Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Top Data Quality Alert Strategies From 3 Real Data Teams


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Can you ever have too much of a good thing?
When it comes to sweet treats, sunshine, and errant data quality alerts, the answer is – unfortunately – yes.
But, while an ice cream-induced stomach ache or an uncomfortable sunburn will subside relatively quickly, the burnout that results from an overflow of data quality alerts can have far more lasting repercussions throughout your data organization.
Alerts for data quality incidents, like anomalies in the freshness, volume, or schema of your tables, are essential for maintaining the health and accuracy of the data flowing through your pipelines.
However, when your data quality alerts aren’t optimized, it’s easy for a data team to go from feeling like the captains of their data ship to feeling like they’re drowning in a sea of low-impact Slack pings.
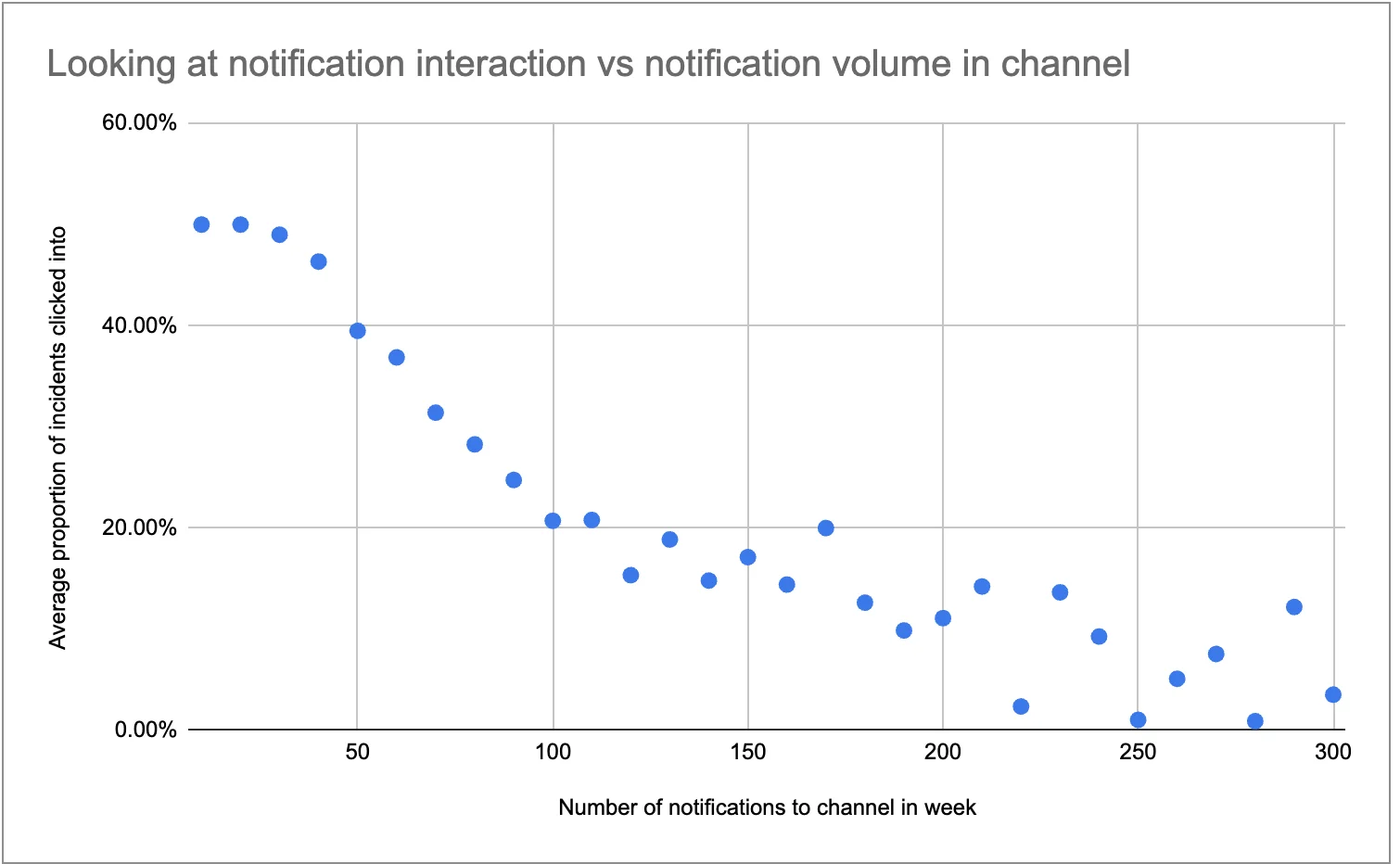
That’s why an internal incident management strategy is so important – in fact, it’s just as essential as a data observability solution that can effectively surface those data quality issues in the first place.
