Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monte Carlo Expands Deployment Options To Enable Multi-Cloud Hosting

Prateek Chawla
Prateek Chawla is a Founding Principal Engineer and Technical Lead at Monte Carlo.

Michael Segner
Michael writes about data engineering, data quality, and data teams.
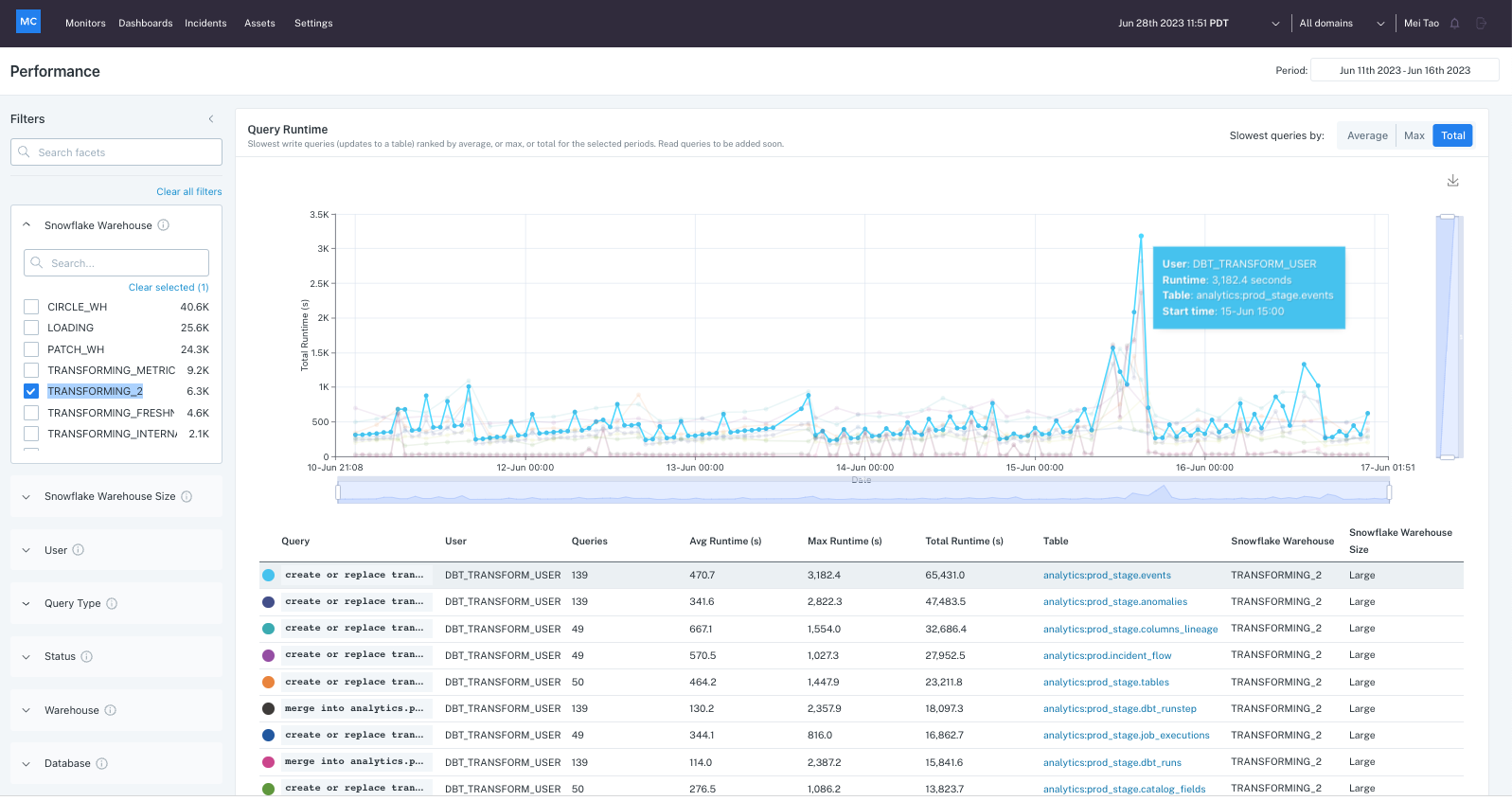
It’s hard to anticipate all the ways data quality can be impacted, which makes it a perfect problem for machine learning and data observability.
