Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage A New Horizon for Data Reliability With Monte Carlo and Snowflake


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.

Ravi Kumar
Ravi currently serves as Senior Partner Sales Engineer for Powered By Snowflake and Cybersecurity, Security, Observability and Governance Partners at Snowflake.
It’s one thing to get your data into a modern data cloud. It’s another thing to be able to effectively manage, govern and observe it over the long haul.
Snowflake recently announced the launch of Snowflake Horizon—a unified collection of compliance, security, privacy, interoperability, and access capabilities—that make it easy for organizations to govern and take action on their data and apps across clouds, teams, partners, and customers.
Monte Carlo is thrilled to be part of the Snowflake Horizon partner ecosystem as we leverage many of the pre-built features Snowflake provides in order to help organizations reduce their data downtime and improve data quality at scale.
Legacy approaches like unit testing aren’t sufficient for ensuring data reliability across modern data platforms. You cannot anticipate all the ways data will break, and if you could it’s simply not suited for this type of scale.
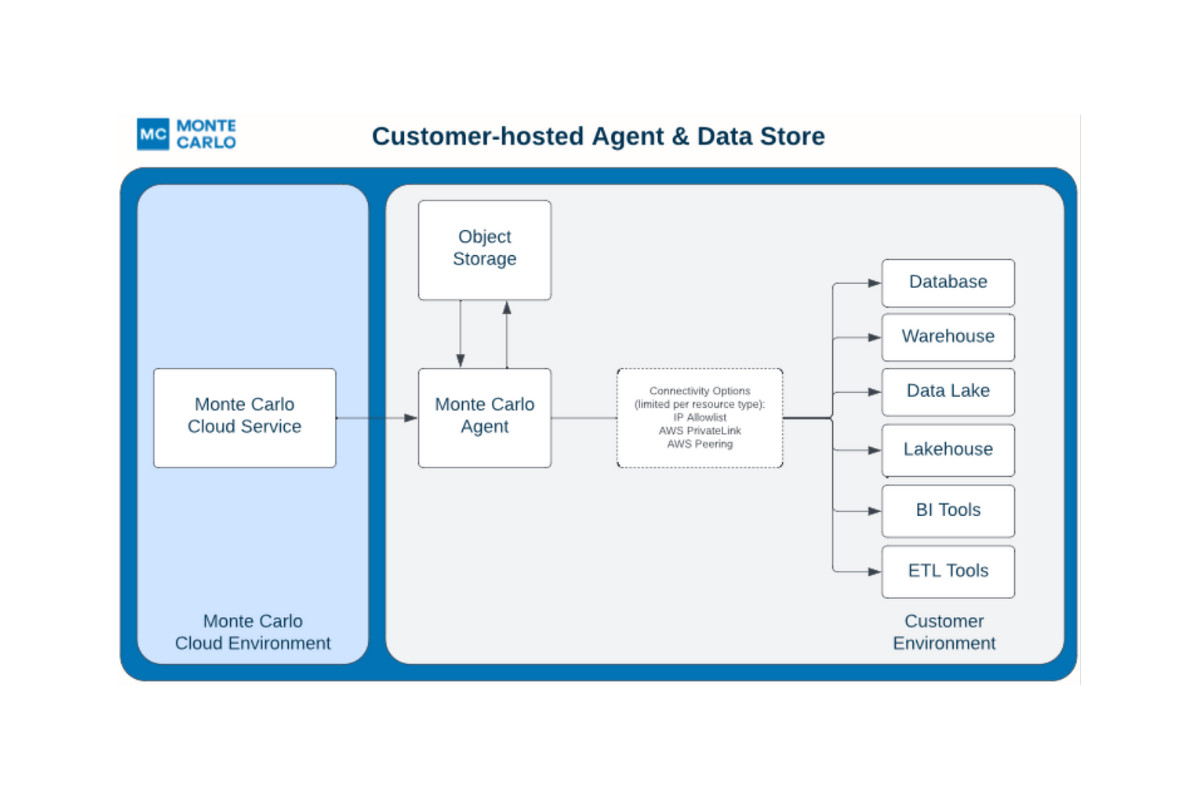
Snowflake understands the importance of scaling data quality and provides some data quality metrics via tables and APIs with its native Data Quality Monitoring and Compliance feature. Monte Carlo supports and extends this native feature by offering Snowflake users a data observability solution to detect, triage, and resolve their data quality issues.
