Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monte Carlo + Databricks Doubles Mutual Customer Count—and We’re Just Getting Started


Matt Sulkis
Matt is the head of partnerships at Monte Carlo.
When it comes to partnerships at Monte Carlo, it’s always been our aim to double-down on the technologies we believe will shape the future of the modern data stack. So, with that imperative in mind, it’s no surprise that we would continue our momentum with the Databricks team to bring even more observability to the Lakehouse.
Over the past decade, Databricks and Apache Spark™ not only revolutionized how organizations store and process their data, but they also expanded what’s possible for data teams by operationalizing data lakes at an unprecedented scale across nearly infinite use cases. In fact, according to Mordor Intelligence, the data lake market is expected to grow from $3.74 billion in 2020 to $17.6 billion by 2026—an expansion of nearly 30%.
Since last year’s Data & AI Summit, Monte Carlo has already nearly doubled its Databricks customers, with considerable traction in the Healthcare and Media verticals—including the likes of Vizio, Abacus Medicine, and Comcast, who is on tap to speak at this week’s Data & AI Summit on how it’s external data product Effectv drives data observability with Databricks and Monte Carlo.
Data observability isn’t just helping customers at the storage layer either. At Ibotta—a cash back rewards platform that has delivered more than $1.1 billion in cumulative rewards to its users— Head of Data Jeff Hepburn and his team rely on Monte Carlo to deliver end-to-end visibility into the health of their data pipelines from ingestion in Databricks right down to the business intelligence layer.
“Data-driven decision making is a huge priority for Ibotta, but our analytics are only as reliable as the data that informs them. With Monte Carlo, my team has the tools to detect and resolve data incidents before they affect downstream stakeholders, and their end-to-end lineage helps us understand the inner workings of our data ecosystem so that if issues arise, we know where and how to fix them,” said Jeff. “I’m excited to leverage Monte Carlo’s data observability with Databricks.”
And we’re just getting started. Read on to find out what has us so excited about the Lakehouse, everything we’ve announced so far, and what’s next for Databricks and Monte Carlo.
Why the Lakehouse Needs Data Observability
Data lakes create a ton of unique challenges for data quality. Data lakes often contain larger datasets than what you’d find in a warehouse, including massive amounts of unstructured data that wouldn’t be possible in a warehouse environment. For data teams that need flexibility with their data, a data lake is the holy grail.
But for a data lake to be truly effective for modern data teams, there are a lot of components and technologies that need to work together to ensure that your pipelines are reliable across all endpoints.
While data testing can be helpful for structured storage and compute architectures, these solutions breakdown at the scale of most data lakes. The consequences of this complexity can be catastrophic, especially when it comes to one of the data lake’s most salient use cases—machine learning. When the machine learning training data goes bad, the model is right there with it. Ensuring data quality is absolutely critical for ML practitioners to deliver ML products that drive real-world value for their organizations and external customers, more so now than ever before with the rise of generative AI and more widely applicable ML use cases.
For today’s data and ML leaders, reducing—and even eliminating—data downtime is more than just a pipeline dream for Databricks customers with Monte Carlo. It’s the reality.
Everything we’ve announced so far…
Platforms that drive both flexibility and scalability are the future of the modern data stack, and Databricks is at the front of the pack. Over the last several years, Databricks has given users the ability to add more structure to the data inside their data lake. Two of the most critical features, Delta Lake and Unity Catalog, combine the best of both the data lake and data warehouse into one solution, giving data leaders the power to scale quickly without losing the ability to operationalize that data for critical use cases.
After launching our partnership with Databricks last year, Monte Carlo has aggressively expanded our native Databricks and Apache Spark™ integrations to extend data observability into the Delta Lake and Unity Catalog, and in the process, drive even more value for Databricks customers.
Delta Lake
Delta Lake is the key to storing data and tables within the Databricks Lakehouse Platform. So, any data observability solution for Databricks had to extend visibility directly to a user’s delta tables.
