Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Rise of the MLOps Engineer And 4 Critical ML Model Monitoring Techniques


Ryan Kearns
Ryan is a data scientist at Monte Carlo.
An often quoted, but still painful, statistic is that only 53% of machine learning projects make it from prototype to production. As a data scientist, I can vouch that unfortunately once in deployment, it’s not exactly smooth sailing either.
The model, already navigating undercurrents of skepticism from business users, is just as likely to sail into uncertain waters as it is to reach the shores of predictive validity. I’ve seen companies lose millions of dollars because of data freshness issues in a machine learning model set to auto-pilot.
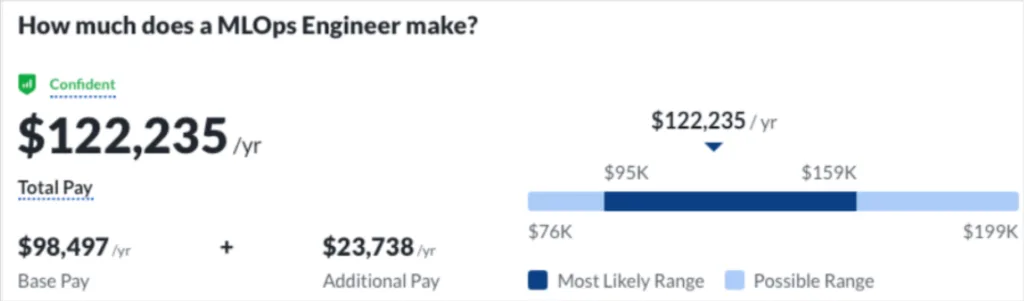
As a result of these challenges and the severe consequences of inaccurate models, the MLOps engineer is an increasingly in demand role for data teams. The 2022 LinkedIn jobs report had “machine learning engineer” as the fourth fastest growing role in the country with nearly 20% of jobs being available for remote work.
The MLOps engineer is the captain responsible for all aspects of the ML model lifecycle, but with a focus on ensuring ML models stay the course. It is the job of the MLOps engineer to ensure the model performs as well in the real world as it does in the lab, which requires some data science knowledge alongside strong engineering and orchestration skills.
Ensuring this real world success requires understanding how to best retrain models, maintain reliable data pipelines, prevent ML feature anomalies, and manage model development/versioning at scale.
This post will show specific techniques for how MLOps engineers can scale their impact and drive positive business outcomes with real-time customer impact Let’s get into it.
Monitoring ML Model Accuracy as A Retraining Trigger
One central question plaguing MLOps engineers is when to retrain a model.
Retraining too often is inefficient and adds unnecessary complexity. Retrain too infrequently and your models are operating on stale training data that is significantly different than what is currently flowing through production.
At the same time, retraining on a set time interval, say every quarter, risks ignoring tectonic shifts in the market. For example, a global pandemic may cause dramatic shifts in how people consume online reading material as Blinkist and their marketing spend optimization algorithm found out.
While these shifts may look obvious in retrospect, they are not always readily apparent in the moment and difficult to anticipate. The ideal then, would be to retrain ML models immediately once they start underperforming.