A comprehensive data observability solution will have the functionality to programmatically detect and alert your team about relevant data anomalies, along with providing the necessary resolution resources like data lineage to help you triage, root-cause, and resolve those issues quickly.
But no tool—however impressive—will ever be effective without the right plan in place for how to use it.
So, what do effective data quality alert strategies look like in action? We looked to the data teams at Seasoned, Jetblue, and Aircall to share how they handle data incidents at scale to reduce alert fatigue and improve their time to resolution in one fell swoop.
Table of Contents
Seasoned decentralizes incident management but maintains one clear set of expectations
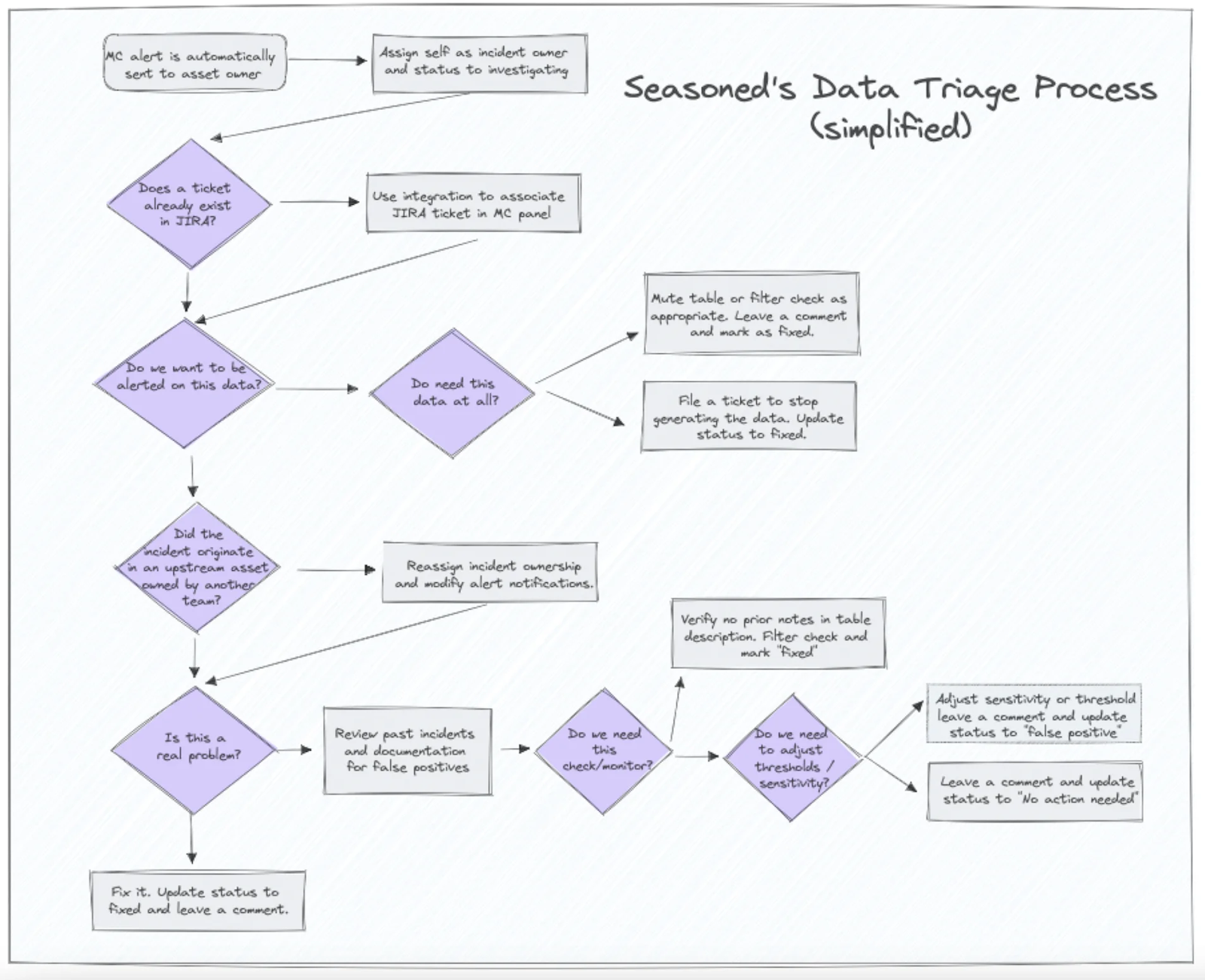
When service industry job board and hiring app Seasoned ran into a data issue that broke a pipeline in two places, Sean McAfee, Senior Ops Engineer, realized it wasn’t just the pipeline that had broken – both the triage and alert notification workflows were bad as well.
So, he set out to refresh the team’s incident management process – relying on four alert strategy best practices to guide the project:
- Clear and distributed data asset (table) ownership
- Make data producers part of the data triage team
- Be specific on ticket, status, and documentation expectations
- Consider every alert an opportunity to re-evaluate your data triage process
