Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Implementing Data Contracts in the Data Warehouse

Chad Sanderson
Head of Data, Product Manager, Speaker & Early Stage Startup Advisor Focused on Data Innovation @ Convoy

Daniel Dicker
Daniel Dicker is a software engineer at Convoy.
Over the past year, data contracts have taken the data world by storm as a novel approach to ensuring data quality at scale in production services. In this article, Chad Sanderson, Head of Product, Data Platform, at Convoy and creator of Data Quality Camp, introduces a new application of data contracts: in your data warehouse.
In the last couple of posts, I’ve focused on implementing data contracts in production services. (Editors note: not familiar? check out the 4 minute video below).
However, data contracts can be applied anywhere a data product is being produced including the data warehouse! Today, I’m going to talk about how you can implement contracts in the data warehouse and how the implementation, and in some ways the philosophy, differs from what we have previously discussed.
Table of Contents
Where to start implementing data contracts?
The best way to ensure data products can be effectively produced and maintained is to implement data contracts upstream at the service level as well as in the data warehouse. The long dependency chain of data into and through the data warehouse can make taking ownership incredibly difficult. It can be challenging when a team is expected to take full responsibility for a key data product when there are no guarantees around the upstream data quality. Without clear management of each transformation step stretching back to source systems, teams may be unwilling to bear the responsibility of contracts.
That being said, it is often not feasible to implement data contracts everywhere when starting off. When thinking about whether or not the warehouse is the right place to start, there are some advantages and challenges to consider.
Advantages of starting in the warehouse
- Self-contained: starting in the data warehouse doesn’t require the help of application engineers or all data producers. There exists a lot of infrastructure around the data warehouse (tools like dbt, Monte Carlo, Great Expectations, and Apache Airflow) that are already established products and can help to implement contracts. Overall, it requires a smaller culture shift in order to succeed.
- Helps push production service contracts: it is easier to make the case for service-level contracts if you already have the culture and monitoring in place in the data warehouse. Knowing the number of contract failures due to upstream data issues can provide justification for implementing contracts in production services.
Challenges of starting in the warehouse
- Upstream issues: dependencies on data in upstream production services can create a waterfall of data quality issues. Contracts can catch the incoming issues but without being able to address the root cause of issues upstream, it can be very challenging to fully solve the problem.
- Can be painful to go first: the first team to implement contracts will catch a lot of data issues from upstream sources both from production services and from upstream sources in the data warehouse. The initial burden of fielding those issues can be high as you figure out what additional contracts are needed to try to address the root causes.
Requirements for warehouse contracts
To recap, there are six requirements that Adrian laid out for data contracts in my previous post:
- Data contracts must be enforced at the producer level
- Data contracts are public
- Data contracts cover schemas
- Data contracts cover semantics
- Data contracts should not hinder iteration speed for data producers
- Data contracts should not hinder iteration speed for data consumers
All six of these are still relevant for data contracts in the warehouse but there are some key differences with how we’ll want to implement contracts compared to production services.
Data professionals are producers and consumers
The first key difference between production service contracts and contracts within the data warehouse is that data producers and consumers are often both in data roles (analysts, data scientists, data engineers, etc). Fundamentally, the relationship between producers and consumers remains the same: the two groups collaborate to establish a set of contracts, the producers own the data and are responsible for fulfilling the contract, and consumers can expect and use reliable data as defined by the contract. There is, however, an added dimension to this relationship: data producers are often consumers of upstream data sources. Data warehouse producers wear both hats working with upstream producers so they can consume high-quality data and producing high-quality data to provide to their consumers.
Batch in the warehouse
Data warehouses tend to operate in a batch environment rather than using stream processing like we do when moving data from production services. One of the bigger differences between these two types of systems comes in how we think about processing data.
For streaming, we typically process records at an individual level. In production services where data is consistently being produced, we want to process data as it comes in. For batch systems, we process data in… well… batches. The scale of data in warehouses is typically much larger than data coming from production services and processing that larger data in batches tends to be more efficient than operating on individual rows.