This in turn enables organizations to:
- Mitigate risk: Decisions and actions taken on bad data cause negative reputational, competitive, and financial outcomes.
- Increase data adoption and trust: By catching incidents first, data teams transition from part of the problem to part of the solution. Instead of a reactive scramble, it’s a proactive service that leads to higher levels of trust and adoption.
- Reduce time spent on data quality: Data observability makes data teams more efficient by reducing the amount of time data teams need to scale their data quality monitoring as well as resolving incidents.
Let’s take a deeper look at how Snowflake and Monte Carlo work together.
Improve coverage with automated anomaly detection
Monte Carlo uses machine learning detectors to monitor the health of data pipelines across dimensions like:
- Data freshness: Did the data arrive when we expected?
- Volume: Are there too many or too few rows?
- Schema: Did the organization of the dataset change in a way that will break other data operations downstream?
By leveraging the metadata made available in Snowflake, Monte Carlo can automatically detect freshness and volume anomalies within days of deployment, without any additional configuration. Trying to accomplish this goal by querying the data directly (an approach taken by some data quality tools or custom built ML models) would be much more compute intensive and costly to the user.
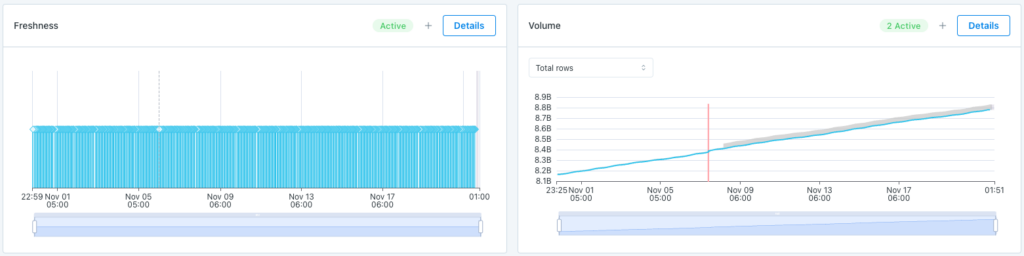
Freshness and volume monitors in Monte Carlo.
To drill down a level further, for example, we leverage Snowflake information_schema to detect and trigger alerts for schema changes. This is critical for many reasons, but a common scenario we see is that a third-party or internal application will change the format of the data. If let’s say a column is renamed, but a downstream query has the previous name in its code, that query will now fail and incidents will cascade downstream.
Information_schema also comes into play when Monte Carlo users create a volume rule with a static threshold. These volume rules actually trigger a query against the relevant information_schema table, which allows our customers to create volume rules that run more frequently than every hour.
Even though we don’t leverage Snowflake metadata to do it, it’s important to point out that Monte Carlo also uses machine learning to monitor data quality directly for key metrics such as min, max, unique%, NULL rate, and dozens more.
Gain powerful context for triaging incidents
Data quality insights are only as useful as they are actionable. And the key to making insights actionable is providing the right context.
Snowflake object tagging enables data teams to easily organize and classify their data objects with helpful context like ownership and priority level. And with Monte Carlo’s deep Snowflake integration, those object tags can also be automatically imported and applied to your Monte Carlo Access View as well.
By integrating Snowflake tags with Monte Carlo’s data observability, data teams can quickly understand the importance of a data quality issue and take quick action to triage, manage, and resolve the incident effectively. Did an alert pop up for a critical Gold table? Route it to fix ASAP. Did one of the 58 dashboards tagged for marketing stop loading fresh data? Let the marketing team know you’ve got the alert and you’re all over it.
To import tags from Snowflake, Monte Carlo collects the tags via the metadata in the from the [SNOWFLAKE.ACCOUNT_USAGE.TAG_REFERENCES] table in Snowflake.
