Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Rise of Empty Queries OR Why You Can’t Always Just Re-Run That Failed Job

Mei Tao
Product at Monte Carlo

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
When you set up a query to run in your data warehouse one of four things will happen:
- It runs successfully. Hooray, you have the data you need! The query is marked as successfully run.
- It fails. Boo! The failure could have been caused by timeout, missing fields referenced, permission issues or something else entirely. You reluctantly trudge along your root cause analysis journey.
- It skips. The query is part of a chain of code that has failed upstream. It sees the train wreck and slowly backs away. You mutter a curse and start troubleshooting.
- It runs successfully, but does nothing. We call these “empty queries” and they can be silent killers. This is because no updates are made, but no red flags are thrown either.
According to our data from the more than 5 million tables we monitor, these empty queries are the culprit behind about 17% of data freshness incidents. Let’s quickly dive into why empty queries happen and why they are so hard to detect.
Why Empty Queries Happen
Empty queries typically happen for one of two reasons.
The first possibility is that a data engineer has written some bad code. Maybe they are SELECTing only the fixed set of historical rows, and as a result newly added rows don’t show up. While your data team may have failproof code reviews, pull requests, and other processes in place, these things do happen.
In this scenario, the query successfully completes the silly task it’s been programmed to do, but the intended operation doesn’t take place.
The second, most common, reason empty queries happen is that a freshness or volume issue occurred on a table upstream. The query went to execute on data that never arrived. The reason, in true bad data fashion, could be one of a million possibilities. An Airflow job got grounded, a Fivetran sync sunk, a JOIN further upstream went RIGHT instead of LEFT.
In either of these two scenarios there is a data consumer somewhere downstream composing a passive aggressive email with the phrase, “once again,” and the data engineer is none the wiser.
Why Empty Queries Are Hard To Troubleshoot
Now you, the well-meaning data engineer, have received the passive aggressive email and need to figure out what’s going on. As we’ve covered previously, data issues occur at three levels: system, code, and data.
However, when you feel a drop of water outside you look up to see if there are dark clouds. When there is a data freshness issue, you check Airflow for failed jobs before tabbing open and checking Fivetran and dbt. You may even have proactive alerts set up.
You won’t notice any failures on the specific table in question, but you may notice an error (let’s say a failed Airflow job) did occur in the relevant time frame. As a result of tribal knowledge or automated data lineage, you may even recognize the table is upstream from the one in question.
Time to rerun the job–the data engineer’s equivalent to IT asking you to turn your computer on and off again. Except this time the data still isn’t refreshed because unbeknownst to you the query already ran downstream and it’s not set to run again for another 24 hours.
It’s time to pour a cup of coffee and wade through another tedious and disjoined root cause analysis. Perhaps after scanning blocks of code through multiple layers of tables you finally spot the table. Or maybe you don’t. Either way it’s time wasted.
Our survey shows the average data professional spends 40% of their time on data quality related tasks. Increasing efficiency can help ensure that time is better spent building data products that add value to the business.
How Monte Carlo Handles Empty Queries
It’s always best to attack data incident resolution from multiple perspectives, which is exactly what our data observability platform does. With integrations with dbt and Airflow any failed job is going to send an alert in Slack or your notification channel of choice.