Thinking about how we process data for batch and streaming leads to differences in how we think about implementing data contracts especially when it comes to continuous monitoring. For streaming, we can monitor each individual record as it is written and filter out each bad record one-by-one. In batch systems, we tend to check the data in batches which can make it harder to filter out individual records with bad data. That being said, it tends to be much easier to reprocess data in the data warehouse when we do find bad records, whereas that might not be possible in a streaming environment.
Definition of data contracts
Similar to contracts in production services, contracts in the warehouse should be implemented in code and version controlled.
The implementation of contracts can take many forms depending on your data tech stack and can be spread across tools. However, data contracts are abstract, an interface for data that describes schema and semantics, and should not be tied to any one tool or implementation. By taking the time up front to introduce this abstraction, you can use the contract definitions to implement the checks you need today and leave yourself in a good position to change or extend that implementation in the future.
The contracts themselves should be created using well-established protocols for serializing and deserializing structured data such as Google’s Protocol Buffers (protobuf), Apache Avro, or even JSON. The most important reason to choose one over the other? Consistency in your tech stack. All of these options allow you to define the schema of the contract, describe the data, and store relevant metadata like semantics, ownership, and constraints. This is a case where using the same technology you’re already using, or plan on using, for service contracts is far more valuable than the incremental benefits of one choice over the other.
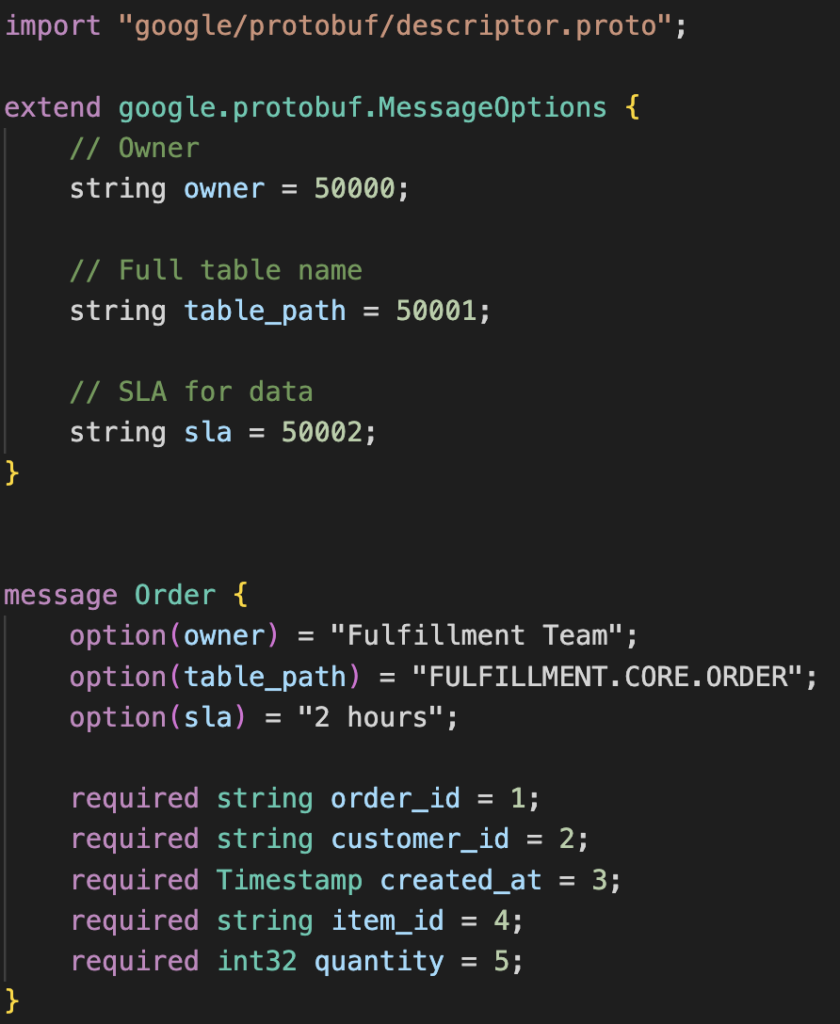
Here is an example of a simple Orders table contract defined using protobuf. We can specify the fields of the contract in addition to metadata like ownership, SLA, and where the table is located.