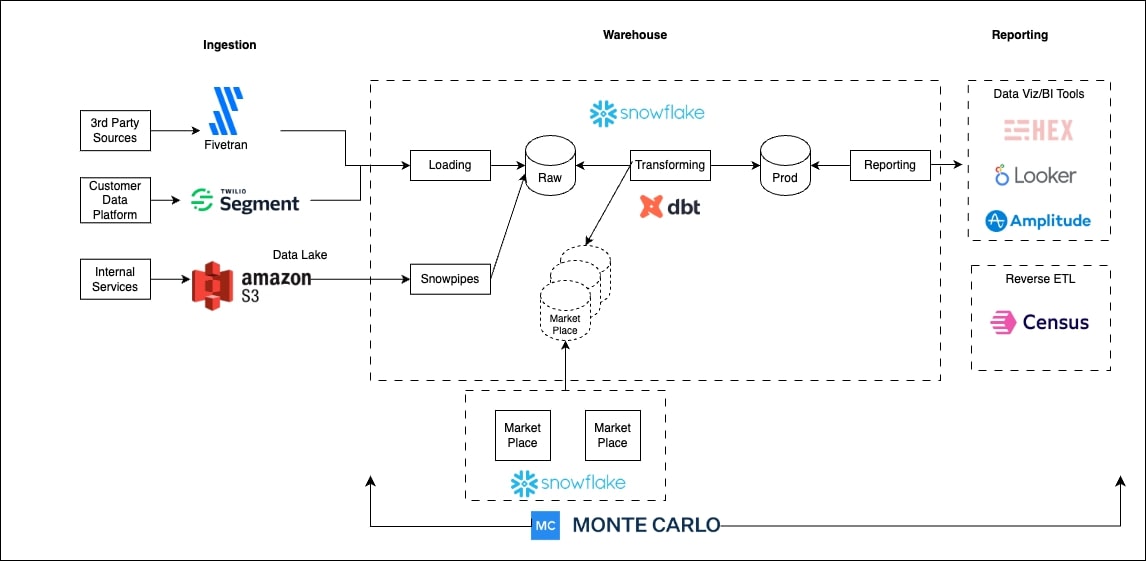
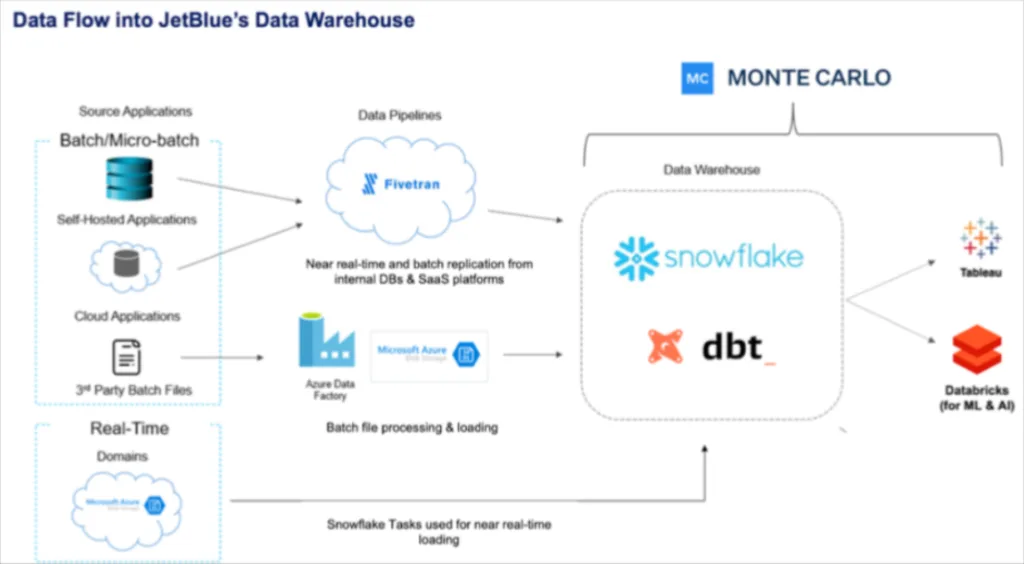
Some of the leading data teams have discovered ways to do exactly that by leveraging data observability to automatically monitor and alert when accuracy levels dip below acceptable standards. That is what JetBlue did as described by data scientist Derrick Olson in a recent Snowflake webinar.
Essentially, JetBlue runs a batch inference on their model that writes back to a Snowflake table so those predictions can be joined with the actual values to determine the mean absolute error.
That error margin is then monitored by Monte Carlo so if it reaches a certain point, an alert is sent. Their data science team can then proactively retrain their models and reach out to their stakeholders before they lose trust in the predictive models capabilities. The team is now starting to evaluate how Monte Carlo can not only monitor for model drift, but data drift as well by leveraging the Snowflake data share to signal when to trigger model retraining jobs.
