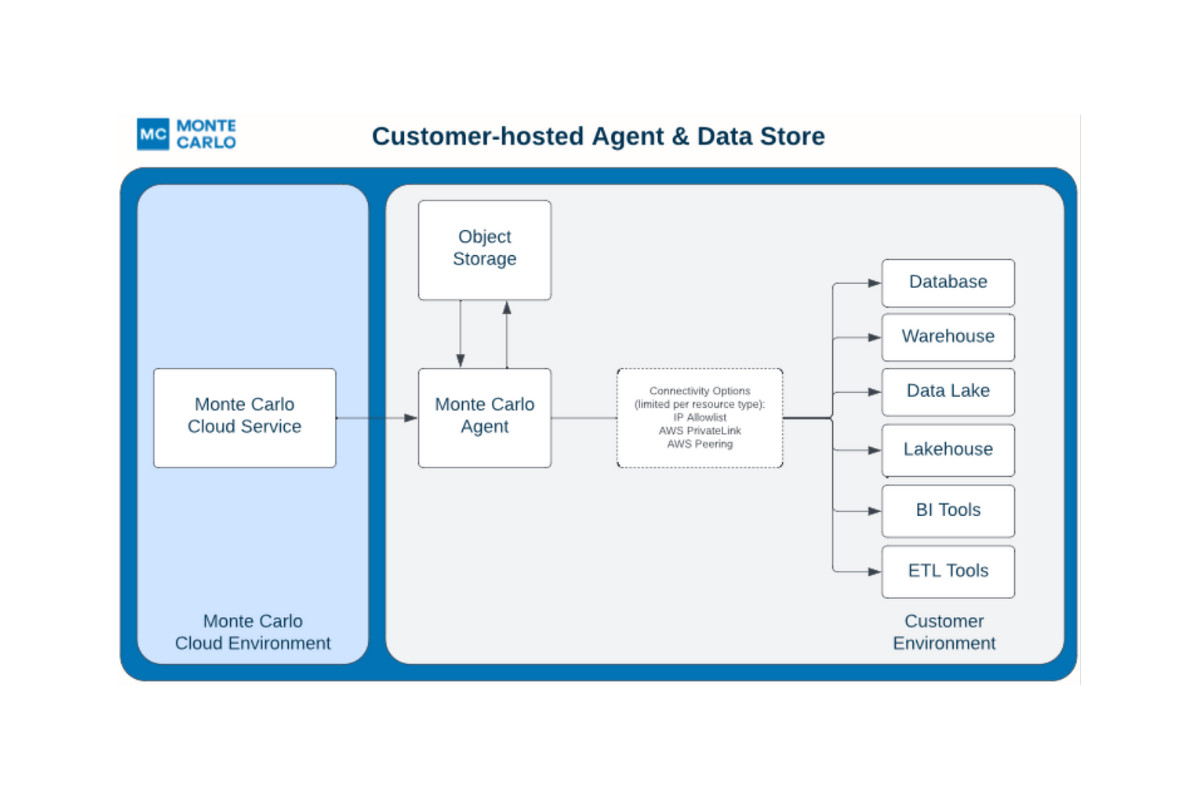
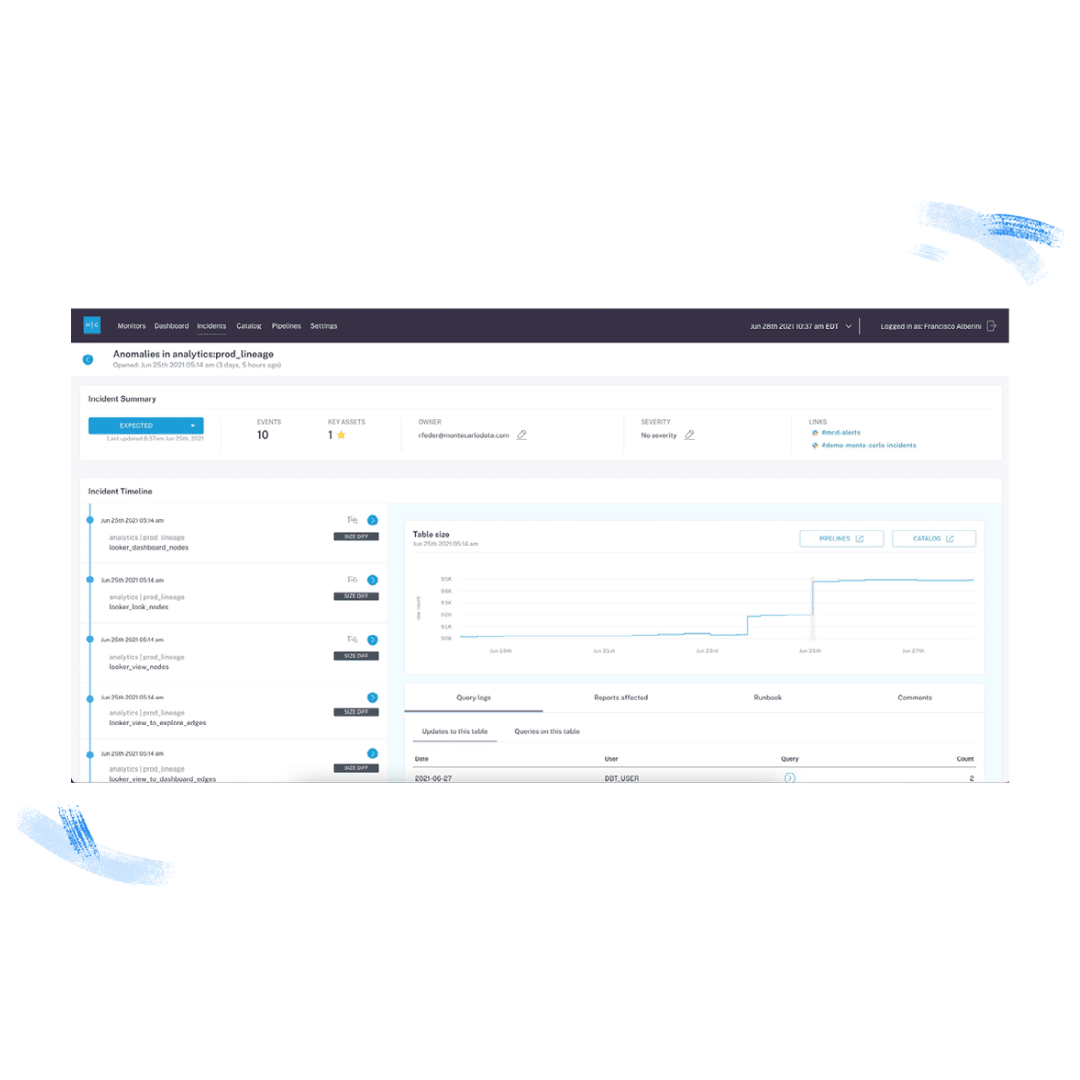
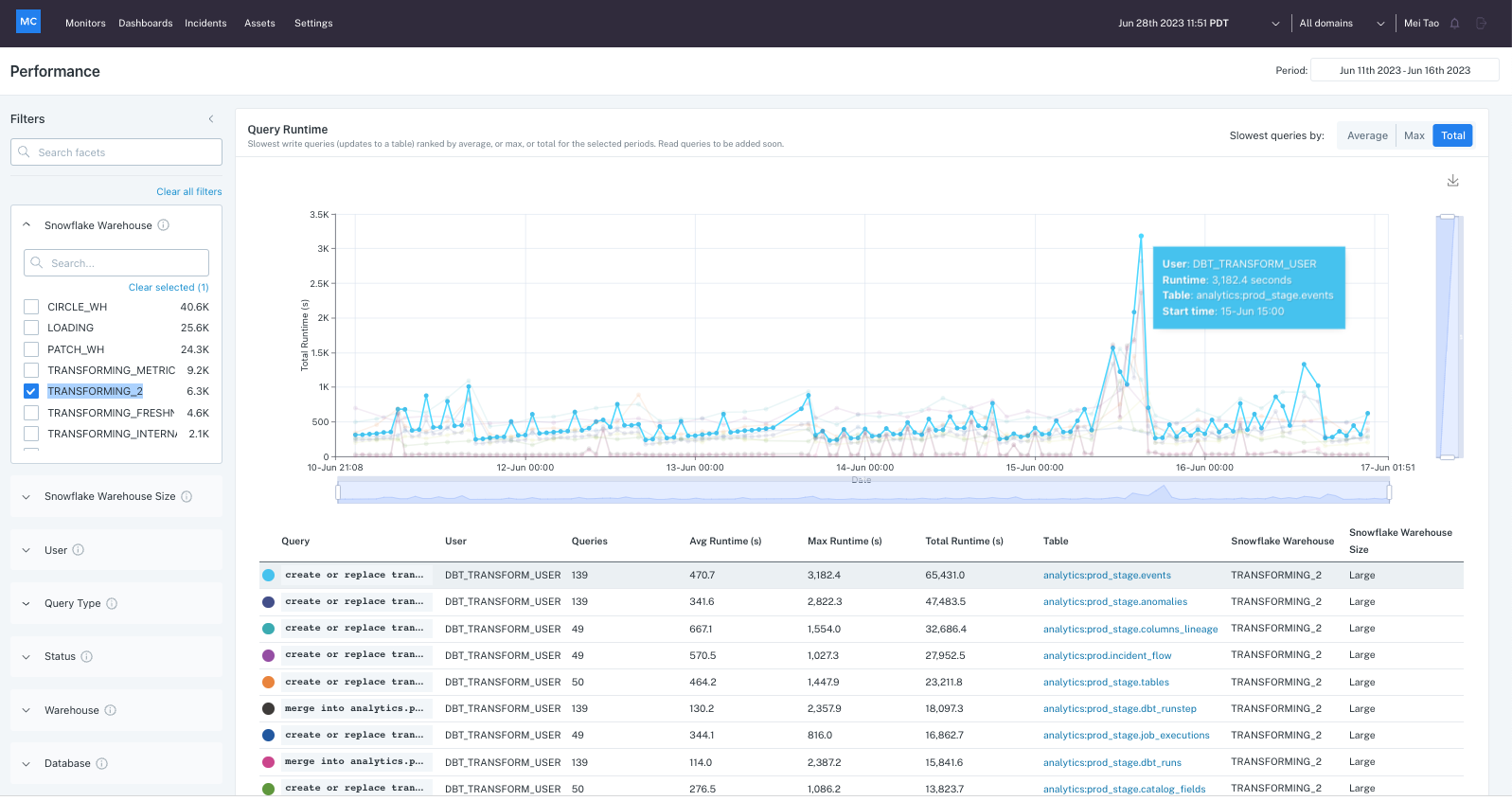
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monte Carlo Announces Delta Lake, Unity Catalog Integrations To Bring End-to-End Data Observability to Databricks


Prateek Chawla
Prateek Chawla is a Founding Principal Engineer and Technical Lead at Monte Carlo.
To help organizations realize the full potential of their data lake and lakehouse investments, Monte Carlo, the data observability leader, is proud to announce integrations with Delta Lake and Databricks’ Unity Catalog for full data observability coverage.
Over the past decade, Databricks and Apache Spark™ not only revolutionized how organizations store and process their data, but they also expanded what’s possible for data teams by operationalizing data lakes at an unprecedented scale across nearly infinite use cases.
Over the past several years, cloud data lakes like Databricks have gotten so powerful (and popular) that according to Mordor Intelligence, the data lake market is expected to grow from $3.74 billion in 2020 to 17.60 billion by 2026, a compound annual growth rate of nearly 30%.
Traditionally, data lakes held raw data in its native format and were known for their flexibility, speed, and open source ecosystem. By design, data was less structured with limited metadata and no ACID properties.
As a result, data observability has become particularly important for data lake environments as they often hold large amounts of unstructured data, making data quality issues challenging to detect, resolve, and prevent.
As Databricks shared in their official their Delta Lake announcement in 2019:
“While attractive as an initial sink for data, data lakes suffer from data reliability challenges. Unreliable data in data lakes prevents organizations from deriving business insights quickly and significantly slows down strategic machine learning initiatives. Data reliability challenges derive from failed writes, schema mismatches and data inconsistencies when mixing batch and streaming data, and supporting multiple writers and readers simultaneously.”
Since then, Databricks has aggressively moved toward allowing users to add more structure to their data. Features like the Delta Lake and Unity Catalog, help combine the best of both the data lake and data warehouse worlds (see: data lakehouse).
