Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is a Data Engineering Workflow? (And How to Set One Up)


Sara Gates
Sara is a content strategist and writer at Monte Carlo.
Over the last 20-ish years, the DevOps methodology has become the default approach to developing, securing, scaling, and maintaining software engineering. And in the last 5-ish years, DataOps has entered the scene to help data engineers scale data management.
Just like DevOps applies CI/CD (Continuous Integration and Continuous Deployment) practices to software development and operations, DataOps uses CI/CD principles and automation in the building, maintaining, and scaling of data products and pipelines.
This modern approach has been a game-changer for data engineering teams, whose processes have always been prone to breakages. Data pipelines are notoriously complex and vulnerable to failures, especially as companies have continued to ingest more and more data from internal and third-party sources. And as data teams and data consumers throughout the organization have grown in scale, the possibilities for human error to impact data reliability have increased, too.
That’s why the DataOps discipline of building and maintaining scalable data engineering workflows is now essential to modern teams. But what, exactly, is a data engineering workflow?
Simply put, a data engineering workflow is a series of operations followed in sequence by data engineering teams to scalably, repeatedly, and reliably execute DataOps tasks.
Without data engineering workflows that automate and streamline processes, an ad-hoc approach would wreak havoc on modern organizations. Manual data management would bring project progress to a crawl, and maintenance would become a nightmare. Building data platforms, pipelines, and products would become incredibly slow and inefficient. Teams throughout the organization would constantly be waiting on bottlenecks or broken pipelines to be addressed, and productivity and long-term data trust would plummet.
In other words, data engineering workflows make modern data management possible at scale.
So in this article, we’ll plumb the depths (data pipeline pun fully intended) of data engineering workflows: their basic steps, the differences between DevOps and DataOps workflows, how to set up a data engineering workflow, common roadblocks, and the must-have data engineering tools in the modern stack.
Let’s dive in.
Table of Contents
Basic steps for a data engineering workflow
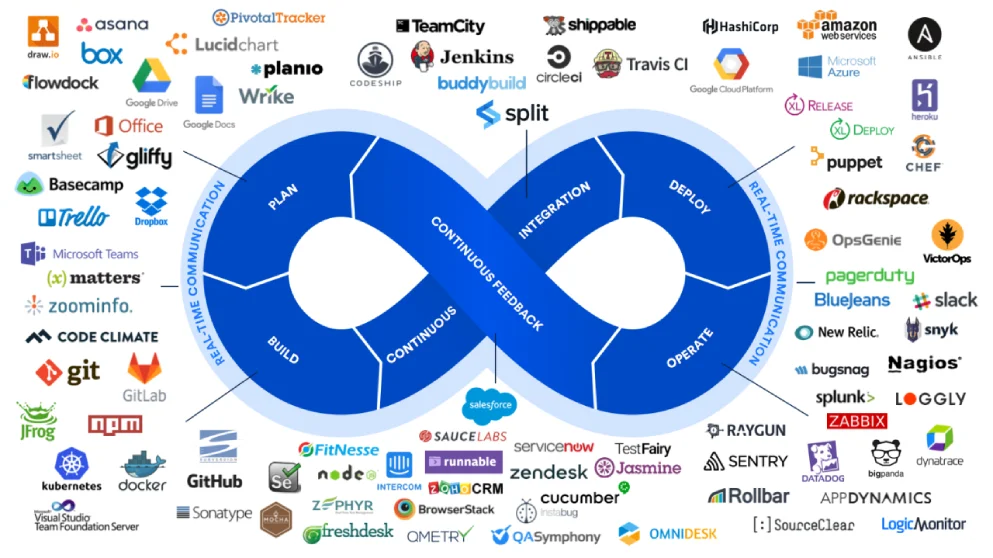
As we mentioned, the discipline of DevOps is a source of inspiration for building data engineering workflows. For example, DevOps typically incorporates:
- Development: writing and editing code
- Integration: combining new code with the existing central code base
- Testing: catching bugs, errors, or discrepancies to maintain the quality and stability of the software
- Monitoring: continually supervising systems and applications to ensure performance is tracked and issues are identified early
- Feedback: collecting valuable insights, reports, and user observations
- Deployment: releasing updated code into the live environment
- Operations: maintaining and managing the application
For DataOps, the key steps of data engineering workflows are:
- Plan: identifying the goals and requirements, then charting a roadmap for data pipeline or product development
- Code: writing scripts, creating models, and building pipelines
- Build: forming code into a data system that’s primed to process information
- Test: examining the model or pipeline’s ability to handle data accurately and reliably
- Release: approving and validating data engineering code for deployment
- Deploy: implementing the tested and validated data models or pipelines in production
- Operate: Continually ensuring systems run smoothly and troubleshooting any issues
- Observe: Monitoring data health and reliability throughout the entire lifecycle
These steps may vary based on each pipeline or product’s specific requirements, but generally speaking, this is what a modern data engineering workflow will look like.