Proactive enforcement
So much of the work of running a data warehouse is reactive: we often get alerted (if we’re alerted at all) to data quality problems several hours (or days) after changes have been made. With data contracts in the warehouse, we can implement enforcement mechanisms to try to proactively catch and address issues. Specifically, we enforce contracts in two ways: making sure the table/columns can meet the contract in the warehouse and ensuring any changes made to a contract won’t break existing consumers.
Integration tests
We use integration tests to try and verify that the contract will be fulfilled in the data warehouse. Using tools like dbt, we can materialize a table in a dev environment to verify the schema and values of the table adhere to the contract. This is sometimes easier said than done. Depending on the size and complexity of the warehouse, it can be cost-prohibitive or logistically difficult to fully materialize the contract table to do integration testing. In those cases, we try to test on a blank or sample of data.
Schema compatibility
We use the Confluent (Kafka) Schema Registry to store contracts for the data warehouse. Once we’ve run integration tests to verify the contract can be met in the data warehouse, we take the schemas of the tables under contract and use the production schema registry to check for backward incompatible changes. This is very similar to the process for entities and events covered in a previous article.
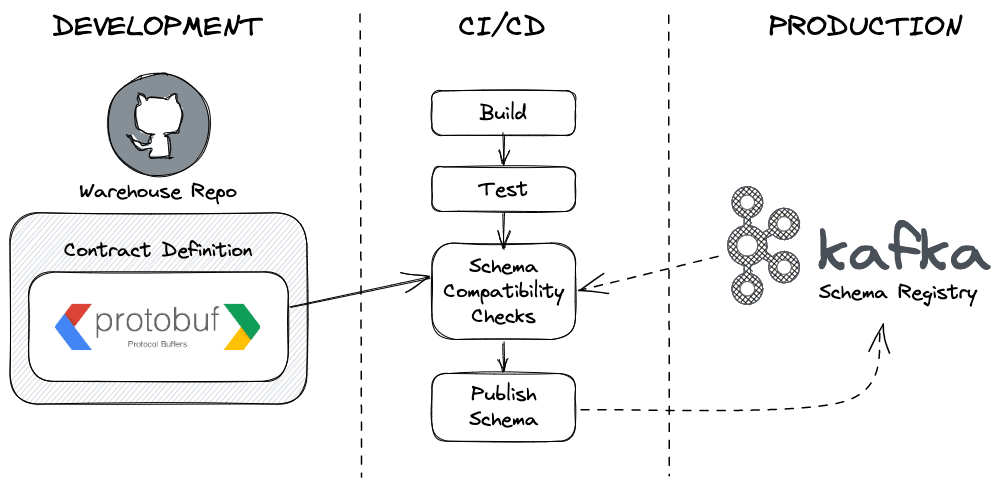
Once the enforcement checks pass, we publish new and updated contracts to the Schema Registry prior to deploying any code.
Continuous monitoring
Like all software engineering, there will inevitably be issues that creep into the data warehouse even with robust testing. We run continuous checks in the warehouse to detect when those issues crop up and can notify the owners to begin resolving the problem. Before we get there though, let’s talk about how we’ve set up our data warehouse.
Data warehouse setup
We define our data warehouse in code using an open-source Python tool called dbt (data build tool). For those unfamiliar with dbt, it allows for the creation of “models” using SQL queries to materialize tables, views, and more within the data warehouse. We version control our dbt models which provides a clear history of how our warehouse has changed over time. Dbt contracts, or explicit expectations for the data, are a good way to ensure data quality and consistency as data moves upstream in a data organization.
One valuable feature of dbt is the ability to create a dependency graph of our data. The graph allows us to ensure that upstream tables are built/updated before the dependent tables that rely on them. We can execute dbt to create these tables in order from the command line but we typically automate the process to keep our warehouse updated on a set schedule.
We use Apache Airflow to orchestrate running dbt at various intervals throughout the day. Apache Airflow is a powerful open-source orchestration tool that enables us to define when our dbt models should run such as every 2 hours or every night at 2 am. Other open source projects such as Prefect and Dagster offer similar functionality. There are plenty of resources available to integrate Airflow and dbt. With a little bit of setup, Airflow can automatically generate the list of dbt models and the order to run them based on their dependencies.