Derrick didn’t share the specific type of monitors he set, but in a similar position here is how I would do it as a MLOps engineer:
Suppose we have a model in production that runs cross-validation on our most recent labeled data whenever it retrains. With experiment tracking set up, with MLFlow or a similar tool, it is straightforward to track metrics from this run, like the mean absolute error:
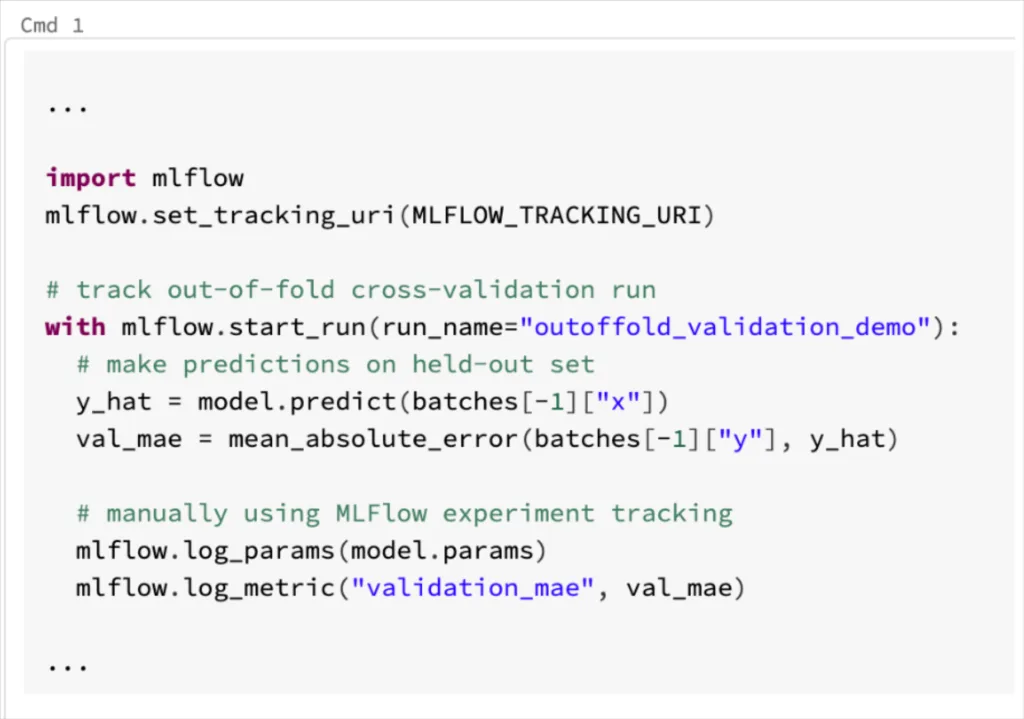
Then, I can use a tool like Monte Carlo to get the latest value for this prediction error, and automatically alert me if this value spikes to an alarming amount:
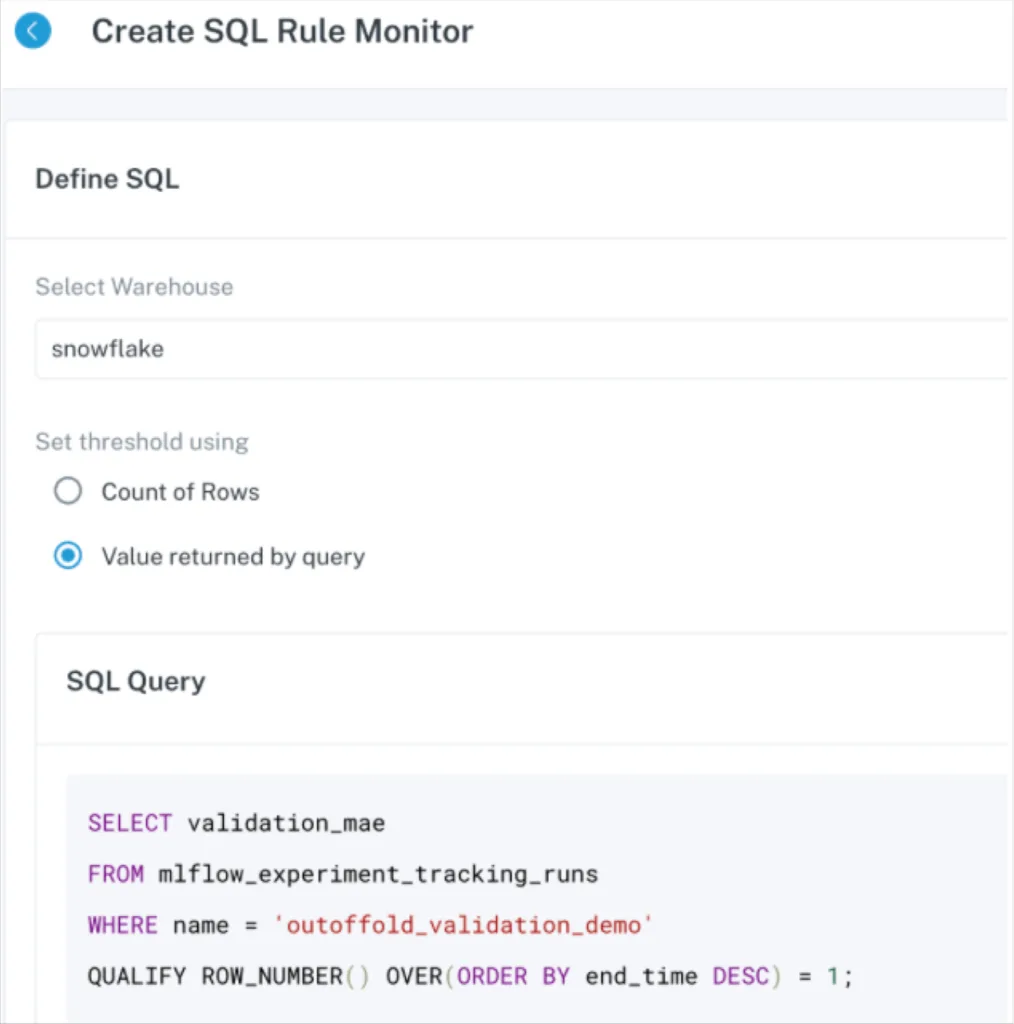
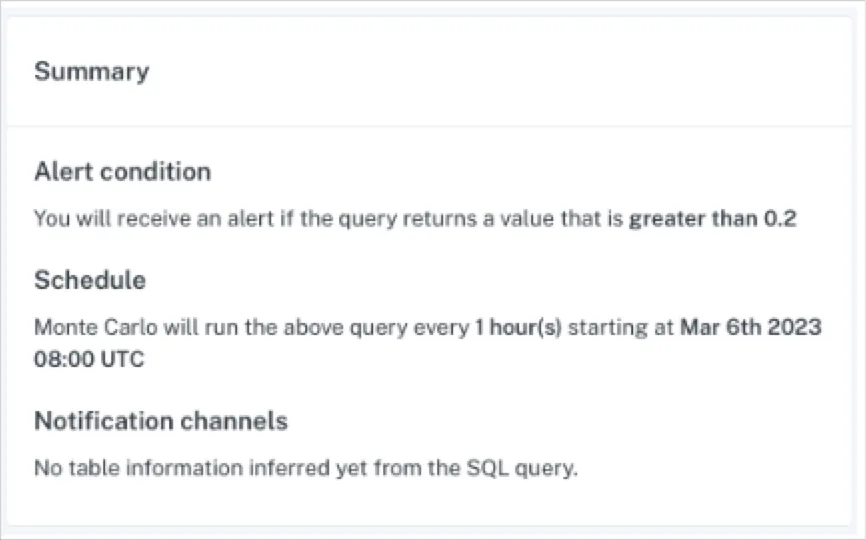
You could also configure Monte Carlo monitors directly on the input data, to monitor features of data drift like the population stability index (PSI). With a collection of monitors like this, running on automatic schedules, an MLOps engineer can have real-time alerting whenever model performance suffers or the underlying distribution of data changes.
Monitoring For ML Model Feature Anomalies
ML models can drift when they are operating on stale data or when the data pipelines feeding them are experiencing issues, but they can also go wrong when the actual data itself, specifically the ML model features, experience anomalies.
For a real Monte Carlo example, one of our production models makes use of a “seconds since last metadata refresh” feature. This value is an integer, and in many places it’s stored as signed, meaning our system is perfectly happy ingesting a negative value for this feature. But we know that this value should never be negative, otherwise we’d be somehow measuring data from the future.

