 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Contracts and 4 Other Ways to Overcome Schema Changes


Scott O'Leary
Scott O'Leary is a founding member of Monte Carlo's Sales team.
There are virtually an unlimited number of ways data can break.
It could be a bad JOIN statement, an untriggered Airflow job, or even just someone at a third-party provider who didn’t feel like hitting the send button that day.
But perhaps one of the most common reasons for data quality challenges are software feature updates and other changes made upstream by software engineers. These are particularly frustrating, because while they are breaking data pipelines constantly, it’s not their fault.
In fact, most of the time they are unaware of these data quality challenges.
As GoCardless team lead and senior data engineer Andrew Jones recently wrote in his blog post about data contracts, “What I found in my swim upstream were well meaning engineers modifying services unaware that something as simple as dropping a field could have major implications on dashboards (or other consumers) downstream.”
But, if it’s a matter of unawareness, why does it happen the second time? Or the third or fourth, or ninety eighth time for that matter?

Like most data quality challenges the short answer is, “a combination of technical and process challenges,” but that doesn’t feel very fulfilling. So let’s dive a bit deeper into some of those data quality challenges and then take a look at five different approaches for preventing upstream data issues.
Why does this keep happening?
Tight coupling
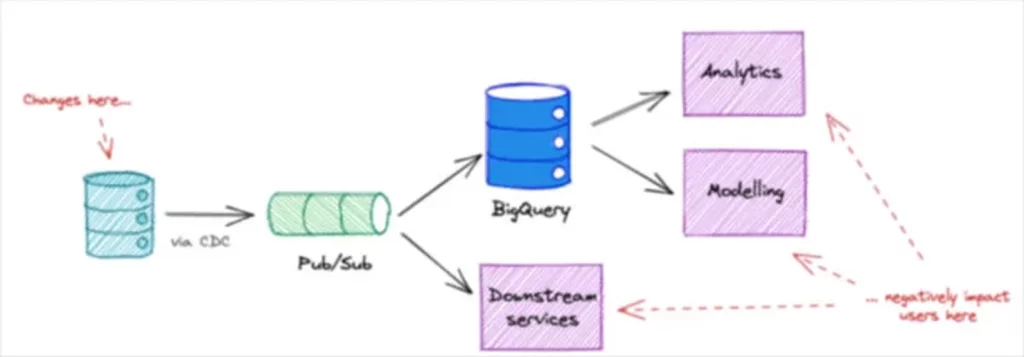
The technological reason for upstream data quality challenges can be traced back to the tight coupling between data being emitted from production services and other data systems.
As Convoy Head of Product, Data Platform, Chad Sanderson wrote in our blog, “The data in production tables are not intended for analytics or machine learning. In fact, service engineers often explicitly state NOT to take critical dependencies on this data considering it could change at any time. However, our data scientist needs to do their job so they do it anyway and when the table is modified everything breaks downstream.”
CEO and founder of dbt, Tristan Handy, also recently described this data quality challenge in one of his roundup posts, “In a world without clearly-defined interfaces, your systems are tightly coupled—everything directly calls everything else, there are no opportunities for rules and helper functionality to be inserted in between subsystems. This is how our world works today in the MDS: for example, Fivetran loads data into a table, dbt reads data from a table. If Fivetran changes the schema of that table, it can easily break the dbt code reading from that table. No contracts, no interfaces, no guarantees. Tight coupling.”
Oftentimes technology challenges are quicker to solve as they can be tackled with a new tool or architecture adjustment. For example, some organizations have solved this data quality issue by using solutions like Protobuff or Pub/Sub to help decouple their production databases from their analytical systems.
However, It’s often easier to change technology than it is to change culture or people’s habits–which is where the root of this data quality challenge lies.
If you see something, say something

Software engineers are generally unaware of the data quality challenges arising as a consequence of their actions because by and large as data practitioners we just don’t tell them. Consider this all too familiar story.
The software engineer is working hard to do their job–ship a key feature update on time to improve the customer experience.
They do what they’ve done countless times before, they save and commit changes to a local branch and repository on GitHub and then issue a pull request to move the code into production.
However, this time, the new code and feature involves changing or removing a certain field in the operational data store. Tools that slurp that data automatically make that change on the schema in the next update, and as a result, all data models and dashboards downstream break.
What happens next is part of the problem.
All too often, data teams generally don’t go back to the software engineer and let them know about the issue or ask about the logic for the field change as often as they should. Instead, to save time, the data professional investigates the problem, learns the new context (maybe the revenue field has been changed to an ARR field), and makes the change.
The modern data stack has made it easier than ever to implement these changes quickly. Orchestration tools like dbt can update models without analytics engineers needing to enter a line of code and data observability tools can alert data engineers to bad data and help them resolve it in minutes as opposed to days.
The band aid has become so quick and painless (which is a good thing by the way!) that we don’t always look to make systemic changes to prevent this problem in the long-term, before they enter production. Perhaps we don’t want to risk rocking the boat, or we like being the firefighter saving the day, or the rigor of our processes have not yet caught up to the software engineering field.
5 different approaches to prevent upstream data quality issues
Regardless of the root cause of the upstream data quality issue, after an incident we need to talk to our software engineering colleagues in a blameless postmortem to help them become part of the solution.
What should that solution look like? Well, there are a couple of ways organizations have worked to solve this problem.
1. Data contracts
One of the challenges software engineers face is they have nothing to reference to understand what fields impact what data assets or consumers. The way they understand and manage their dependencies is through the concept of an API, which is essentially a documentation and change management mechanism.
Data contracts, which are the codified requirements from data consumers, can serve a similar purpose. When software engineers are committing their code changes, they can reference the contract to see if any important fields are impacted and proactively work with the data team to mitigate its impacts.
The challenge and potential downside to data contracts is that they are an upfront investment that require the data team to coordinate with data consumers across the organization to concretely define their needs, anticipate future developments, and understand the relationship between entities (perhaps creating an entity relationship diagram or ERD).