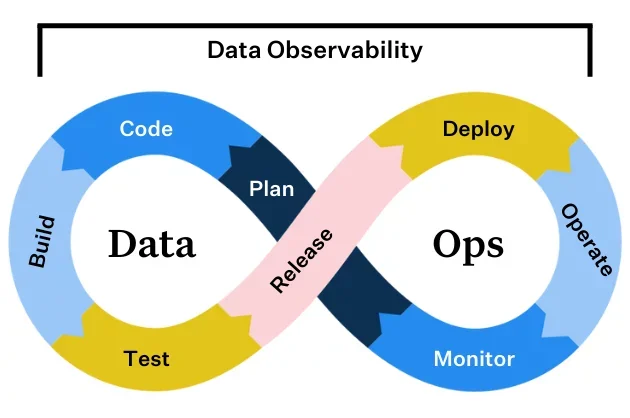
Data engineering workflow vs DevOps workflow
As you can see, there are a lot of similarities between DevOps and DataOps workflows — but each discipline involves its own unique processes.
Managing software applications is quite different than managing data products. Software engineers work with code, or source files that are executable and run tasks. Data engineers work with data, or files that code operates on. Since data engineers also work with code, data pipelines can be especially brittle — both the data itself, as well as the code that moves and transforms it, can break.
Additionally, the two disciplines have similar but nuanced goals. In the DevOps world, teams are focused on building usable and scalable software products. Within DataOps, teams are tasked with making accurate data consistently available to users. Similar to software engineers, data engineers may build data products that function like software products (especially under the data mesh architecture). But they are always responsible for ensuring data flows reliably and accurately throughout the entire organization. In that way, the scope of DataOps is different from (and broader than) the more distinct scope of DevOps.
Key considerations for a data engineering workflow
As you begin planning a data engineering workflow, there are a few considerations you’ll want to keep in mind.
Know your system, product, pipeline, or platform requirements
Defining the requirements for your system is essential to shaping your data engineering workflow. For example, if your data engineering team is building a real-time internal reporting platform, you’d want to know what metrics will be tracked, who will be using the tool, and how often reports need to be refreshed. The answers to these questions will influence workflow factors like dashboard design and query optimization techniques for faster data retrieval.
Understand your stakeholders
Knowing who will be interacting with your data products is the cornerstone of building successful workflows to surface relevant, reliable data. For instance, in the internal reporting example we just described, executive-level stakeholders would likely require quick access to high-level information, with the option to drill down when needed. On the other hand, data analysts probably want to see more granular detail with lots of flexibility to filter, correlate, and otherwise dive deep into the datasets. Understanding your stakeholders helps you plan and develop your data engineering workflows to meet the right needs.
Define your technological specifications and needs
Defining your data engineering project’s technological specs and needs will help you evaluate and choose the right tools to implement throughout your workflow. For instance, if you’re managing real-time analytics for large pay-per-click ad campaigns, you’ll likely want to use a robust streaming data processing platform. But if you’re building a report to track monthly sales, you won’t need to process streaming data and can use a simpler batch-processing tool to save resources.
It’s also important to understand what steps in your workflow can be automated, and what can’t. Automating processes like data cleaning or fine-tuning model development can save considerable time and effort. But certain tasks — like interpreting context or choosing which machine-learning algorithm to use — almost always require human judgment and domain expertise.
Knowing these technical specifications will help you plan and develop the simplest, most efficient data engineering workflow to get the job done.
Track KPIs and success metrics
For any data engineering workflow you build, you’ll want to know and track specific key performance indicators (KPIs) or success metrics. This practice will help you evaluate the efficacy of your data products and platforms.
While the specific KPIs you track will depend on the purpose of your projects, a common example is tracking data downtime. Knowing how frequently your data is partial, erroneous, or otherwise inaccurate will help you measure data quality and identify opportunities to improve the health of your pipelines.
Many data teams swear by setting and tracking data SLAs. These are metrics agreed upon by your data team and key stakeholders, and help everyone stay on the same page about the reliability and trustworthiness of your data. They also streamline communication and help data engineering teams know which issues take priority and must be addressed immediately when incidents do occur.
How to set up a data engineering workflow
As you set out to set up a data engineering workflow, follow a few simple steps to save headaches and improve your outcomes down the road.
Scope out your project and align on expectations with stakeholders
Similar to the act of setting SLAs, getting your stakeholders’ and data consumers’ alignment and buy-in at the outset of a data project will help identify potential miscommunication and avoid unnecessary re-work. Share your workflow plan with stakeholders and end consumers: even if they don’t understand all the technical details, they’ll be able to weigh in with any concerns before you spend valuable time building your pipelines.