Today, we’re excited to announce Monte Carlo’s full integration with Delta Lake and Databricks Unity Catalog, helping teams detect, resolve, and prevent data quality issues within the data lake or data lakehouse environment. As part of this release, Monte Carlo also supports all three Databricks metastores: central Apache Hive, external Apache Hive, and AWS Glue.
Let’s dive into what these new features are, our new integrations, and why you should care.
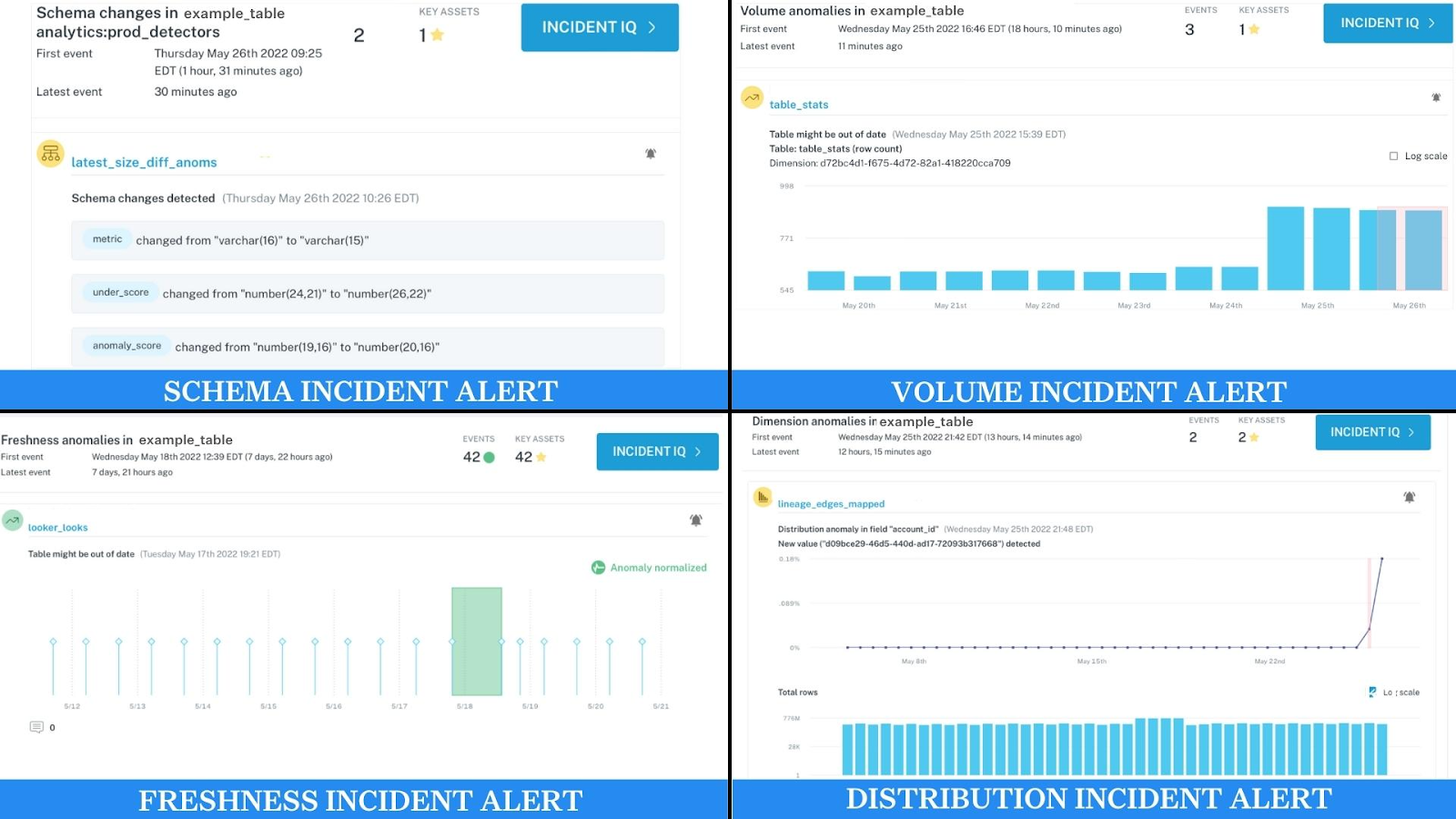
Monte Carlo can automatically monitor and alert for data schema, volume, freshness, and distribution anomalies within the data lake environment.
