Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Big Data (Quality), Small Data Team: How Prefect Saved 20 Hours Per Week with Data Observability

Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Data teams spend millions per year tackling the persistent challenges of data downtime. However, it’s often the leanest data teams that feel the sting of poor data quality the most.
Here’s how Prefect, Series B startup and creator of the popular data orchestration tool, harnessed the power of data observability to preserve headcount, improve data quality and reduce time to detection and resolution for data incidents.
Prefect, the company behind the eponymous data workflow management system, is on a mission to make coordinating data flows easier. Pitched as “air traffic control for your data,” Prefect supports the likes of Amazon, Databricks, and Adobe just to name a few. But Prefect isn’t just great with data flows—they’re also experts at managing overhead.
Dylan Hughes, Senior Software Engineer and spiritual data scientist, leads the small-but-mighty data team at Prefect. “One of our philosophies here is that if we have a choice between headcount and tooling, oftentimes we’ll go with the tooling, because we’re trying to direct our headcount towards our customer-facing efforts.”
As a team of just two data professionals (Dylan included), the Prefect data team needed the right data stack to support data reliability without sacrificing headcount and resources.
The challenge: Resource cost of root causing data quality issues and broken pipelines
As a data science and tooling startup, Prefect has data at its core, leveraging analytics to track everything from engagement in their open-source community and feature usage to customer behavior and financials.
“The way that our data flows across our stack is pretty integral to the way the company runs,” said Dylan. “We take the data from our warehouse, and we actually push it back into our operational tooling for use by the individual teams. We’ll take data about users of the cloud platform, and we’ll push it into our email marketing tooling. We’ll take information from our platform, push it into our salesforce instance.”
Like any startup, Prefect has an eye toward scale. But a growing company means growing data needs.
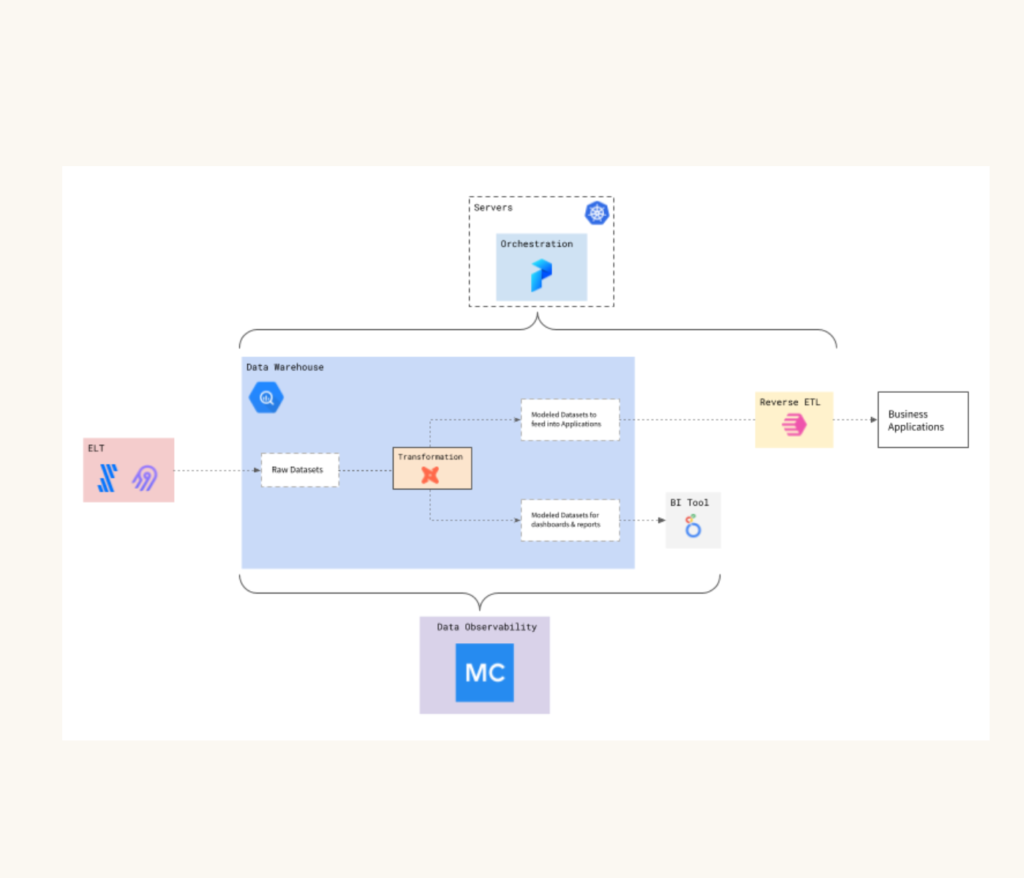
With Prefect leveraging BigQuery for its data warehouse, Fivetran for ETL operations, dbt open source for data modeling, Looker for data exploration and visualization, and their own Prefect flows for internal processes, achieving end-to-end data reliability was no small task. Dylan’s team would lose hours each week tracking schema changes and root causing quality issues—and those were just the quality issues they knew about.