As the only data observability platform to provide full visibility into delta tables
With our delta lake integration, Monte Carlo supports all delta tables across all metastores and all three major platform providers including Microsoft Azure, AWS and Google Cloud.
Unity Catalog
As the name implies, the unity catalog brings unity to individual metastores and catalogs and serves as a central metadata repository for Databricks users. Unity Catalog gives data engineering and machine learning teams a way to seamlessly store, access, and manage data assets all in a central place – in other words, a data catalog specifically for Databricks environments.
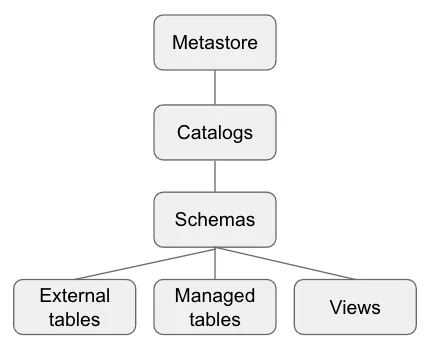
And Monte Carlo’s Unity Catalog integration allows data teams to pull all that rich metadata from Unity Catalog and Databricks metastores across AWS Glue and Apache Hive (both external and internal metastores) into a single end-to-end view of their data health at every stage of the pipeline.
System Tables for Lineage
Just as important as detecting a data quality incident is understanding the downstream impact. Our latest Databricks release, System Tables for Lineage, is designed to help our mutual customers do just that. System Tables for Lineage helps customers understand the impact of data incidents at each stage of the pipeline, giving data teams the ability to track the health of their entire lakehouse ecosystem.
ThredUp’s data engineering teams leverage System Tables for Lineage to know where and how their data breaks in real-time. The solution has enabled ThredUp to immediately identify bad data before it affects the business, saving them time and resources on manually firefighting data downtime.
“With Monte Carlo, my team is better positioned to understand the impact of a detected data issue and decide on the next steps like stakeholder communication and resource prioritization. Monte Carlo’s end-to-end lineage helps the team draw these connections between critical data tables and the Looker reports, dashboards, and KPIs the company relies on to make business decisions,” said Satish Rane, Head of Data Engineering, ThredUp. “I’m excited to leverage Monte Carlo’s data observability for our Databricks environment.”
What’s new for Databricks & Monte Carlo
As we continued to invest in our Databricks integration, we’ve added even more features to drive value for Databricks users.
Unity Catalog Full Table Lineage
It’s not enough to simply detect data quality incidents—we wanted to help Databricks users respond to and resolve those incidents as well.
Unity Catalog Full Table Lineage gives Databricks users a comprehensive look at their data quality incidents to understand what tables have been impacted, root-cause upstream, and resolve incidents faster.
To help Databricks users root-cause faster in the Delta Lake as well, we added Delta History on Incidents.
Delta History on Incidents helps data leaders identify root cause by determining both the who and the what on any table within the Delta Lake.
Expanded out-of-the-box volume monitors
Finally, to provide more accurate anomaly tracking and support for SQL Warehouses, we expanded our out-of-the-box volume monitors to include Row Count and Byte Size for all custom monitors.
The future of Databricks and Monte Carlo
From Delta Lake to the Unity Catalog, Databricks is engineering the future of the modern data lake—and whatever happens next, Monte Carlo is ready and waiting to make it observable.
As mutual customers continue to grow, developing and expanding our Databricks integration is top of mind for the team here at Monte Carlo. From new features to tighter integrations, we can’t wait to share everything that’s next for Monte Carlo and Databricks. Keep your eyes open for more announcements coming soon.
We’re bringing observability to the data lake. And we’re just getting started.
Want more information about our existing Databricks integrations? Check out our documentation to learn what’s available for Databricks users and how you can get started.
Ready to learn more about how leading data teams are leveraging Databricks and Monte Carlo for end-to-end data observability? Fill out the form below and one of our data observability experts will be in touch.
Our promise: we will show you the product.
Read more posts.