Delta Lake
The Delta Lake is an open source storage layer that sits on top of and imbues an existing data lake with additional features that make it more akin to a data warehouse. Delta tables, a revolutionary table format, are the beating heart of the Delta Lake and the default table type in Databricks.
What makes this table format so special is it is optimized for efficient big data storage and processing (the foundation is a versioned Parquet file) along with advanced features for better data management such as time travel; an ACID transaction log; the ability to write batch and streaming data into the same table; and more.
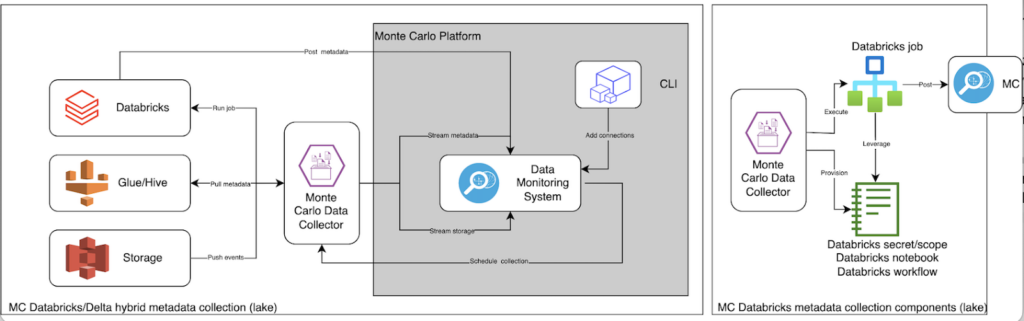
With this new release, Monte Carlo now supports all delta tables across all metastores and all three major platform providers including Microsoft Azure, AWS and Google Cloud.
The ACID transactions and logs provided by delta tables allow our data observability platform to access the history of actions taken on the tables and how they evolve over time, increasing the accuracy of our automatic monitors for data freshness, volume, and schema changes. It also enables users to create opt-in machine learning monitors for field health, dimension tracking, SLIs and other rules via our dashboard, API, SDK or monitors as code (IaC).
Moreover, Monte Carlo is now the first end-to-end data observability platform that integrates with Delta Lake and Unity Catalog across all endpoints in your data lake/lakehouse environment and down to the BI layer, providing coverage and visibility into key pillars of data health.
Unity Catalog
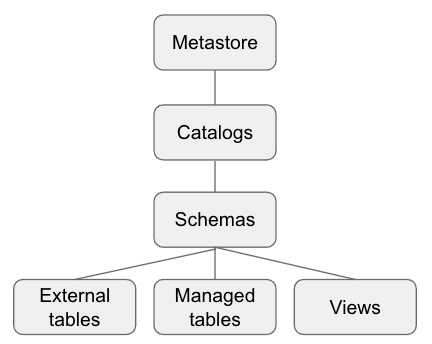
The Databricks Unity Catalog does what it says: it unifies individual metastores, catalogs and serves as a central metadata repository in Databricks. Unity Catalog gives data engineering and machine learning teams a way to seamlessly store, access, and manage data assets all in a central place – in other words, a data catalog specifically for Databricks environments.
Prior to its debut, Databricks customers needed to attach a metastore (Databricks Hive, an external Hive, or AWS Glue) to a cluster if they wanted to persist table metadata similar to a data warehouse.
The Unity Catalog allows Databricks users to discover and manage data assets in one place, as well as enables a standard governance model, and simplifies the process of securely sharing data with external organizations – two huge milestones for Databricks’ powered architectures.
With Monte Carlo’s new Unity Catalog integration, data teams can pull rich metadata from Unity Catalog as well as all Databricks metastores across AWS Glue and Apache Hive (both external and internal metastores), to assemble an end-to-end view of their data health at each stage of the pipeline.
To extend this integration and bring additional coverage to our customers, we are currently working hand-in-hand with the Databricks team as the first data observability provider to build out end-to-end Apache Spark™ data lineage on top of Unity Catalog, which will enable us to give mutual customers the necessary tools to conduct root cause analysis on their critical Apache Spark™ data sets, down to the field level.