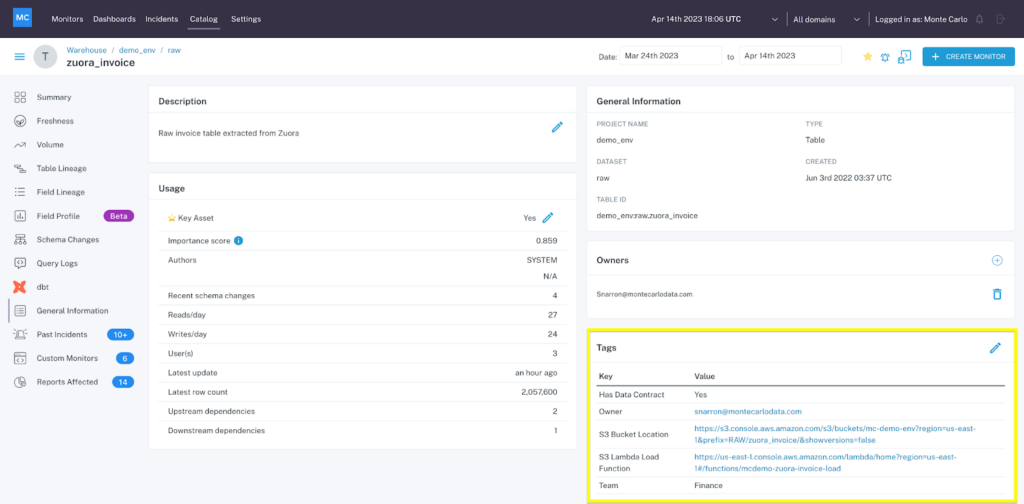
Monte Carlo not only surfaces this metadata from Snowflake but from across your modern data stack. So now you have your Snowflake, dbt, and other system tags in one place.
Resolve issues faster with field-level lineage and query insights
Reducing time to detection is important, but it’s only half of the data downtime equation. The other half? Reducing the time to identifying and resolving the root cause.
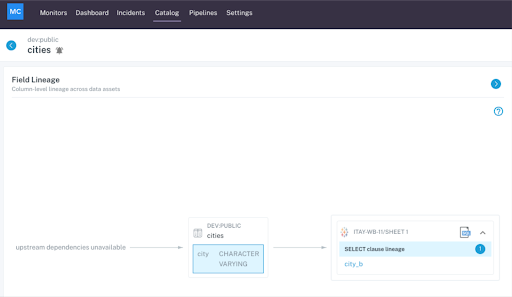
Snowflake enables a number of Monte Carlo’s most powerful resolution features as a result of how it stores each query in an accessible central log. Monte Carlo parses those logs to deliver automated data lineage.
This is a visual representation of the data as it moves through your pipelines. When data inevitably breaks, you can quickly see at a glance where it came from, where it broke, who’s responsible, and every asset—and stakeholder—that’s being impacted in real-time.
In an instant, you’ll be able to see your incident in its end-to-end context to determine at-a-glance if there are any incidents upstream that might be the true culprit. Your field-level lineage will also give you a “blast radius” of your data incidents so you know just how far the problem goes, who needs to be informed—and how much fallout to expect if it’s not contained.
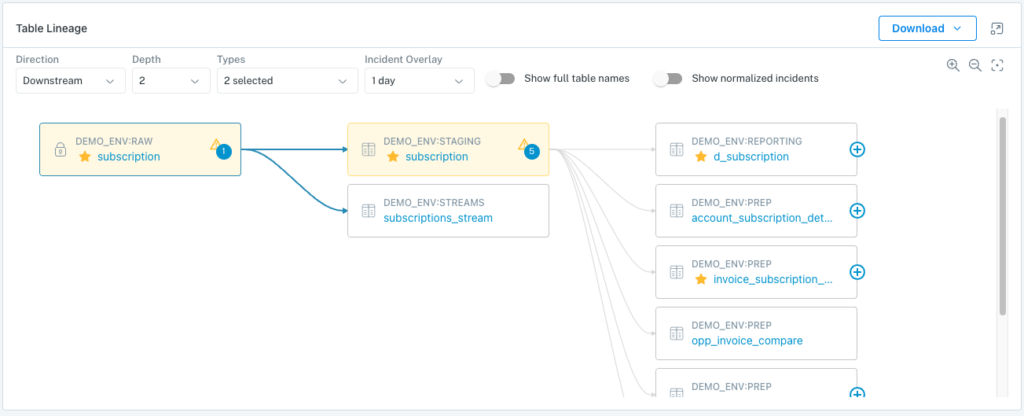
Snowflake table lineage in Monte Carlo.
Monte Carlo also leverages those query logs to determine when a data quality incident may be correlated with a query change. Some of these can be difficult to detect and parse manually, but Monte Carlo will immediately point out what line of code changed.