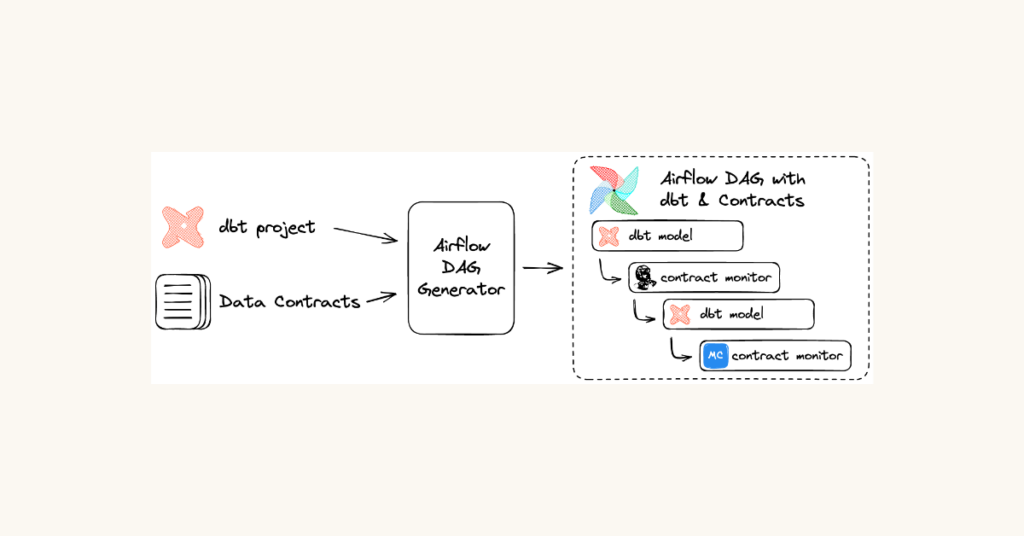
Adding contract monitors to Airflow and dbt
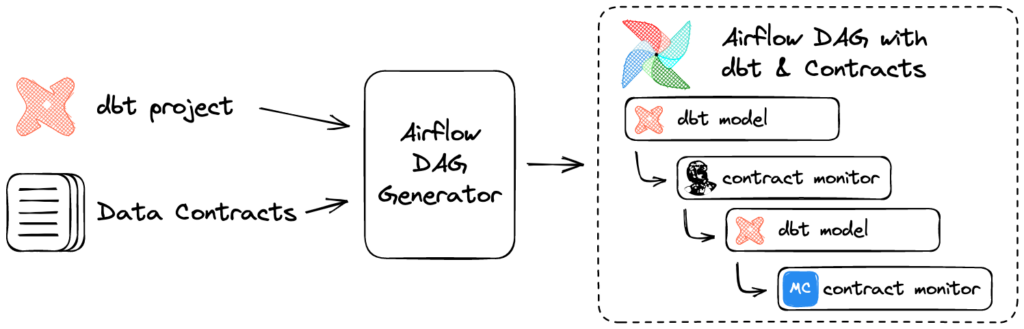
Using dbt and Airflow, we move data through our data warehouse in scheduled batches. When a data contract is created for a specific table, a process reads the contract and generates a corresponding set of monitors. These checks are executed immediately after the data is updated. By checking data before the next transformation can be run, we are able to detect and can stop the propagation of bad data through the rest of the data pipeline.
There are a number of excellent tools in the data ecosystem that we can use to create these monitors. It’s impossible to name them all but here are some that come to mind:
- dbt Tests: built into dbt, this provides a way of testing assertions on your data. They provide common data checks and a way to write custom tests within your dbt project.
- Great Expectations: an open-source Python library that helps users build data validation pipelines. The package comes with a number of data tests and community-built expectations in addition to being able to write custom tests.
- Airflow SQL Operators: there are open-source Airflow Operators that integrate easily with Airflow and can be used to implement quality checks.
- Monte Carlo: a data observability platform that monitors the data in your warehouse across several key pillars, including freshness, volume, schema, and data quality. Once set up, Monte Carlo continuously runs a suite of monitors and additionally has an API that can be used to create contract-specific checks. Alerts about contract breaches can be routed to the appropriate individuals and reporting on contract adherence over time is readily available.