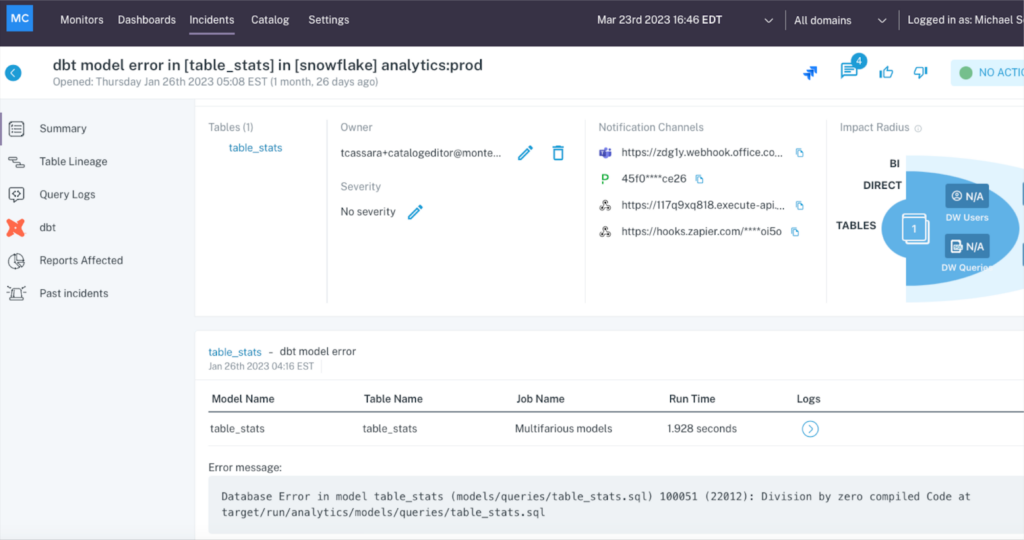
You will be able to see the incident within the context of end-to-end data lineage. With a quick glance you can ensure there are no tables with incidents upstream that may be the real root cause, and you’ll also be able to see the blast radius including all downstream tables, dashboards, and users.
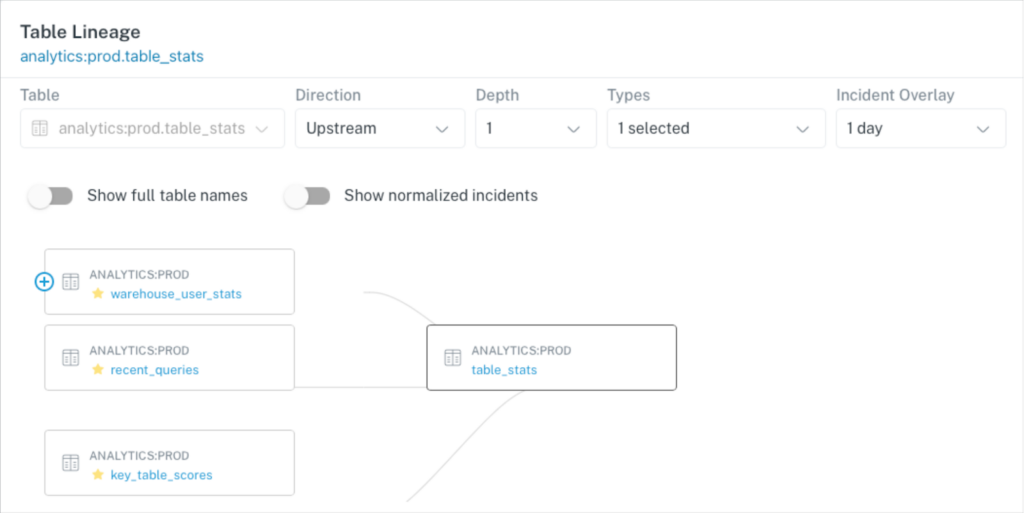
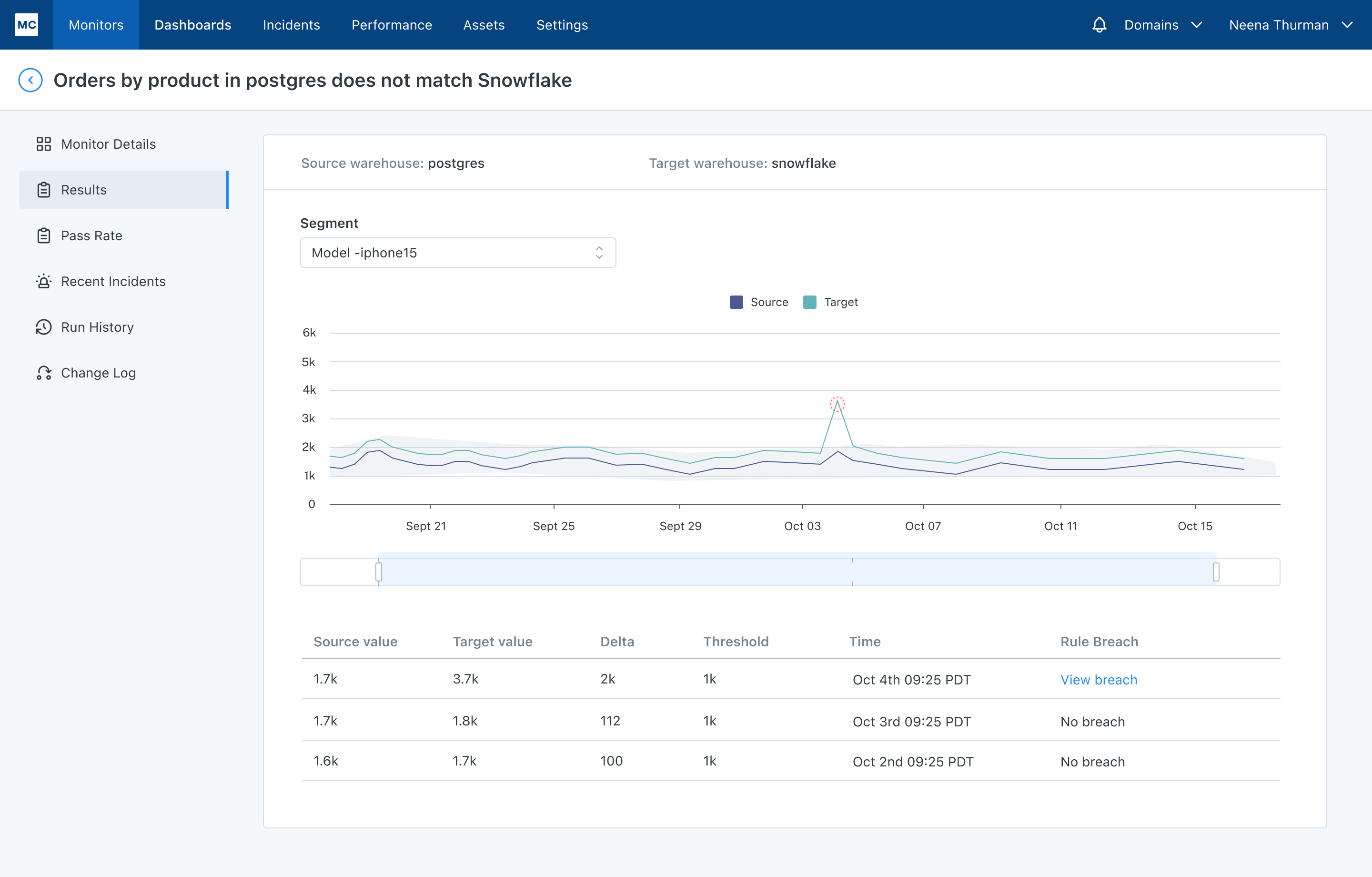
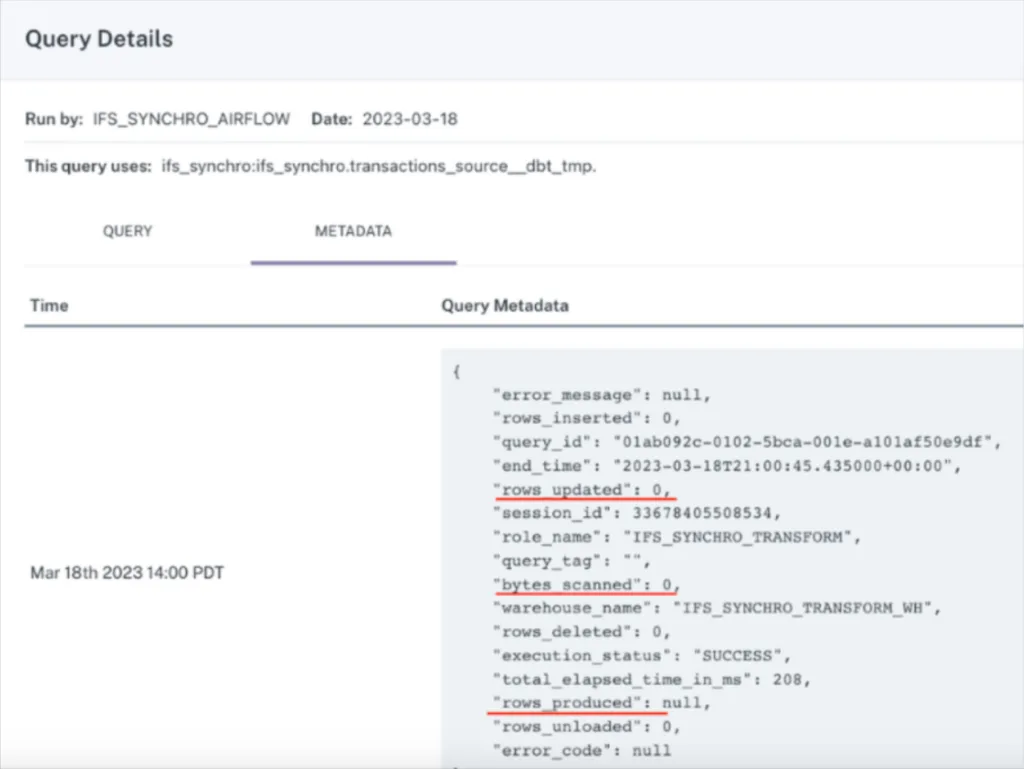
Our query status insights feature combs through data warehouse query logs and will detect there was a query