Our query insights go beyond changes and failures as well. Let’s take what we call “empty queries” as an example. This is a query that is successful–it doesn’t fail or skip–but it also doesn’t do anything. An example might be a query to INSERT rows from a table that hasn’t been updated within the specified time period.
Optimizing Pipeline Performance
Monte Carlo’s Performance feature also integrates with Snowflake resource compute data to analyze what queries are being issued, how long your queries take to run, how your data is partitioned, and more.
Have a query that’s running too long or timing out? Slow running data pipelines cost data teams time, money, and goodwill. They utilize excess compute, cause data quality issues, and create a poor user experience for data consumers waiting in suspense for data to return, dashboards to load, AI models to update…you get the idea.
While it’s not difficult to identify long-running queries, it is much more challenging to identify the queries that are unnecessarily long and then determine the root cause. Understanding which queries are part of, or are dependent on, different components of a data pipeline can be like putting together a jigsaw puzzle while blindfolded.
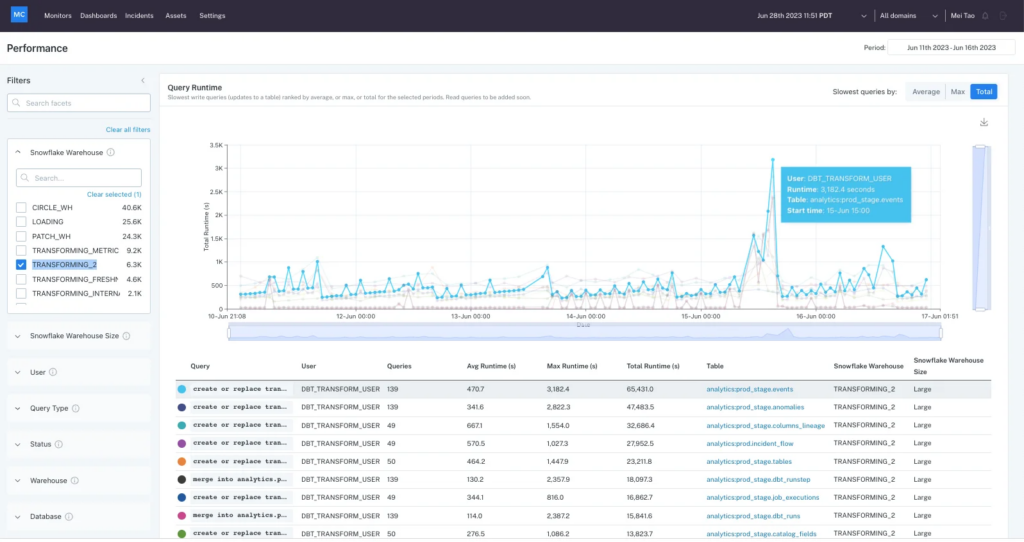
A screenshot of the Monte Carlo Data Performance Dashboard revealing the longest-running queries for the Snowflake warehouse “Transforming_2.”
Monte Carlo will analyze your data in Snowflake to understand how long each query is running, how much compute power you’re using, and how it integrates with the other queries in your warehouse to help you optimize not just your pipelines but your Snowflake performance and spend as well.
For the sake of argument, let’s say a resource monitor has alerted your team that the Snowflake data warehouse, “TRANSFORMING_METRX,” has exceeded its threshold. With Monte Carlo, you can quickly pull that query data from your Snowflake account and view all the query runtimes during the period when the alert was triggered. From there, you can drill into the top queries to determine how a variety of data, code and infrastructure factors came together to create the issue—and what you can do to solve it.
Measure insights and track performance with data sharing
Want to analyze your data quality performance to track how your practice is developing and resolving issues over time? Get your Monte Carlo data synced directly to your Snowflake account to create new queries and dashboards utilizing the Snowflake data share.
Monte Carlo and Snowflake: Better Together
Monte Carlo is proud to be a Snowflake Horizon Ecosystem Partner. Data is becoming more valuable than ever. It’s populating dashboards and informing key decisions, it’s fueling ML models running revenue generation operations, and it’s giving generative AI models a competitive advantage.
None of that is possible without high quality data, and that isn’t possible without the longstanding commitment from our key partners like Snowflake. You can rest assured we will continue to strengthen our integrations with native Snowflake Horizon capabilities to help Snowflake customers accelerate the adoption of high quality data.
Our promise: we will show you the product.
Read more posts.