Invest in Agile methodologies
A big part of the DevOps discipline is investing in the Agile approach, which promotes collaboration, experimentation and iteration, frequent releases, cross-functional ownership, and regular retrospectives. By applying Agile principles to DataOps, data teams can speed up production, capture feedback, and drive improvements to data platforms, pipelines, and products.
Leverage tools that facilitate CI/CD
As part of the Agile approach, data engineering workflows should utilize tools that help teams achieve CI/CD, or continuous integration, delivery, and deployment. For example, automated integration and testing facilitate CI/CD in data engineering workflows — whereas manual scripts and ad hoc integration from source to storage will quickly become a roadblock.
Roll out automated, end-to-end monitoring with data observability
Again, we can look to DevOps for inspiration in the landscape of observability. Tools like NewRelic and DataDog provide automated monitoring and alerting of software applications, letting engineers know when code breaks or applications become unavailable. Similarly, data observability delivers end-to-end visibility into data health — making sure data engineering teams are the first to know when data fails to meet requirements for freshness, quality, or volume, or experiences schema changes. Observability also provides automated data lineage, which accelerates troubleshooting and root cause analysis when things do go wrong.
Common data engineering workflow roadblocks
We’ve talked with hundreds of data teams over the last few years. And while no two data projects are exactly alike, there are some common roadblocks that continually threaten to derail data engineering workflows. Watch out for the following:
Attempting to automate the entire cycle end-to-end
Attempting to automate everything in one fell swoop can lead to unnecessary complexity, less manageability, and increased chances of a single error causing a total breakdown. Instead, focus on automating repeatable tasks that can be more easily controlled and debugged.
Failing to visualize the workflow in advance
If you don’t create a simple diagram of your workflow, you can easily miss problematic gaps or opportunities to simplify your architecture. Use a tool like Lucidchart, Mural, or just good old PowerPoint to visualize your workflow before it’s implemented.
Seeking human approval for each step in the workflow
Requiring manual intervention decreases the speed of your operation and increases the potential for human error. Instead, prioritize automating every step that can be reliably controlled by algorithms.
Adding complexity with multifaceted steps
Overcomplicating workflows with multifaceted steps makes errors harder to diagnose and rectify. Keep flows as simple as possible by limiting each step to a single purpose that is easy to test and fix.
Not sanitizing all parameters before they’re used in a workflow
When data moves ahead in a pipeline without cleansing parameters, irregularities can persist and potentially cause future issues. Maintain a “clean as you go” approach to minimize errors down the line. Sanitize all parameters before they’re used in a workflow to minimize errors.
Not testing for missing or null values
Failing to perform this crucial check leaves room for defective or incomplete data to propagate throughout your pipeline. Continual monitoring will help prevent downstream impacts on data quality.
Must-have tools in the data engineering workflow
Now that we’ve covered the many do’s and don’ts of data engineering workflows, let’s get into the fun part. These are the must-have tools and technology for your data engineering workflows:
- Code or model repository (GitHub, GitLab) provides version control by allowing data engineers to keep track of different iterations of their data processing scripts, ETL pipelines, or SQL queries. Teams also use Git to collaborate, perform code reviews, use branches to segregate work, and automate builds and tests through pipeline integrations.
- Integration tools (Fivetran, Matillion) help extract data from internal and external sources and load it into a data warehouse.
- Data warehouses/lakes/lakehouses (Redshift, BigQuery, Snowflake, Databricks) offer large-scale, optimized storage for structured or unstructured data, along with the ability to run complex analytical queries.
- Orchestration tools (Airflow, Prefect) allow data teams to schedule, monitor, and manage the flow of data between different tasks or steps, making sure everything happens in the right order and at the right time.
- Testing tools (Great Expectations, dbt) validate whether data meets specific, predefined quality standards.
- BI tools (Tableau, Looker, Sigma Computing) deliver reporting, insights, and visual analytics to data consumers via user-friendly interfaces.
- Data observability tools (Monte Carlo) provide complete visibility into data health, including automated monitoring and alerting and end-to-end lineage across the entire data lifecycle.
To learn more about assembling a modern data stack to support data engineering workflows, check out our guide “Build vs. Buy Your Data Stack”, predictions on the future of the data stack,
And keep in mind: all your hard work on building data pipelines and products will be for naught if you don’t have reliable data. So as your data stack matures, you’ll want to introduce data observability at the right time. Data observability ensures you can monitor data health, alert the right team members when something goes awry, and quickly analyze and resolve issues so they don’t persist downstream or repeat themselves in future projects.
When you’re ready to learn more about how data observability can keep your data reliable and trustworthy throughout your data stack, contact our team.
Our promise: we will show you the product.
Read more posts.