Feature stores are often complex, so it’s possible we never configured a test for this edge case. By placing field health monitors on your feature tables, a data observability platform can learn automatically that this field’s negative rate is 0%, and an alert would be sent to the MLOps engineer should this ever change.
A leading subscription based news company leverages Monte Carlo to automatically monitor their custom built feature store to prevent these types of scenarios from impacting the dozens of models they have in production.
Because features feed ML models downstream, this type of monitoring accelerates time to detection and can prevent drift/inaccuracies before they occur. By catching the issue upstream, it is also much easier to determine the feature anomaly as the root cause versus the many other variables that could be at play.
Solving The Garbage In, Garbage Out Problem With Pipeline Monitoring
We’ve previously covered in depth why monitoring data pipelines that feed ML models is so important for preventing data quality issues from infiltrating each stage of the machine learning lifecycle.
But in summary, ML models are only as good as the input they are given. If the data pipeline is unreliable, then data scientists will need to spend more time cleaning data sets and ensuring they have all of the relevant data at hand. That’s exactly what a MLOps engineer is trying to prevent.
In the Snowflake webinar JetBlue data scientist Derrick mentions how helpful it is for the data science team to know they don’t need to continuously do “sanity checks” on the volume of their data sets since they know they are being monitored for volume anomalies (as well as freshness, schema, and overall quality).
To cite another example, one company’s custom acquisition model suffered significant drift due to data pipeline reliability issues. Facebook changed how they delivered their data to every 12 hours instead of every 24. Their team’s ETLs were set to pick up data only once per day, so this meant that suddenly half of the campaign data that was being sent wasn’t getting processed or passed downstream, skewing their new user metrics away from “paid” and towards “organic.”
ML Model Versioning and Optimization
Data observability can be used by MLOps engineers to better monitor production machine learning models, but these solutions are designed to detect, resolve, and prevent incidents in data pipelines and data anomalies.
As most MLOps engineers know, the success of a machine learning model is dependent on the quality of the data infrastructure but also on the quality of the model itself. Additionally, data scientists and MLOps engineers need the tools to be able to scale the production and management of these ML models.
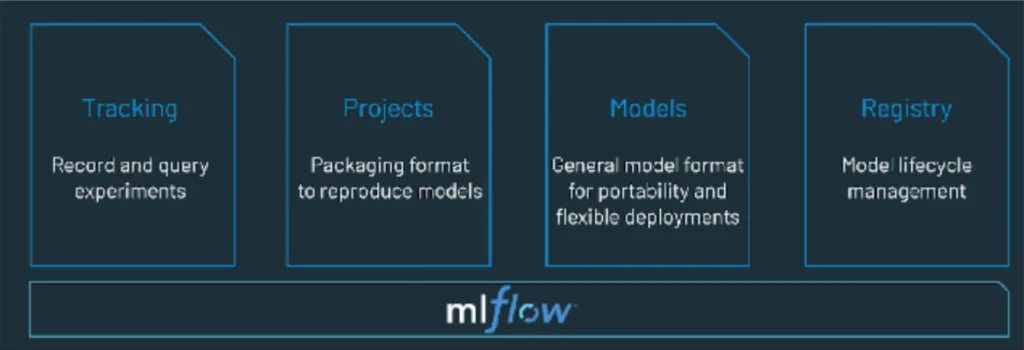
That’s where MLOps tools like Databricks MLflow come in. While data observability can broadly monitor accuracy levels, it can’t tell you how changes in the model impacted the results or the runtime for example. MLflow is like Git for MLOps, providing a model registry, log of all experiments, and helping to see the minute differences between model versions.
To Succeed, MLOps Engineers Must Scale Themselves
The MLOps engineer has emerged as the lynch pin of the data team and a key bridge between data scientists and data engineers. Machine learning models and algorithms are one of the most effective and direct ways data teams can add value to their organization, but only if models are accurate and well managed. For most teams, the techniques mentioned above alongside data observability and MLOps platforms can help scale success.
Happy training!
Interested in how data observability can make your life as a MLOps engineer or data engineer better? Schedule a time to talk with us below!
Our promise: we will show you the product.
Read more posts.