2. Leveraging DataOps teams and methodologies
Like GoCardless, Vimeo also leveraged contracts and schema registries to help combat upstream data quality issues. They found success by implementing a data observability grounded approach (more on that later), while also creating a DataOps team to help coordinate overlapping, gray areas across teams.
Vimeo’s DataOps team helps analytics teams in the self-service process to keep an eye on the big picture, leverage previous work, and prevent duplication.
Creating a team that doesn’t own any data assets but has explicit accountability for the connections and overlaps between them can help encourage systemic solutions when other data teams may be tempted to slap the band-aid on so they can tackle the rest of their giant to-do list.
3. Decoupling your dbt models
While data contracts can be used successfully with a diverse range of approaches, the use cases illustrated above by Convoy, GoCardless, and Vimeo are more ETL (extract, transform, then load) focused solutions.
Tristan at dbt Labs recently suggested some approaches to help decouple systems that are more ELT and dbt centric. He suggested:
- “Private vs. public methods. Allow subsystems to expose only certain pieces of their functionality to other parts of the DAG. Allow a given dbt project to, for example, expose five models but keep the 80 upstream models private. This allows these 80 upstream models to change without breaking downstream code maintained by others; as long as the 5 public models remain unchanged then the project maintainers can change the others as required. Importantly, this needs to be governed inside of dbt (using the ref statement) and not in database permissions!
- Allow multiple versions of a model to be consumed at the same time so that downstream models can implement an upgrade path. Publishers of an API give consumers of that API a fairly long period for them to upgrade to the next version—sometimes years! There needs to be similar functionality for creators of dbt models. You can’t just change something and then expect all downstream consumers of your work to update theirs within 24 hours when they get breakage notifications—this is just not a feasible way to build a data practice. The way we’re working here is almost designed to ship buggy code.”
4. Removing silos with joint software/data engineering meetings
Perhaps the best and simplest way to help software engineers from breaking data pipelines is to communicate. For teams that touch production data stores, cross software/data team standups at a regular set cadence can help reduce incidents.
For example, one data leader at a retail organization holds bi-weekly meetings to go through schema changes with both software and data engineering teams as well as SaaS owners.
They explicitly go through every schema change and review if any changes broke anything downstream, and if so, how to mitigate its impact on data quality. While this is a reactive process, it helps break down silos and creates connections for more proactive communication as well.
In a recent blog post on how to handle a schema change, we detailed how Marion Rybnikar, the Senior Director of Data Strategy & Governance for Slice, a data-driven company that empowers over 18,000 independent pizzerias with modern tooling, is an advocate for communicating and properly managing schema changes.
“Schema changes are flagged to us through a channel and we perform an impact analysis on behalf of the business, where we look at upstream and downstream consequences. Then at that point we provide approvals to different parts of the organization or manage subsequent change,” she said.
“For example, if someone is going to make a change that is going to break something, we would project manage to make sure that those changes are all implemented before the next stage occurs.”
5. Data observability and automated lineage
ALL of these approaches for overcoming data quality challenges can benefit from data observability and automated lineage.
One reason is that by reducing the time to detection, data teams can alert and have conversations with their software engineer colleagues much closer to the code change that introduced the breakage.
Not only is that a quicker cognitive jump helpful for determining what went wrong, there are multiple studies that show the quicker feedback is provided after an event the more likely it is to change behavior.
Automated lineage can be a real game-changer as well. As we previously mentioned, one of the biggest challenges software developers face is they have no reference or context for how their actions can impact data assets downstream.
A data observability solution with field-level lineage can allow software developers to add another check to their process. Before committing new code, they can see the fields impacted, reference the data lineage to see how those fields flow into different reports or models and then see who owns those assets all in a single pane of glass. From that point, proactive downstream communication is easy and painless.
Rip the band-aid
If your organization experiences these upstream data quality challenges, I highly encourage you challenge quick fixes and instead, say something to your software engineering counterparts.
There may be many different solutions that are appropriate for your organization, but maintaining the status quo is not one of them. Preventing data incidents will lower your data downtime and increase the levels of data trust and adoption across your organization.
Want to know how data observability can help prevent your data pipelines from breaking? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.