Prefect understood the importance of data quality, but with a team of two data engineers and the needs of a much larger organization, setting up comprehensive data quality coverage was proving to be unattainable. While solutions like dbt tests failed to achieve scalability, alternatives like Google Cloud Platform’s native solutions didn’t appear to be designed for data at all. This left Dylan’s team with a gap to fill.
What Prefect really needed was a data quality solution they could stand up fast to solve multiple data challenges at once—from anomaly reporting to lineage tracking—all the while delivering enough value out of the box to justify the expense to a broader team.
In short, Dylan’s team was looking for data observability.
The solution: end-to-end data observability with Monte Carlo
Dylan’s interest was initially piqued when he learned about Monte Carlo through an early mutual customer of Prefect and Monte Carlo, Braun Reyes at Clearcover. Thanks to Braun’s glowing review and a couple early interactions with Monte Carlo’s team, Dylan saw that what he needed was more than data testing and data quality monitoring—he needed end-to-end data observability. And that’s where Monte Carlo really began to shine.
After some initial cheerleading, Dylan convinced the Prefect team to stand up a Monte Carlo instance for their BigQuery data warehouse. Almost instantly, Monte Carlo’s no-code implementation and out-of-the-box, ML-enabled freshness, volume, and schema checks were providing quick insurance in the health of their data flows and data products.
Immediate time-to-value with automated data quality checks
“What was really exciting to me when we first got set up was just how we flipped this switch, and suddenly we had all kinds of insights into what was happening in our warehouse,” said Dylan.
Monte Carlo’s no-code implementation and pre-built integrations are designed to get teams like Dylan’s up and running faster across their existing stacks at a fraction of the setup time.
Plus Monte Carlo’s API and Python SDK allow for simple extensibility by enabling programmatic access or embedding data observability functions into existing processes and workflows.
“What would have taken the team 6-8 months to stand up on their own was available right out of the box with Monte Carlo,” Dylan added.
Seamless alerting and incident triaging
In addition to out-of-the-box anomaly detection, a quick connection to Prefect’s Slack instance saw Dylan’s team streamlining their incident alerts and triaging processes too.
“The incident alerting directly into Slack and giving the ability to triage straight from there was a game changer. It’s so great that if I add new columns to some of the ingestion tables, [our data analyst] gets alerts from Monte Carlo. It’s like, “Look, here’s this schema change,”” said Dylan.
Deep monitoring for distribution anomalies, like uniqueness and query change analysis
Unlike other data observability solutions, it was clear to Dylan that Monte Carlo was designed for data quality from the ground up. But it’s Monte Carlo’s unique ability to uncover the “unknown unknowns” lurking in your data pipelines that truly epitomizes the value of data observability for small data teams.