that didn’t add, delete, or update any rows at the time of the incident and flag it as an empty query. (We can also detect the correlation between how and when a query changes and the resulting volume or freshness anomaly if you’re wondering).
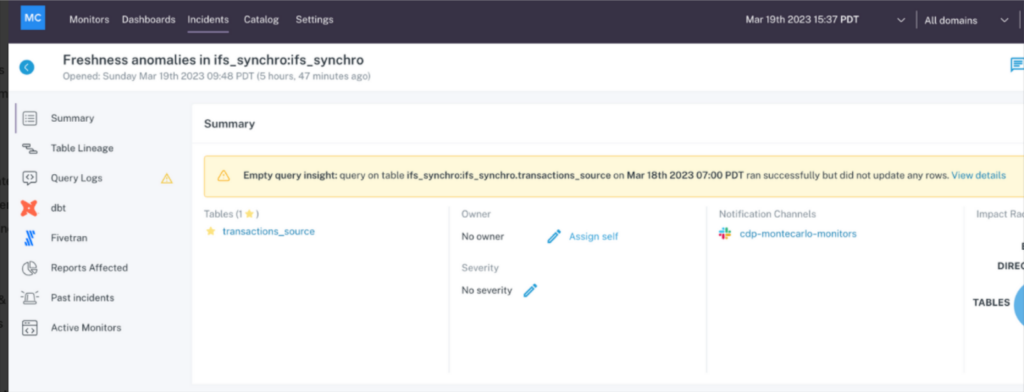
You make the fix and your root cause analysis no longer resembles a root canal.
Automate Detection and Accelerate Resolution
This is just a small example of how data observability can improve data quality and make data engineers more efficient.
Solutions like Monte Carlo will leverage machine learning to automatically detect all sorts of data freshness and volume incidents as well as schema changes and quality issues within the data itself. In every case, data lineage will help shine light on the problem and in many cases there will be a high correlation insight like empty queries to go along with it.
If this sounds like something that can be helpful to your team, select a time to speak with us by filling out the form below to get a demo. Until then, here’s to wishing you no data downtime!
Our promise: we will show you the product.
Read more posts.