Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Observability for Developers: Announcing Monte Carlo’s Python SDK

Prateek Chawla
Prateek Chawla is a Founding Principal Engineer and Technical Lead at Monte Carlo.
Our Python SDK gives data engineers programmatic access to Monte Carlo to augment our data observability platform’s lineage, cataloging, and monitoring functionalities.
We are excited to announce the release of Monte Carlo’s Python SDK (Pycarlo), a new way for data engineers to create data applications directly on top of our data observability platform. With the release of Pycarlo, data engineers can conveniently and programmatically integrate data observability into their existing workflows using Python.
Previously, Monte Carlo customers utilized APIs to build on top of our data observability platform. While this worked fine, our customers wanted a streamlined way to integrate Monte Carlo with their data engineering workflow and broader data stack. Now, data engineers can use the Python SDK to more conveniently access all of Monte Carlo’s APIs.
Why we built Pycarlo
Monte Carlo’s SDK comprises two components; core and features. The core version allows you to do everything our API can but enables more seamless integration with your existing data engineering workflows. Our features library takes the SDK one step further by providing additional convenience for performing operations like combining queries, polling, paging, and much more. In addition, the features component is the foundation for some of our most popular integrations and services like our command line interface (CLI) and dbt integration.
With the Monte Carlo SDK, data engineers and scientists can leverage Python in addition to SQL to update settings, pull events to create custom dashboards, glean operational insights, trigger rules, and configure more advanced monitors, among other use cases normally handled by our API. The release of Pycarlo immediately extends the impact and coverage of data observability for our customers, who can now easily aggregate metadata and update logic and monitors across tables in bulk.
What does Pycarlo support?
To get started using Pycarlo, an API key is required.
All Monte Carlo API queries and mutations that you could execute via the API are supported via the core library. Operations can be executed as first-class objects, using sgqlc, or as raw GQL with variables. In both cases a consistent (i.e. native) object where fields can be referenced by dot notation and the more pythonic snake_case is returned for ease of use.
You can also create multiple sessions and fully manage connections and requests from existing configurations. Sessions support the following parameters:
- mcd_id: API Key ID.
- mcd_token: API secret.
- mcd_profile: Named profile containing credentials. This is created via the CLI ( e.g. montecarlo configure –profile-name zeus).
- mcd_config_path: Path to file containing credentials. Defaults to ~/.mcd/.
When you create a session any mcd_id and mcd_token params that are explicitly passed will take precedence, followed by environment variables (MCD_DEFAULT_API_ID and MCD_DEFAULT_API_TOKEN) and then any configuration files options. It is a best practice to not pass mcd_token since it is a secret and can accidentally be committed by an engineer to your public repository.
Developers also have the option to define the following values in their Monte Carlo environment:
- MCD_VERBOSE_ERRORS: This enables logging, and includes a trace ID for each session and request. Allowing customers to better track the origin and usage of requests downstream for debugging.
- MCD_API_ENDPOINT: Allows developers to customize the endpoint where queries and mutations are executed.
How customers are using Pycarlo?
Customers like Clearcover and Assurance are already seeing tremendous value from our SDK, further integrating with their root cause analysis and incident management workflows.