Decentralizing the incident management process helped to disperse responsibility between each domain and ensured that their data products remained covered from end-to-end. Across domains, data analysts would serve as the first responders.
The Seasoned team leverages Notifications 2.0, Monte Carlo’s framework for notifications that makes it easy to send the right alerts to a team’s preferred communication channel, including Slack, Microsoft Teams, Email, PagerDuty, Webex, OpsGenie, Jira, ServiceNow, and webhooks. For Seasoned, this means notification alerts via Slack.
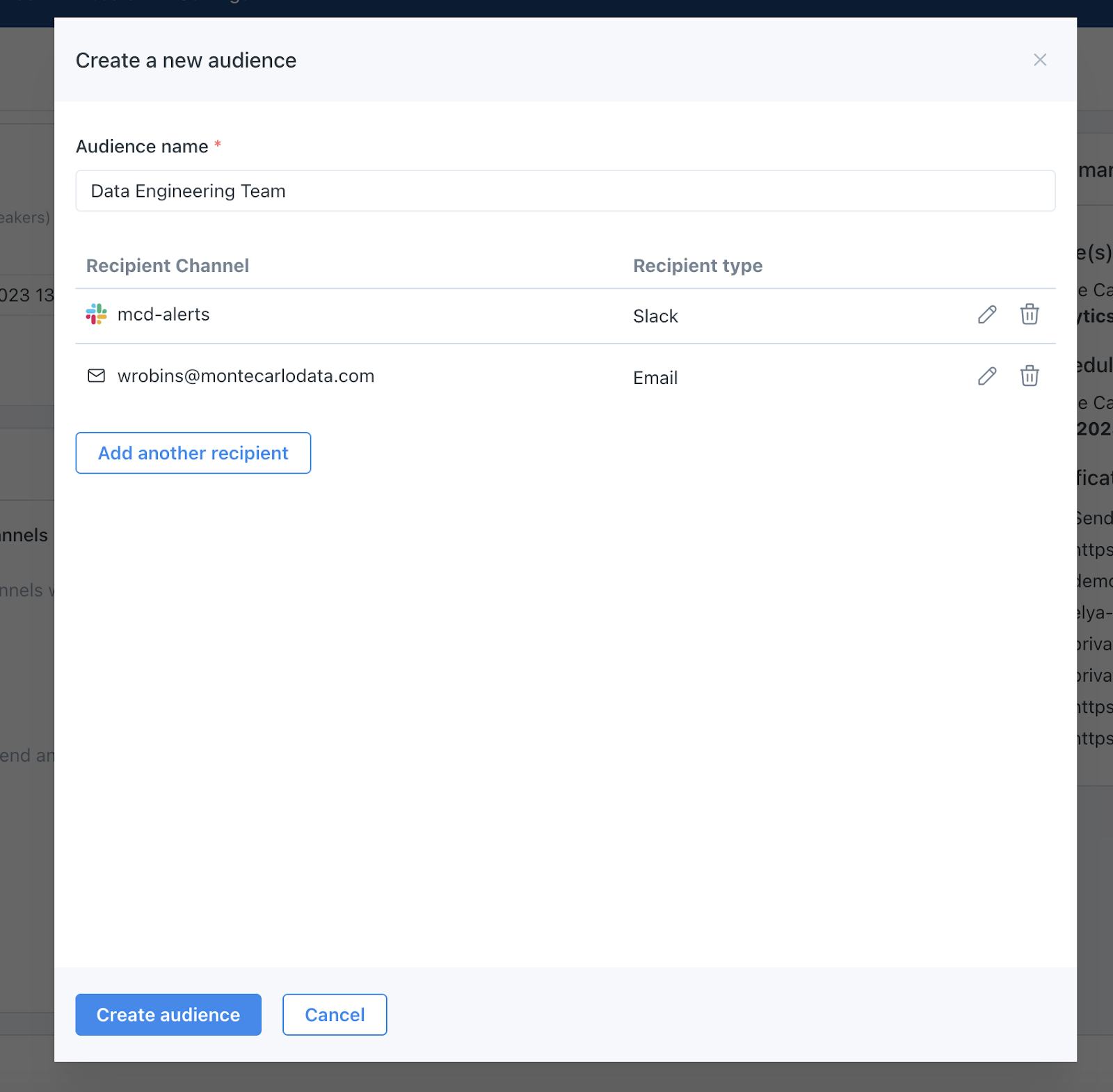
“Before Notifications 2.0 you had to know how different teams wanted to be alerted and tagging structures could get complex,” said Sean. “Now it’s a much easier process to create an Audience and have those users evolve how and to what they want to be alerted on over time.”
In addition, Sean clearly lays out when the responder needs to do their due diligence in terms of documentation. “We are aggressively ensuring that all incidents receive a disposition,” said Sean. “Today that involves setting Slack reminders to check the incident list.”
Sean has also specifically identified when and where documentation should be reviewed or added within the Monte Carlo platform as an incident’s root cause is being investigated. The team doesn’t just create documentation describing the incident, but also the context for the current status or any adjustments to the monitoring configuration.
For Sean and the Seasoned team, data observability helps to ensure their data platform is a living and evolving tool.
“Every single alert should force us to ask questions,” says Sean. “We want to cultivate a living-and-evolving data observability deployment that uses continuous improvement techniques to provide a consistent experience, improve notification accuracy, create distributed accountability, and increase engagement across each group within the data team.
JetBlue operationalizes data observability into data engineering workflows to expedite RCA
For JetBlue Airlines, which provides over one thousand flights per day, it’s essential that every piece of data, from flight information to customer flight data and everything in between, is (like its planes) accurate, on-time, and reliable.
When Jetblue migrated to Snowflake, they also took the opportunity to optimize their data incident management strategy by leveraging Monte Carlo’s automated monitoring. This helped the team scale their alert strategy, making sure it was not only efficient, but also manageable for their data engineering team.
“An observability product without an operational process to back it is like having a phone line for 911 without any operators to receive the calls,” says Ashley Van Name, JetBlue’s Senior Manager of Data Engineering.