Our platform understands how your pipelines, systems, and data normally behave, and when they start acting up, we alert you to the problem and provide insights on how to fix it. This greatly mitigates the risks associated with bad data quality and improves data team efficiency by 30 percent or more.
While Monte Carlo sends queries to monitor customer resources, our cloud service doesn’t need to store record level data to deliver the alerts and insights described above. The only information collected by Monte Carlo is table metadata, aggregated metrics, query logs, and anonymized statistics generated across your modern data stack.
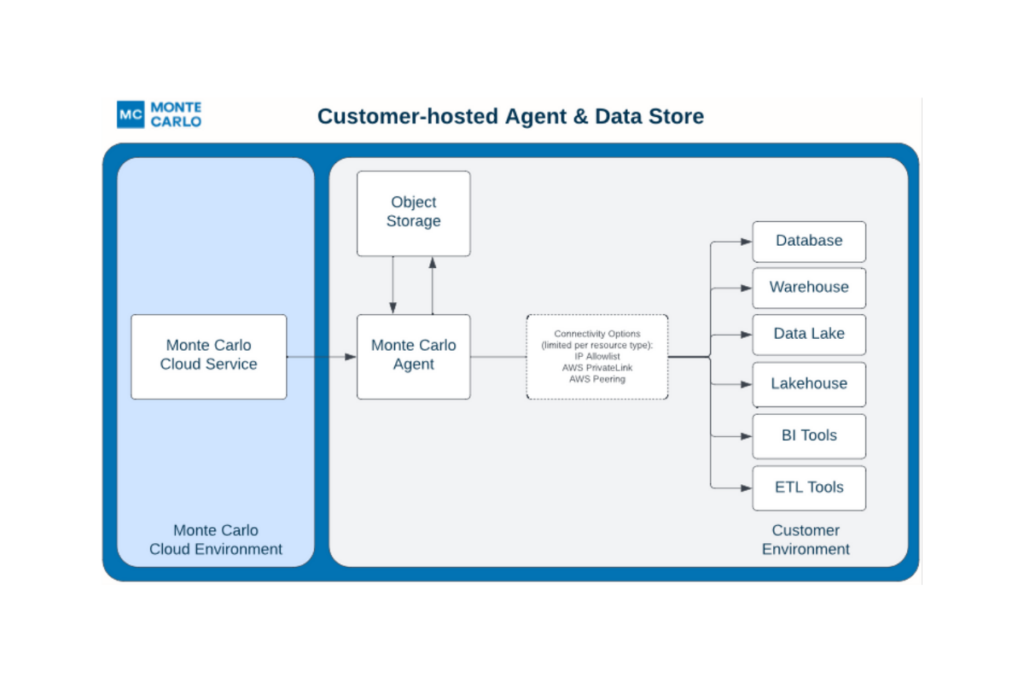
Interfacing to your resource from Monte Carlo is generally via an agent that can sit either in Monte Carlo’s cloud or yours. Today that agent can be deployed to AWS and GCP environments, and in a few months Azure and other cloud environments will be supported, too.
This is great news for users who want more control over how they connect to our software.
That isn’t the only architecture change we’ve made however. There are times when users want to sample a small subset of individual records within the platform as part of their troubleshooting or root cause analysis process. They may have a desire or requirement for this type of sampling data to persist within their clouds, but they would rather not deploy and manage an agent.
Users can now opt to have this data stored within a separate S3, GCS bucket, or Data Store hosted within their AWS, GCP, or Azure environments respectively. This provides complete control without having to host an agent.