Monte Carlo uses machine learning to generate pre-configured data quality rules to validate the data in Prefect’s tables, as well as user-defined monitors to trigger alerts when the data fails specified logic on critical data sets. These data monitors combine to track data accuracy, data completeness and general adherence to internal business rules.
But Monte Carlo doesn’t stop at the “most important” tables. By employing “broad” metadata monitors, Monte Carlo is able to cost-effectively scale across every table in Prefect’s environment, effectively detecting freshness and volume anomalies, as well as anomalies resulting from schema changes at scale.
Considering the impact of Monte Carlo’s deep monitoring on Prefect’s data infrastructure, Dylan said, “The first thing that was really interesting was this idea of your unknown unknowns…this anomalous alerting that would be set up on things that I probably wouldn’t even think to set up alerts on,” said Dylan.
“We have some event driven datasets, and so getting alerts when there haven’t been updates for a certain period of time may indicate something is wrong with a piece of infrastructure…Those alerts are extremely helpful to me.”
Lineage tracking for root cause analysis and anomaly prevention
One feature of data observability that’s become indispensable for Dylan’s team is the ability to do root cause analysis and anomaly prevention through lineage tracking, the process of organizing and visualizing how data flows from sources to end-users, on their dbt and Looker dashboards. “Our data analyst uses Monte Carlo’s lineage almost every day,” Dylan said.
Thanks to comprehensive, field-level lineage, Dylan’s team is free to make bigger changes upstream without having to worry about – or reactively address – the downstream effects, empowering Prefect to solve more problems and make improvements without impacting resource allocation.
“It’s really easy for us to propose and make big changes upstream in the data warehouse and know exactly what is going to be impacted by the change,” said Dylan. “We’re able to explore specific fields and how they move through our data transformation steps—and to see what dashboards are going to be impacted and where they’re going to end up.”
Outcome: 20+ hours saved per week through anomaly detection, automatic root cause analysis, reporting, and lineage tracking
Through ML-powered anomaly detection, automated root cause analysis and reporting and comprehensive lineage tracking, Monte Carlo has driven demonstrable value across Prefect’s data operations and its bottom line.
“Monte Carlo really is a big cornerstone of our data quality at Prefect,” said Dylan.
Alongside the peace of mind implicit in end-to-end data observability, the launch of Prefect’s Monte Carlo instance has delivered:
- 50% engineering time recovered by reducing time to detection, triage, and remediation of data quality issues
- 16x faster time to data quality tooling deployment, reducing time-to-value by 6-8 months when compared to building an MVP data quality solution in-house
- Preserved headcounts for implementation and monitoring, while simultaneously increasing productivity by 20+ hours per week
- Increased capacity for change at warehouse level with end-to-end visibility of pipelines and lineage tracking
Next stop? Scaling data governance.
As Prefect prepares to scale over the coming months, Dylan’s team is looking to data governance as its next big challenge.
“We’ve got some pretty basic stuff going around making sure that we’re only sharing data internally with the folks who need it to do their jobs—that we’re not giving people carte blanche access to data that comes from our product or users.”
As the team sets its sights toward improving Prefect’s data governance practices, they know data quality is one major factor in the equation. Speaking about Monte Carlo, Dylan said, “I’ve been taking the approach that essentially that box has been checked…And so that’s going to be a big win for us as part of that effort.”
Data lineage will also continue to play a key role in Prefect’s future scale.
“We’re going to be leaning heavily on Monte Carlo for a lot of that lineage information to make sure that we’re focusing on the datasets that are used most, and understanding where that data is going. We want to make sure that once everything is classified, the folks who are actually seeing things on the downstream dashboards are the folks that we want based on our classifications,” said Dylan.
Wondering how Monte Carlo could save your data team 20+ hours a week? Reach out to Brandon and the rest of the Monte Carlo team.
And if you want to learn more about Monte Carlo and Prefect’s native integration, check our recent announcement.
Our promise: we will show you the product.
Read more posts.