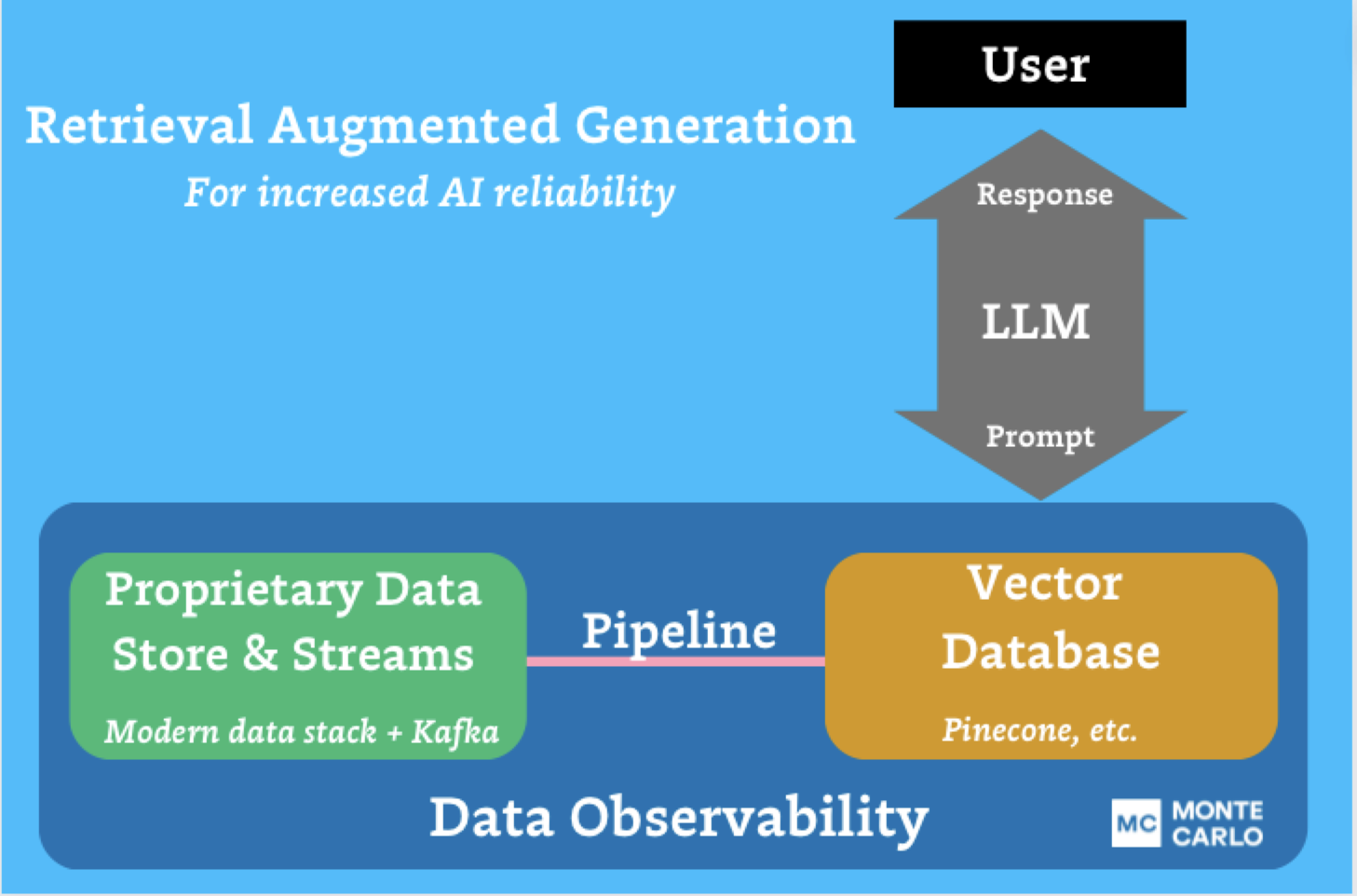
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Metadata is Useless — Unless You Have a Use Case