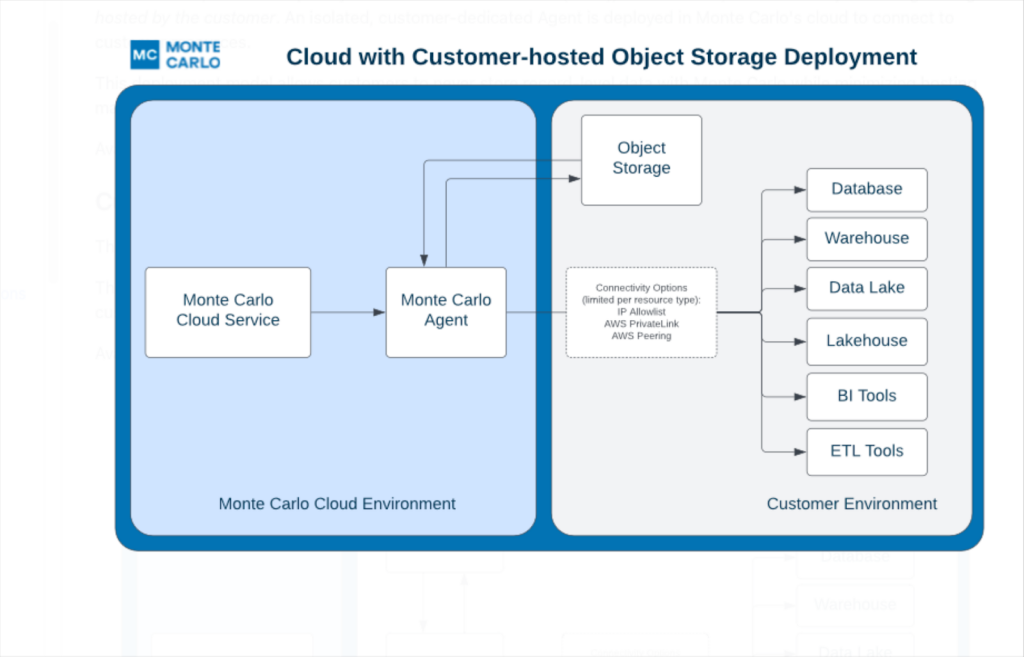
Of course this object storage can also sit alongside our agent in the Monte Carlo environment for a full SaaS deployment, which means no infrastructure or resources to manage.
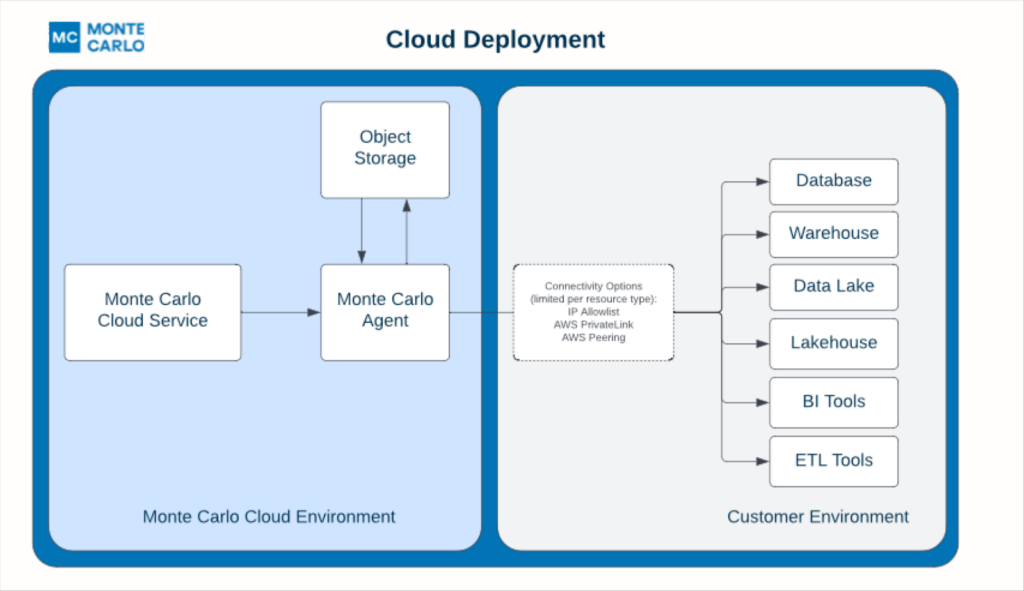
What this all means is that Monte Carlo customers have more options to configure their deployment to best align with both their connectivity and internal data handling guidelines. That’s a win for everyone!
Interested in learning more about our data observability platform architecture and roadmap? Set up a time to talk with us!
Our promise: we will show you the product.
Read more posts.