other SaaS tools. Consider this your go-to backfilling data checklist.
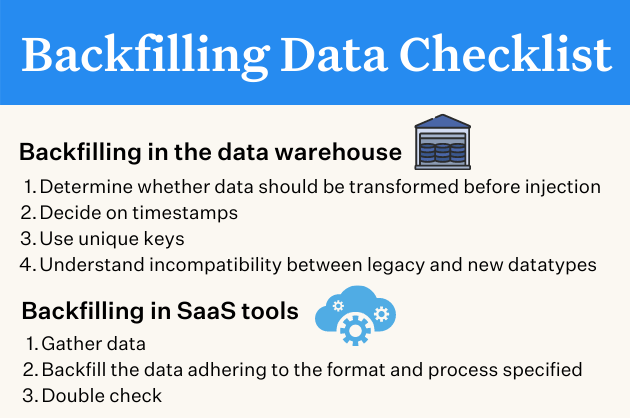
Tips for backfilling in data warehouses
A data warehouse is one of the most common places where backfilling of data happens. Before starting anything, a data engineer needs to understand the following:
Whether data should be transformed before injection
For example:
- How does historical data need to be transformed in order for it to be injected seamlessly into the newer system without breaking data integrity?
- Should the historical data be cleaned before injection?
- Should the historical data be inserted as raw data into an isolated schema, modified to be compatible with the new system, and attached to the new system?
Decide on timestamps
In order to maintain chronological order as well as for auditing purposes during data backfilling, timestamp columns play a vital role. It is of immense importance to check if timestamp columns are available on records that need to be backfilled.
If the timestamp column is missing, stakeholders need to decide on a timestamp per record or per batch of records based on information available at the time of decision-making. Once the decision is made, the data engineer needs to attach timestamps to all records to be backfilled.
Use unique keys
A common problem faced during backfilling of data is inserting duplicate records into the system. In order to prevent duplicate records from being inserted into the system, a unique key or a group of unique keys needs to be identified per table and these unique constraints should not be violated at all costs.
Understand incompatibility between legacy and new datatypes
Another common problem faced during backfilling data is the incompatibility between legacy and new datatypes. Sometimes in order to bypass errors, and to prevent stoppage while backfilling data, the code will automatically convert anything that is incompatible into strings.
The problem with this methodology is in order to write integer-based queries on these string-type columns they have to be converted into an integer or a float during runtime. This will decrease performance and convolute downstream analysis.
A data engineer – or a team of engineers – needs to meticulously go through all the columns on the legacy system and check them for compatibility. If a certain column is incompatible, they have to explicitly define how this column needs to be handled on the newer system.
Tips for backfilling data in SaaS tools
Most SaaS tools are introduced into a company’s ecosystem after the company has accumulated a lot of data. One of the first steps that come with integrating a SaaS tool is backfilling data.
Let’s say the director of marketing of a direct-to-consumer startup purchases a customer relationship management (CRM) tool and wants to send outbound emails to users who have not ordered their product in the last thirty days. Now, in order to execute this campaign:
- The director needs to find out who has not ordered in the last thirty days
- And, backfill this cohort into the new CRM
Gather data
To perform this task a data engineer is summoned. The data engineer goes to the clone of the production system and queries users who have not ordered anything in the last thirty days. Once the resultset is displayed, it is downloaded locally as a CSV. Most CRMs have a limit on importing data via the CSV method, resulting in data engineers preferring to use the native API to bulk insert larger record sets.
Backfill the data adhering to the format and process specified
In this particular use case backfilling consists of a two-step process:
- Creating a user record on the CRM system
- Attaching an event that tells the CRM that a user has not ordered anything in the last thirty days
The contemporary CDP platforms that populate data in CRMs trigger identify calls to create new user records. A data engineer should adhere to the same mechanism to create user records in the CRM system. Once the identify call is triggered, in order to add info such as no purchases made in the last thirty days, a track call needs to be invoked with appropriate properties.
Doublecheck
Once these two calls are invoked sequentially for all users that need to be backfilled into the CRM system, a cohort needs to be built inside the CRM to count the number of users that were inserted. If this count matches the CSV count, then the data engineer has achieved 100% success in backfilling.
Backfill less: How data observability can help you find and fix data errors
Backfilling data is just the first step in ensuring that data flows seamlessly and it’s a reactive process. The best way to backfill data is not to have to do it in the first place. In other words, by reducing the number of data incidents that require your team to go back and insert updated, correct data, the less data downtime you’ll experience.
Data observability platforms that natively integrate with all popular data warehouses, business intelligence tools, and notification engines can help data teams detect, resolve, and prevent data anomalies such as:
- Freshness: Monitors table inserts / updates and alerts if there is a delay in any of the tables
- Volume: Monitors the size of the table with each insert / update and alerts if anything out of the ordinary occurs
- Schema: Monitors schema for fields and tables and alerts if any unintended changes are made
- Data quality: Determines if there are any outliers in the data itself such as null, unique, zero, negative, minimum, maximum, white space, etc.
- Custom Rule-based Detection: Rules can be written in the form of SQL and if they are breached an alert is triggered.
Data observability can help reduce the amount of time your team spends backfilling data so it can spend more time on higher value tasks.
Interested in learning about how data observability can help you avoid backfilling data and beyond? Schedule a time to talk with one of our experts by filling out the form below!
Our promise: we will show you the product.
Read more posts.