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Last week, I participated in a panel at the Coalesce conference, led by the dbt labs (creators of dbt), to discuss the role of metadata in the modern data stack. One of the points we discussed was: metadata is useless. In this blog post, I’ll explain why.
Over the last decade, data teams have become increasingly proficient at collecting large quantities of data. While this has the potential to drive digital innovation and more intelligent decision making, it has also inundated companies with data they don’t understand or can’t use.
All too often organizations hungering to become data-driven can’t see the forest for the trees: data without a clear application or use case is nothing more than a file in a database or a column in a spreadsheet.
In recent years, we’ve seen the rise of data: now, companies are collecting more and more data about their data, in other words, metadata. By and large, this enthusiasm around metadata is a huge win for the industry. ETL solutions like dbt make it easy to track and use metadata, while cloud providers make interoperability of metadata more seamless between data solutions in your stack.
Still, as we become more and more metadata-dependent, it’s important to remember not to repeat these same mistakes.
More metadata, more problems
Just as data without context is nothing more than a bunch of numbers, metadata by itself is useless — it’s just more information about other information. Collect it all you want, but without a practical use case, metadata is largely meaningless.
Take for example, lineage, a type of metadata that traces relationships between upstream and downstream dependencies in your data pipelines. While impressive (neon colors! nodes! sharp lines!), lineage without context is just eye candy, great for a demo with your executives — but, let’s be honest, not much else.

The value of lineage doesn’t come from the simple act of having it, but instead lies in its relevance to a particular use case or business application.
Where can lineage be actually useful? Aside from looking nice in a fancy demo or PowerPoint presentation, data lineage can be a powerful tool for understanding:
How to understand data changes that will impact consumers and determine the best course of action to resolve that use case
Say for example you want to make a change to a particular field. Without lineage, you’re likely making that change blindly — hoping there are no downstream repercussions (you: “fingers crossed that no downstream consumers are going to be surprised by this change!”).
By using field and table-level lineage, you can see which specific tables, reports, and most importantly — users consuming those assets — are going to be impacted by this change.
How to troubleshoot the root cause of an issue when data assets break
In another scenario, you may be paged in the middle of the night about a broken dashboard your team is supposed to present to execs the next morning. You need a quick way to understand what broke upstream to render your Tableau graphs completely useless.
But what exactly is the root cause of this problem? And which of the 100,000 tables you have in your data warehouse will you need to fix? With lineage, you can immediately identify the upstream assets contributing to this data downtime and pinpoint the root cause.
How to communicate the impact of broken data to consumers
And finally, let’s say data breaks (as it often does) — specifically, an ETL job was completed, but the data in this column is now 80% null — essentially, a silent failure. And now you need to highlight how this silent failure affects the users of this data.
How do you know who will be impacted and should be notified about this? Lineage provides a quick and easy way to communicate what happened and where so that you can keep stakeholders in the know while you resolve the issue.
At the end of the day, lineage and metadata have the potential to be immensely valuable to data teams and companies at large — but only when it’s applied directly to your business.

When captured holistically and in the context of business applications, metadata has the potential to serve as a force multiplier for your entire company. Image courtesy of Barr Moses.
At the end of the day, your metadata (including but not limited to lineage) should answer more than the basic “who, what, where, when, why?” about your data. It should enable your customers (be it internal or external) to be equipped with up-to-date and accurate answers to questions that relate back to the your customer’s pain points and use case, including:
- Does this data matter?
- What does this data represent?
- Is this data relevant and important to my stakeholders?
- Can I use this data in a secure and compliant way?
- Where does the answer to this question come from?
- Who is relying on this asset when I’m making a change to it?
- Can we trust this data?
Many data teams are trying to answer these questions through a variety of solutions, including APIs that hook into modeling and pipeline transformation tools, data catalogs, documentation, and lineage.
All four provide rich insights about your data, but they’re missing one critical piece: its application to your business.
Application is everything
Metadata without a use case is like an elephant riding a bicycle. Interesting and impressive, but not very useful (unless you’re running a circus).
The true power of metadata lies in where, when, and how we use it — specifically, how we apply it to a specific, timely problem we are trying to solve.
In addition to collecting metadata and building metadata solutions, data teams also need to ask themselves: what purpose is this metadata serving? How can I apply it to solve real and relevant customer pain points?
Personally, I couldn’t be more excited for the future of metadata. With the right approach, applied metadata can be a powerful tool for data observability, data governance, and data discovery, three critical components of having accurate, reliable, and trustworthy data that can move the needle for your organization.
Interested in learning more? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.