Common applications of Pycarlo include:
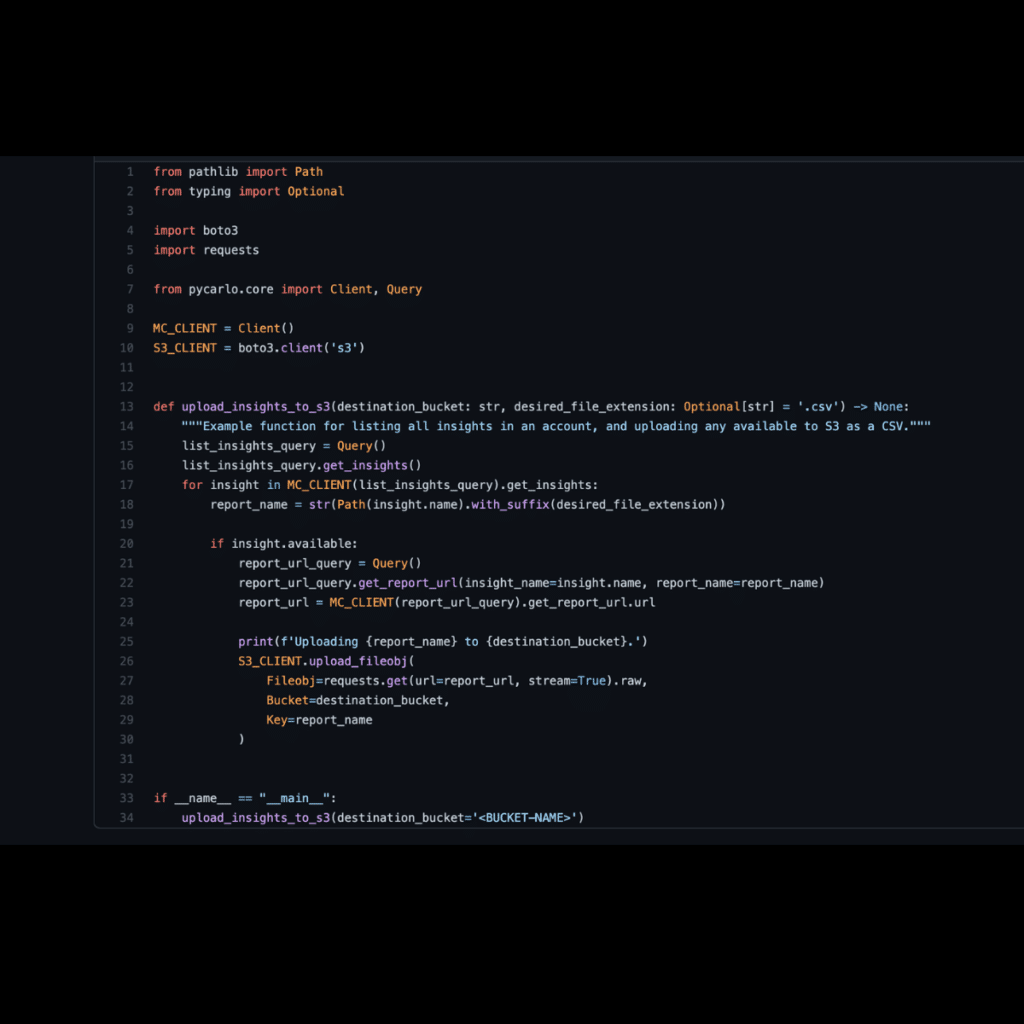
- Augmenting lineage: Data teams can leverage our SDK to add nodes and edges to upstream and downstream data assets beyond the scope of Monte Carlo’s warehouse, lake, ETL, and business intelligence lineage. With a single line of code, data engineers can add coverage for Airflow jobs, external tables, S3 buckets, Salesforce applications, HubSpot reports, internally built reports, and other endpoints.
- Downstream reporting beyond the business intelligence layer. Our SDK makes it easy for engineers and analysts to generate and share downstream reports built off of our specific tables for distribution in email, Slack, Teams, and other communication channels.
- Aggregating metadata. Pycarlo can create a central repository of all metadata collected from disparate tools across your data stack, including logs, queries, dbt models and Airflow jobs. Now, engineers can add tags in bulk to many different tables in the Monte Carlo Catalog, creating a single source of truth across a wide variety of tools.
- Programmatically spin up custom data observability monitors. With our SDK, teams can generate the deployment of new custom monitors in bulk, managing all monitoring needs directly within their CI/CD pipeline to easily handle monitoring at scale.
Getting started with Pycarlo
Learn how to use Pycarlo or read up on additional new cases by checking out our docs.
Pycarlo will act as the foundation for all programmatic applications of Monte Carlo moving forward, further signaling our commitment to our users and the broader data community as we continue to pave the way forward for data observability no matter which tools are in your stack.
Interested in learning more about Monte Carlo’s Python SDK? Reach out to Prateek and book a demo using the form below.
Our promise: we will show you the product.
Read more posts.