Jetblue’s alert strategy runs on three core principles:
- Receive an alert
- Review the alert
- Act on the alert
Pretty simple, right? But scale these principles up to support thousands of alerts, and executing this workflow can look a little more complex. So, how does Jetblue’s triage and resolution strategy work in practice?
They leverage a Microsoft Teams channel, where all of its data engineers and data operations engineers subscribe to Monte Carlo alerts. Then, the DataOps team is primarily responsible for investigating those alerts and resolving incidents.
“Before we onboarded Monte Carlo, the data operations team’s primary focus was to just monitor pipeline runs that failed,” Ashley said. “But now, they’ve got this extra level of insight where they are able to say ‘something is wrong with this table’ rather than just ‘something is wrong with this pipeline.’ And, in some cases, we see that the pipeline works fine and everything is healthy, but the data in the table itself is incorrect. Monte Carlo helps us see these issues, which we did not previously have a way to easily visualize.”
Now, the team measures the success of their data observability initiative via several metrics, including the number of incidents classified and the time to their resolution.
So, is their alert strategy working? Yes, in a big way. Jetblue now has one of the highest incident status update percentages – and it’s the cross-team collaboration and buy-in from engineering leadership that makes a big difference.
Aircall sets up alert domains to ensure clear incident ownership across data owners
Customer communications and intelligence platform Aircall’s data team is divided into two lines of ownership: one team handles all internal-facing data, while a broader team handles customer-facing analytics and AI features.
The internal team is then broken into verticalized domains: Product Analytics, Customer Analytics, GTM analytics, and Data Engineering – and their alert strategy is broken up accordingly.
Alert notifications are broken into domains to match the team’s verticalization, so each team only receives alerts related to their specific scope.
“This allows for a clear ownership of incidents,” says Tanguy d’Hérouville, Lead Data Engineer at Aircall. “They are assigned to people who know the pipelines the best and are able to quickly understand the business impact of an incident to determine how they need to prioritize it.”
The analysts are in charge of the entirety of their data pipelines, from ingestion with Fivetran or Rudderstack to transformations in dbt to reporting in Looker. With Monte Carlo’s automated monitoring and alerting by domain, the analysts closest to the data are alerted when an issue occurs. This enables proactive and swift incident resolution.
With this strategy in place, the data teams can detect issues sooner and use data lineage to identify downstream consumers and impact. Rather than rely on dbt tests, the team has automated alerting set in place, and custom monitors that alert responsible stakeholders to issues that arise in the highest priority data assets, like their NPS metric.
“Our stakeholders learning about an issue with data from us, rather than finding out by themselves, helps increase their data trust,” says Tanguy. “We can show that even though incidents do happen, we are more aware and in control of the situation than we once were.”
Reducing alert fatigue starts with being proactive
Data quality alerts can get annoying. No doubt. But given the choice, most teams would still rather receive that alert and go through the triage process to resolve it—than receive a ping from their stakeholders asking why their data looks wrong and erode a little more data trust in the process.
Alert fatigue can result from several factors: excessive coverage scope, dead-end alerts, diffused responsibility, poor routing, and more. But, just as the teams above so expertly demonstrated, there are also a few best practices to keep those notifications in check and improve your resolution rates in the process.
When defining an effective data quality alert strategy, consider these four steps:
- Start with alerts on only your most important data products and cover them end-to-end
- Leverage a data observability solution that provides data lineage, so you can accelerate root cause analysis into your data, system, and code levels
- Be diligent in tracking and updating the statuses and documentation of data quality incidents to improve transparency and accountability
- Build a notification strategy that only sends alerts to specific communication channels for specific owners to prevent overwhelming notifications
An effective data observability solution, like Monte Carlo, can help data teams proactively manage data quality alerts, reducing alert fatigue, crush data downtime, and drastically improve data trust in the process.
Want to learn more about how Monte Carlo can improve your incident management process? Chat with our team.
Our promise: we will show you the product.
Read more posts.