We can use any combination of these tools to do continuous monitoring in the warehouse based on the data contract.
Types of monitors
There are many different types of data quality that we check for when creating contract monitors. These monitors are all based on information in the data contract.
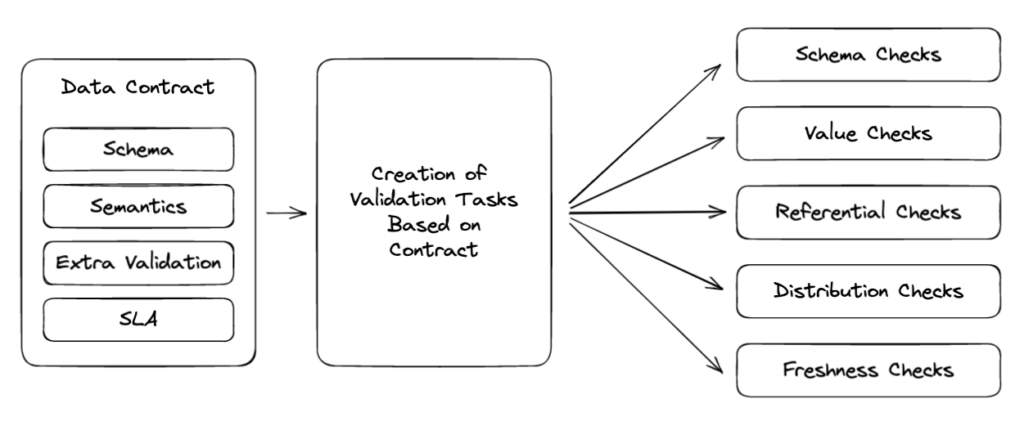
Schema & values
We verify the schema of the data matches the schema in the contract. We validate that all fields in the contract are present in the data and are of the correct data type. We check for compliance with constraints like null values and uniqueness. Additionally, we can validate field values to ensure the values conform to a defined list or adhere to a given numerical range.
Semantic checks
We can perform semantic checks such as validating the referential integrity of the data. These checks ensure the IDs in key columns representing core entities of our business, such as orders, products, or customers, match the corresponding values in source entity tables. For example, we might verify that all the customer IDs in our orders table match the corresponding entries in the customers table. Additionally, we can check the cardinality of these relationships ensuring they match an expected type of relationship such as 1:1 or 1:many.
Distribution checks
In some cases, we monitor the distribution of the data. For example, when predicting prices in a marketplace, we expect prices to fluctuate over time but only within a specific range. Any drastic changes in the distribution of the data could indicate a potential problem requiring further investigation. If we see a 200% increase in prices between yesterday and today, it could indicate an issue that needs to be addressed. Shifts in distributions do not always indicate a problem but having these monitors is helpful when there is an issue.
Freshness
We build in SLAs to our data contracts to denote how often the data should be updated. Separate from our other quality monitors, we periodically check the contract data to see when it was last updated. We often write a last_updated column when data is being added or updated in a table which allows us to detect when a row of data was last changed. If we know that a table should be updated every 2 hours, we can check this last_updated column to make sure that there are changes happening and data is arriving on time.
What happens when we detect bad data?
No matter how rigorous your contracts, bad data will slip through the cracks. Call it a law of physics, or rather, data engineering.
And not all contract failures need to be treated the same. Depending on the needs of your business and the use case for the particular data, you may opt for one approach over another.