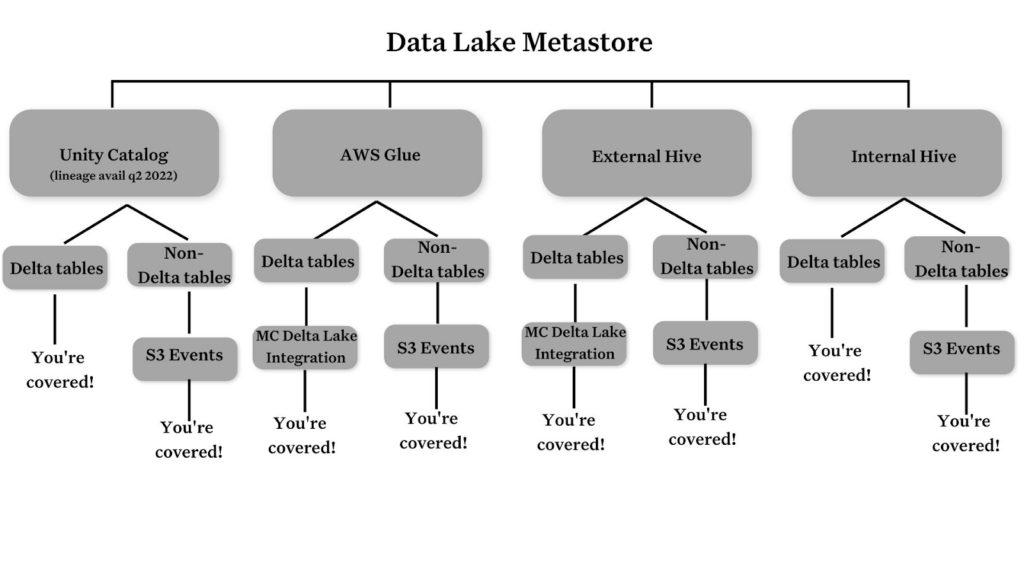
This new capability will replace our existing Apache Spark™ lineage solution and give teams more comprehensive and robust coverage. For Databricks users that have not adopted Unity Cloud, Monte Carlo can also integrate with each of the three individual metastore “flavors” as well for data observability coverage unique to your environment.
For more information on our integrations check out our documentation.
What our customers have to say
Monte Carlo and Databricks customers like ThredUp, a leading online consignment marketplace, and Ibotta, a global cashback and rewards app, are excited to leverage the new Delta Lake and Unity Catalog integrations to improve data reliability at scale across their lake and lakehouse environments.

ThredUp’s data engineering teams leverage Monte Carlo’s capabilities to know where and how their data breaks, in real time. The solution has enabled ThredUp to immediately identify broken data before it affects the business, saving them time and resources on manually firefighting data downtime.
“With Monte Carlo, my team is better positioned to understand the impact of a detected data issue and decide on the next steps like stakeholder communication and resource prioritization. Monte Carlo’s end-to-end lineage helps the team draw these connections between critical data tables and the Looker reports, dashboards, and KPIs the company relies on to make business decisions,” said Satish Rane, Head of Data Engineering, ThredUp. “I’m excited to leverage Monte Carlo’s data observability for our Databricks environment.”

At Ibotta, Head of Data Jeff Hepburn and his team rely on Monte Carlo to deliver end-to-end visibility into the health of their data pipelines, starting with ingestion in Databricks down to the business intelligence layer.
“Data-driven decision making is a huge priority for Ibotta, but our analytics are only as reliable as the data that informs them. With Monte Carlo, my team has the tools to detect and resolve data incidents before they affect downstream stakeholders, and their end-to-end lineage helps us understand the inner workings of our data ecosystem so that if issues arise, we know where and how to fix them,” said Jeff Hepburn, Head of Data, Ibotta. “I’m excited to leverage Monte Carlo’s data observability with Databricks.”
Pioneering the future of data reliability for data lakes
These updates enable teams leveraging Databricks for data engineering, data science, and machine learning use cases to prevent data downtime at scale.
When it comes to ensuring data reliability for data lakes, Monte Carlo and Databricks are better together. For more details on how to execute these integrations, see our documentation.
Learn more about how leading data teams are leveraging Databricks and Monte Carlo for end-to-end data observability by reaching out to Prateek and book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.