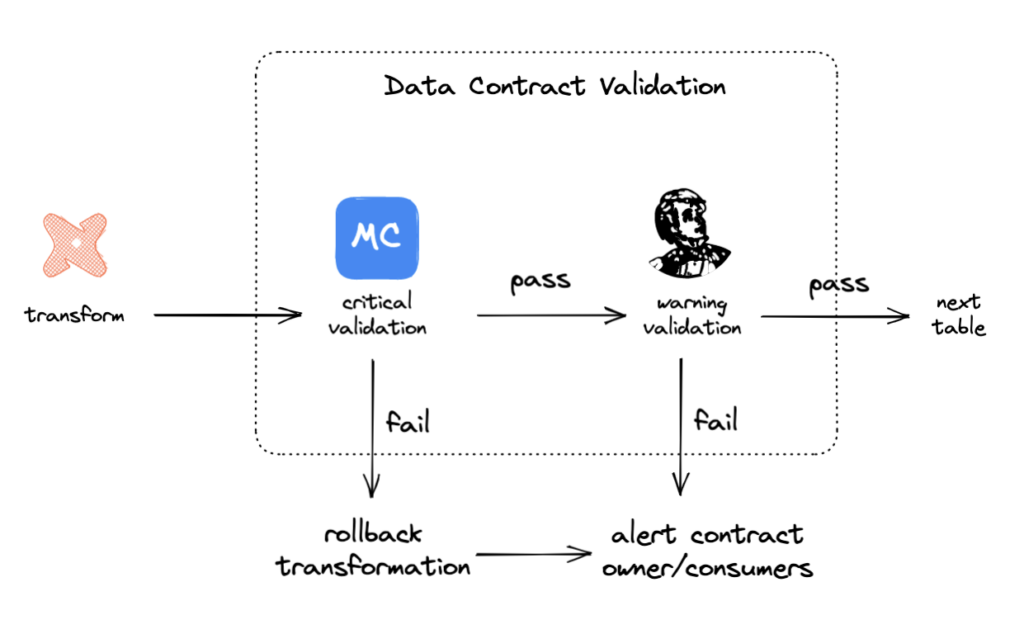
If a contract failure is detected, one option is to immediately roll back the transformation and alert the contract owner. This is called circuit breaking, and can be an effective option if the accuracy of the data is more important than freshness. This option stops the spread of bad data in the warehouse. The tradeoff is that the table won’t have updated data, but such an approach can actually cause delayed jobs to wreak more havoc than they’re preventing.
The second option is to simply alert the contract owner. In cases where the issue may not be critical, data can keep flowing at the cost of potentially problematic data working into the table. Once the owner is alerted, they can investigate and work to fix any issues.
When a data quality issue is detected, it should be viewed as an opportunity for improvement. The data product owner should request an update to the contract for the upstream data source to prevent the issue in the future.
Additionally, data observability solutions provide the tools – such as incident triaging, column-level lineage, and SQL query analysis – to triage and troubleshoot data quality issues in order to more rapidly resolve contract breaches and other data incidents. And if no contract exists on the upstream data, this provides an ideal opportunity to implement one! Having an unbroken chain of contracts on data within the warehouse and from production services is the best way to ensure quality.
Challenge of data contract ownership
Within the data warehouse, ownership over assets can be trickier to nail down compared to production services. It is not always clear who owns a particular table and sometimes ownership is defined at the column, rather than table, level. This can often lead to confusion about who is responsible for maintaining data and more importantly, who is on the hook when something goes wrong.
When first getting started with contracts, it may be necessary to do some digging to determine who the contract owner should be. This can involve talking to team leads or looking at the history of changes made to a particular table or column. We have also found that using data lineage can be very helpful to trace ownership through the warehouse.
Once implemented, data contracts help by assigning explicit ownership to specific tables and columns. The responsibilities of owning teams can be clearly defined along with clear expectations of the data for downstream consumers.
What’s the difference between dbt data contracts and dbt tests?
A dbt model contract is a manually defined schema in YAML, which means you can specify the names and data types of each column. A dbt contract is different from a dbt test in that dbt data contracts run before your model is built to prevent issues, whereas a dbt test runs after your model is built to check for issues.
Final thoughts
Ensuring the quality and trustworthiness of the data in your warehouse is critical for effective analysis and informed business decision-making. Implementing data contracts establishes quality standards and defines ownership for key pieces of data. There are a number of tools available that can be combined and integrated into existing warehouse infrastructure to implement contracts and ensure data reliability at scale no matter where you are in your data platform journey. By implementing data contracts in the warehouse, you can foster a culture of data quality and accountability.
Interested in getting started with data observability for your data platform? Reach out to the Monte Carlo team today.
Our promise: we will show you the product.
Learn more about data contracts by joining Data Quality Camp!
Read more posts.